Chapter 1. Foundational Techniques
Simplicity is prerequisite for reliability.
âEdsger W. Dijkstra
Since its initial release in July 2004, the Ruby on Rails web framework has been steadily growing in popularity. Rails has been converting PHP, Java, and .NET developers to a simpler way: a model-view-controller (MVC) architecture, sensible defaults (âconvention over configurationâ), and the powerful Ruby programming language.
Rails had somewhat of a bad reputation for a lack of documentation during its first year or two. This gap has since been filled by the thousands of developers who use, contribute to, and write about Ruby on Rails, as well as by the Rails Documentation project (http://railsdocumentation.org/). There are hundreds of blogs that offer tutorials and advice for Rails development.
This bookâs goal is to collect and distill the best practices and knowledge embodied by the community of Rails developers and present everything in an easy-to-understand, compact format for experienced programmers. In addition, I seek to present facets of web development that are often undertreated or dismissed by the Rails community.
What Is Metaprogramming?
Rails brought metaprogramming to the masses. Although it was certainly not the first application to use Rubyâs extensive facilities for introspection, it is probably the most popular. To understand Rails, we must first examine the parts of Ruby that make Rails possible. This chapter lays the foundation for the techniques discussed in the remainder of this book.
Metaprogramming is a programming technique in which code writes other code or introspects upon itself. The prefix meta-(from Greek) refers to abstraction; code that uses metaprogramming techniques works at two levels of abstraction simultaneously.
Metaprogramming is used in many languages, but it is most popular in dynamic languages because they typically have more runtime capabilities for manipulating code as data. Though reflection is available in more static languages such as C# and Java, it is not nearly as transparent as in the more dynamic languages such as Ruby because the code and data are on two separate levels at runtime.
Introspection is typically done on one of two levels. Syntactic introspection is the lowest level of introspectionâdirect examination of the program text or token stream. Template-based and macro based metaprogramming usually operate at the syntactic level.
Lisp encourages this style of metaprogramming by using S-expressions (essentially a direct translation of the programâs abstract syntax tree) for both code and data. Metaprogramming in Lisp heavily involves macros, which are essentially templates for code. This offers the advantage of working on one level; code and data are both represented in the same way, and the only thing that distinguishes code from data is whether it is evaluated. However, there are some drawbacks to metaprogramming at the syntactic level. Variable capture and inadvertent multiple evaluation are direct consequences of having code on two levels of abstraction in the source evaluated in the same namespace. Although there are standard Lisp idioms for dealing with these problems, they represent more things the Lisp programmer must learn and think about.
Syntactic introspection for Ruby is available through the
ParseTree library, which translates Ruby source into S-expressions.
[1] An interesting application of this library is Heckle,
[2] a test-testing framework that parses Ruby source code and
mutates it, changing strings and flipping true to false and vice versa. The idea is that if you
have good test coverage, any mutation of your code should cause your
unit tests to fail.
The higher-level alternative to syntactic introspection is semantic introspection,or examination of a program through the languageâs higher-level data structures. Exactly how this looks differs between languages, but in Ruby it generally means working at the class and method level: creating, rewriting, and aliasing methods; intercepting method calls; and manipulating the inheritance chain. These techniques are usually more orthogonal to existing code than syntactic methods, because they tend to treat existing methods as black boxes rather than poking around inside their implementations.
Donât Repeat Yourself
At a high level, metaprogramming is useful in working toward the DRY principle (Donât Repeat Yourself). Also referred to as âOnce and Only Once,â the DRY principle dictates that you should only need to express a particular piece of information once in a system. Duplication is usually unnecessary, especially in dynamic languages like Ruby. Just as functional abstraction allows us to avoid duplicating code that is the same or nearly the same, metaprogramming allows us to avoid duplicating similar concepts when they recur throughout an application.
Metaprogramming is primarily about simplicity. One of the easiest ways to get a feel for metaprogramming is to look for repeated code and factor it out. Redundant code can be factored into functions; redundant functions or patterns can often be factored out through the use of metaprogramming.
Tip
Design patterns cover overlapping territory here; patterns are designed to minimize the number of times you have to solve the same problem. In the Ruby community, design patterns have acquired something of a negative reputation. To some developers, patterns are a common vocabulary for describing solutions to recurring problems. To others, they are overengineered.
To be sure, patterns can be overapplied. However, this need not be the case if they are used judiciously. Design patterns are only useful insofar as they reduce cognitive complexity. In Ruby, some of the fine-grained patterns are so transparent that it would be counterintuitive to call them âpatternsâ; they are really idioms, and most programmers who âthink in Rubyâ use them without thinking. Patterns should be thought of as a vocabulary for describing architecture, not as a library of prepackaged implementation solutions. Good Ruby design patterns are vastly different from good C++ design patterns in this regard.
In general, metaprogramming should not be used simply to repeat code. You should always evaluate the options to see if another technique, such as functional abstraction, would better suit the problem. However, in a few cases, repeating code via metaprogramming is the best way to solve a problem. For example, when several very similar methods must be defined on an object, as in ActiveRecord helper methods, metaprogramming can be used.
Caveats
Code that rewrites itself can be very hard to write and maintain. The programming devices you choose should always serve your needsâthey should make your life easier, not more difficult. The techniques illustrated here should be more tools in your toolbox, not the only tools.
Bottom-Up Programming
Bottom-up programming is a concept borrowed from the Lisp world. The primary concept in bottom-up programming is building abstractions from the lowest level. By writing the lowest-level constructs first, you are essentially building your program on top of those abstractions. In a sense, you are writing a domain-specific language in which you build your programs.
This concept is extremely useful in ActiveRecord. After creating your basic schema and model objects, you can begin to build abstractions on top of those objects. Many Rails projects start out by building abstractions on the model like this, before writing a single line of controller code or even designing the web interface:
class Order < ActiveRecord::Base has_many :line_items def total subtotal + shipping + tax end def subtotal line_items.sum(:price) end def shipping shipping_base_price + line_items.sum(:shipping) end def tax subtotal * TAX_RATE end end
Ruby Foundations
This book relies heavily on a firm understanding of Ruby. This section will explain some aspects of Ruby that are often confusing or misunderstood. Some of this may be familiar, but these are important concepts that form the basis for the metaprogramming techniques covered later in this chapter.
Classes and Modules
Classes and modules are the foundation of object-oriented programming in Ruby. Classes facilitate encapsulation and separation of concerns. Modules can be used as mixinsâbundles of functionality that are added onto a class to add behaviors in lieu of multiple inheritance. Modules are also used to separate classes into namespaces.
In Ruby, every class name is a constant. This is why Ruby
requires class names to begin with an uppercase letter. The constant
evaluates to the class object, which is an object
of the class Class. This is
distinct from the Class object, which represents
the actual class Class. [3] When we refer to a âclass objectâ (with a lowercase C),
we mean any object that represents a class (including Class itself). When we refer to the âClass
objectâ (uppercase C), we mean the class Class, which is the superclass of all class
objects.
The class Class inherits from
Module; every class is also a
module. However, there is an important distinction. Classes cannot be
mixed in to other classes, and classes cannot extend objects; only
modules can.
Method Lookup
Method lookup in Ruby can be very confusing, but it is quite regular. The easiest way to understand complicated situations is to visualize the data structures that Ruby creates behind the scenes.
Every Ruby object[4] has a set of fields in memory:
klassA pointer to the class object of this object. (It is
klassinstead ofclassbecause the latter is a reserved word in C++ and Ruby; if it were calledclass, Ruby would compile with a C compiler but not with a C++ compiler. This deliberate misspelling is used everywhere in Ruby.)iv_tblâInstance Variable Table,â a hashtable containing the instance variables belonging to this object.
flagsA bitfield of Boolean flags with some status information, such as the objectâs taint status, garbage collection mark bit, and whether the object is frozen.
Every Ruby class or module has the same fields, plus two more:
m_tblâMethod Table,â a hashtable of this class or moduleâs instance methods.
superA pointer to this class or moduleâs superclass.
These fields play a huge role in method lookup, and it is
important that you understand them. In particular, you should pay
close attention to the difference between the klass and super pointers of a class object.
The rules
The method lookup rules are very simple, but they depend on an understanding of how Rubyâs data structures work. When a message is sent to an object, [5] the following steps occur:
Ruby follows the receiverâs
klasspointer and searches them_tblof that class object for a matching method. (The target of aklasspointer will always be a class object.)If no method is found, Ruby follows that class objectâs
superpointer and continues the search in the superclassâsm_tbl.Ruby progresses in this manner until the method is found or the top of the
superchain is reached.If the method is not found in any object on the chain, Ruby invokes
method_ missingon the receiver of the original method. This starts the process over again, this time looking formethod_missingrather than the original method.
These rules apply universally. All of the interesting things
that method lookup involves (mixins, class methods, and singleton
classes) are consequences of the structure of the klass and super pointers. We will now examine this
process in detail.
Class inheritance
The method lookup process can be confusing, so weâll start simple. Here is the simplest possible class definition in Ruby:
class A end
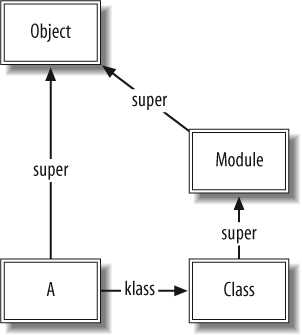
This code generates the following data structures in memory (see Figure 1-1).
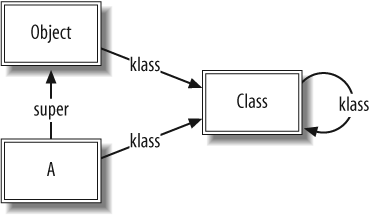
The double-bordered boxes represent class objectsâobjects
whose klass pointer points to the
Class object. Aâs super pointer refers to the Object class object, indicating that
A inherits from Object. For clarity, from now on we will
omit default klass pointers to
Class, Module, and Object where there is no ambiguity.
The next-simplest case is inheritance from one class. Class
inheritance simply follows the super pointers. For example, we will
create a B class that descends
from A:
class B < A end
The resulting data structures are shown in Figure 1-2.
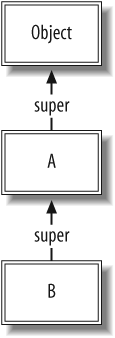
The super keyword always
delegates along the method lookup chain, as in the following
example:
class B def initialize logger.info "Creating B object" super end end
The call to super in
initialize will follow the
standard method lookup chain, beginning with A#initialize.
Class instantiation
Now we get a chance to see how method lookup is performed. We
first create an instance of class B:
obj = B.new
This creates a new object, and sets its klass pointer to Bâs class object (see Figure 1-3).
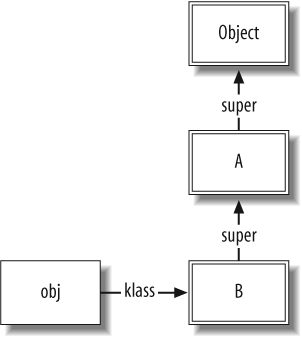
The single-bordered box around obj represents a plain-old object
instance. Note that each box in this diagram is an object instance.
However, the double-bordered boxes represent objects that are
instances of the Class class
(hence their klass pointer points
to the Class object).
When we send obj a
message:
obj.to_s
this chain is followed:
obj's klasspointer is followed toB; Bâs methods (inm_tbl) are searched for a matching method.No methods are found in
B. Bâssuperpointer is followed, andAis searched for methods.No methods are found in
A. Aâssuperpointer is followed, andObjectis searched for methods.The
Objectclass contains ato_smethod in native code (rb_any_to_s). This is invoked, yielding a value like "#<B:0x1cd3c0>â. Therb_any_to_smethod examines the receiverâsklasspointer to determine what class name to display; therefore,Bis shown even though the method invoked resides inObject.
Including modules
Things get more complicated when we start mixing in modules.
Ruby handles module inclusion with ICLASSes,[6] which are proxies for modules. When you include a
module into a class, Ruby inserts an ICLASS representing the
included module into the including class objectâs super chain.
For our module inclusion example, letâs simplify things a bit
by ignoring B for now. We define
a module and mix it in to A,
which results in data structures shown in Figure 1-4:
module Mixin def mixed_method puts "Hello from mixin" end end class A include Mixin end
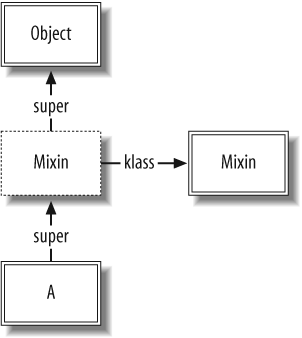
Here is where the ICLASS comes into play. The super link pointing from A to Object is intercepted by a new ICLASS
(represented by the box with the dashed line). The ICLASS is a proxy
for the Mixin module. It contains
pointers to Mixinâs iv_tbl (instance variables) and m_tbl (methods).
From this diagram, it is easy to see why we need proxy
classes: the same module may be mixed in to any number of different
classesâclasses that may inherit from different classes (thus having
different super pointers). We
could not directly insert Mixin
into the lookup chain, because its super pointer would have to point to two
different things if it were mixed in to two classes with different
parents.
When we instantiate A, the
structures are as shown in Figure 1-5:
objA = A.new
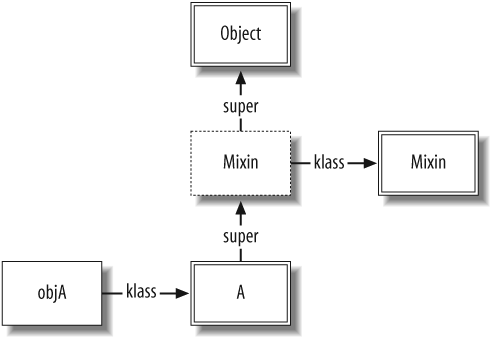
We invoke the mixed_method
method from the mixin, with objA
as the receiver:
objA.mixed_method # >> Hello from mixin
The following method-lookup process takes place:
objAâs class,A, is searched for a matching method. None is found.Aâssuperpointer is followed to the ICLASS that proxiesMixin. This proxy object is searched for a matching method. Because the proxyâsm_tblis the same asMixinâsm_tbl, themixed_methodmethod is found and invoked.
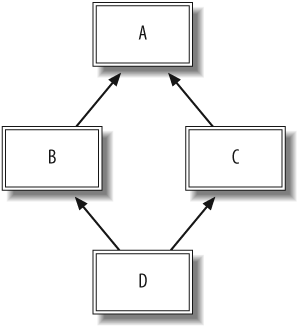
Many languages with multiple inheritance suffer from the diamond problem, which is ambiguity in resolving method calls on objects whose classes have a diamond-shaped inheritance graph, as shown in Figure 1-6.
Given this diagram, if an object of class D calls a method defined in class A that has been overridden in both
B and C, there is ambiguity about which method
should be called. Ruby resolves this by linearizing the order of
inclusion. Upon a method call, the lookup chain is
searched linearly, including any ICLASSes that have been inserted
into the chain.
First of all, Ruby does not support multiple inheritance;
however, multiple modules can be mixed into classes and other
modules. Therefore, A, B, and
C must be modules. We see that
there is no ambiguity here; the method chosen is the latest one that
was inserted into the lookup chain:
module A def hello "Hello from A" end end
module B include A def hello "Hello from B" end end module C include A def hello "Hello from C" end end class D include B include C end D.new.hello # => "Hello from C"
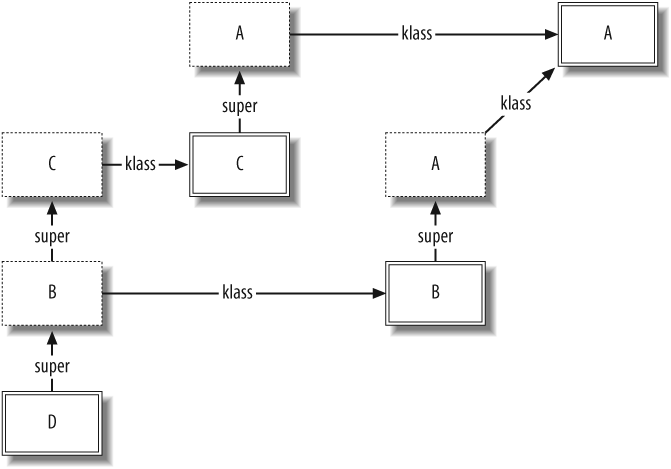
And if we change the order of inclusion, the result changes correspondingly:
class D include C include B end D.new.hello # => "Hello from B"
In this last example, where B is included last, the object graph looks
like Figure 1-7
(for simplicity, pointers to Object and Class have been elided).
The singleton class
Singleton classes (also metaclasses or eigenclasses; see the upcoming sidebar, âSingle-ton Class Terminologyâ) allow an objectâs behavior to be different from that of other objects of its class. Youâve probably seen the notation to open up a singleton class before:
class A end objA = A.new objB = A.new objA.to_s # => "#<A:0x1cd0a0>" objB.to_s # => "#<A:0x1c4e28>" class <<objA # Open the singleton class of objA def to_s; "Object A"; end end objA.to_s # => "Object A" objB.to_s # => "#<A:0x1c4e28>"
The class <<objA
notation opens objAâs singleton
class. Instance methods added to the singleton class function as
instance methods in the lookup chain. The resulting data structures are shown
in Figure 1-8.
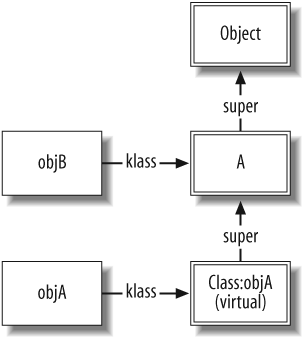
The objB instance is of
class A, as usual. And if you ask
Ruby, it will tell you that objA
is also of class A:
objA.class # => A
However, something different is going on behind the scenes.
Another class object has been inserted into the lookup chain. This object is the singleton class of
objA.We refer to it as "Class:objA" in this documentation. Ruby
calls it a similar name: #<Class:#<A:0x1cd0a0>>. Like
all classes, the singleton classâs klass pointer (not shown) points to the
Class object.
The singleton class is marked as a virtual
class (one of the flags is used to indicate that a class is
virtual). Virtual classes cannot be instantiated, and we
generally do not see them from Ruby unless we take pains to do so.
When we ask Ruby for objAâs
class, it traverses the klass and
super pointers up the hierarchy
until it finds the first nonvirtual class.
Therefore, it tells us that objAâs class is A. This is important to remember: an objectâs
class (from Rubyâs perspective) may not match the object pointed to
by klass.
Singleton classes are called singleton for a reason: there can only be one
singleton class per object. Therefore, we can refer unambiguously to
"objAâs singleton classâ or
Class:objA. In our code, we can
assume that the singleton class exists; in reality, for efficiency,
Ruby creates it only when we first mention it.
Ruby allows singleton classes to be defined on any object
except Fixnums or symbols.
Fixnums and symbols are
immediate values (for efficiency, theyâre
stored as themselves in memory, rather than as a pointer to a data
structure). Because theyâre stored on their own, they donât have
klass pointers, so thereâs no way
to alter their method lookup chain.
You can open singleton classes for true, false, and nil, but the singleton class returned will
be the same as the objectâs class. These values are singleton
instances (the only instances) of TrueClass, FalseClass, and NilClass, respectively. When you ask for
the singleton class of true, you
will get TrueClass, as the
immediate value true is the only possible instance of that class. In
Ruby:
true.class # => TrueClass class << true; self; end # => TrueClass true.class == (class << true; self; end) # => true
Singleton classes of class objects
Here is where it gets complicated. Keep in mind the basic rule
of method lookup: first Ruby follows an objectâs klass pointer and searches for methods; then Ruby keeps following super pointers all the way up the chain
until it finds the appropriate method or reaches the top.
The important thing to remember is that classes are
objects, too. Just as a plain-old object can have a
singleton class, class objects can also have their own singleton
classes. Those singleton classes, like all other classes, can have
methods. Since the singleton class is accessed through the klass pointer of its ownerâs class object,
the singleton classâs instance methods are class methods of the
singletonâs owner.
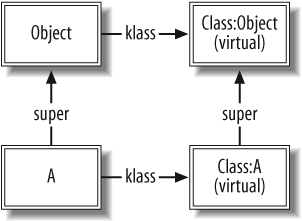
The full set of data structures for the following code is shown in Figure 1-9:
class A end
Class A inherits from
Object. The A class object is of type Class. Class inherits from Module, which inherits from Object. The methods stored in Aâs m_tbl are instance methods of A. So what happens when we call a class
method on A?
A.to_s # => "A"
The same method lookup rules apply, with A as the receiver. (Remember, A is a constant that evaluates to Aâs class object.) First, Ruby follows
Aâs klass pointer to Class. Classâs m_tbl is searched for a function named
to_s. Finding none, Ruby follows
Class's super pointer to Module, where the to_s function is found (in native code,
rb_mod_to_s).
This should not be a surprise. There is no magic here. Class methods are found in the exact same way as instance methodsâthe only difference is whether the receiver is a class or an instance of a class.
Now that we know how class methods are looked up, it would
seem that we could define class methods on any class by defining
instance methods on the Class
object (to insert them into Classâs m_tbl). Indeed, this works:
class A; end # from Module#to_s A.to_s # => "A" class Class def to_s; "Class#to_s"; end end A.to_s # => "Class#to_s"
That is an interesting trick, but it is of very limited utility. Usually we want to define unique class methods on each class. This is where singleton classes of class objects are used. To open up a singleton class on a class, simply pass the classâs name as the object to the singleton class notation:
class A; end class B; end class <<A def to_s; "Class A"; end end A.to_s # => "Class A" B.to_s # => "B"
The resulting data structures are shown in Figure 1-10. Class B is omitted for brevity.
The to_s method has been added to Aâs singleton class, or Class:A. Now, when A.to_s is called, Ruby will follow
A's klass pointer to Class:A and invoke the appropriate method
there.
There is one more wrinkle in method definition. In a class or
module definition, self always
refers to the class or module object:
class A self # => A end
So, inside Aâs class
definition, class<<A can
also be written class<<self, since inside that
definition A and self refer to the same object. This idiom
is used everywhere in Rails to define class methods. This example shows all of the ways to define
class methods:
class A def A.class_method_one; "Class method"; end def self.class_method_two; "Also a class method"; end class <<A def class_method_three; "Still a class method"; end end class <<self def class_method_four; "Yet another class method"; end end end def A.class_method_five "This works outside of the class definition" end class <<A def A.class_method_six "You can open the metaclass outside of the class definition" end end # Print the result of calling each method in turn %w(one two three four five six).each do |number| puts A.send(:"class_method_#{number}") end # >> Class method # >> Also a class method # >> Still a class method # >> Yet another class method # >> This works outside of the class definition # >> You can open the metaclass outside of the class definition
This also means that inside a singleton class definitionâas in
any other class definitionâself
refers to the class object being defined. When we remember that the
value of a block or class definition is the value of the last
statement executed, we can see that the value of class <<objA; self; end is objAâs singleton class. The class <<objA construct opens up the
singleton class, and self (the
singleton class) is returned from the class definition.
Putting this together, we can open up the Object class and add an instance method to
every object that returns that objectâs singleton class:
class Object def metaclass class <<self self end end end
This method forms the basis of Metaid, which is described shortly.
Method missing
After all of that confusion, method_missing is remarkably simple. There
is one rule: if the whole method lookup procedure fails all the way up to Object, method lookup is tried again,
looking for a method_missing
method rather than the original method. If the method is found, it
is called with the same arguments as the original method, with the
method name prepended. Any block given is also passed
through.
The default method_missing
function in Object
(rb_method_missing) raises an exception.
Metaid
why the lucky stiff has created a tiny library for Ruby metaprogramming called metaid.rb. This snippet is useful enough to include in any project in which meta-programming is needed:[7]
class Object # The hidden singleton lurks behind everyone def metaclass; class << self; self; end; end def meta_eval &blk; metaclass.instance_eval &blk; end # Adds methods to a metaclass def meta_def name, &blk meta_eval { define_method name, &blk } end # Defines an instance method within a class def class_def name, &blk class_eval { define_method name, &blk } end end
This library defines four methods on every object:
metaclassRefers to the singleton class of the receiver (self).
meta_evalThe equivalent of
class_evalfor singleton classes. Evaluates the given block in the context of the receiverâs singleton class.meta_defDefines a method within the receiverâs singleton class. If the receiver is a class or module, this will create a class method (instance method of the receiverâs singleton class).
class_defDefines an instance method in the receiver (which must be a class or module).
Metaidâs convenience lies in its brevity. By using a shorthand
for referring to and augmenting metaclasses, your code will become
clearer rather than being littered with constructs like class << self; self; end. The shorter
and more readable these techniques are, the more likely you are to use
them appropriately in your programs.
This example shows how we can use Metaid to examine and simplify our singleton class hacking:
class Person def name; "Bob"; end def self.species; "Homo sapiens"; end end
Class methods are added as instance methods of the singleton class:
Person.instance_methods(false) # => ["name"] Person.metaclass.instance_methods - Object.metaclass.instance_methods # => ["species"]
Using the methods from Metaid, we could have written the method definitions as:
Person.class_def(:name) { "Bob" }
Person.meta_def(:species) { "Homo sapiens" }Variable Lookup
There are four types of variables in Ruby: global variables, class variables, instance variables, and local variables.[8] Global variables are stored globally, and local variables are stored lexically, so neither of them is relevant to our discussion now, as they do not interact with Rubyâs class system.
Instance variables are specific to a certain object. They are
prefixed with one @ symbol:
@price is an instance variable.
Because every Ruby object has an iv_tbl structure, any object can have
instance variables.
Since a class is also an object, a class can have instance variables. The following code accesses an instance variable of a class:
class A @ivar = "Instance variable of A" end A.instance_variable_get(:@ivar) # => "Instance variable of A"
Instance variables are always resolved based on the object
pointed to by self. Because
self is Aâs class object in the class A ⦠end definition, @ivar belongs to Aâs class object.
Class variables are different. Any instance of a class can
access its class variables (which start with @@). Class variables can also be referenced
from the class definition itself. While class variables and instance
variables of a class are similar, theyâre not the same:
class A @var = "Instance variable of A" @@var = "Class variable of A" def A.ivar @var end def A.cvar @@var end end A.ivar # => "Instance variable of A" A.cvar # => "Class variable of A"
In this code sample, @var and
@@var are stored in the same place:
in Aâs iv_tbl. However, they are different
variables, because they have different names (the @ symbols are included in the variableâs
name as stored). Rubyâs functions for accessing instance variables and
class variables check to ensure that the names passed are in the
proper format:
A.instance_variable_get(:@@var) # ~> -:17:in 'instance_variable_get': '@@var' is not allowed as an instance variable name (NameError)
Class variables can be somewhat confusing to use. They are shared all the way down the inheritance hierarchy, so subclasses that modify a class variable will modify the parentâs class variable as well.
>> class A; @@x = 3 end => 3 >> class B < A; @@x = 4 end => 4 >> class A; @@x end => 4
This may be useful, but it may also be confusing. Generally, you either want class instance variablesâwhich are independent of the inheritance hierarchyâor the class inheritable attributes provided by ActiveSupport, which propagate values in a controlled, well-defined manner.
Blocks, Methods, and Procs
One powerful feature of Ruby is the ability to work with pieces of code as objects. There are three classes that come into play, as follows:
ProcA Procrepresents a code block: a piece of code that can be called with arguments and has a return value.UnboundMethodThis is similar to a
Proc; it represents an instance method of a particular class. (Remember that class methods are instance methods of a class object, soUnboundMethodscan represent class methods, too.) AnUnboundMethodmust be bound to a class before it can be invoked.MethodMethodobjects areUnboundMethodsthat have been bound to an object withUnboundMethod#bind. Alternatively, they can be obtained withObject#method.
Letâs examine some ways to get Proc and Method objects. Weâll use the Fixnum#+ method as an example. We usually
invoke it using the dyadic syntax:
3 + 5 # => 8
However, it can be invoked as an instance method of a Fixnum object, like any other instance
method:
3.+(5) # => 8
We can use the Object#method
method to get an object representing this instance method. The method
will be bound to the object that method was called on, 3.
add_3 = 3.method(:+) add_3 # => #<Method: Fixnum#+>
This method can be converted to a Proc, or called directly with
arguments:
add_3.to_proc # => #<Proc:0x00024b08@-:6> add_3.call(5) # => 8 # Method#[] is a handy synonym for Method#call. add_3[5] # => 8
There are two ways to obtain an unbound method. We can call
instance_method on the class
object:
add_unbound = Fixnum.instance_method(:+) add_unbound # => #<UnboundMethod: Fixnum#+>
We can also unbind a method that has already been bound to an object:
add_unbound == 3.method(:+).unbind # => true add_unbound.bind(3).call(5) # => 8
We can bind the UnboundMethod
to any other object of the same class:
add_unbound.bind(15)[4] # => 19
However, the object we bind to must be an
instance of the same class, or else we get a TypeError:
add_unbound.bind(1.5)[4] # => # ~> -:16:in 'bind': bind argument must be an instance of Fixnum (TypeError) # ~> from -:16
We get this error because + is defined in Fixnum; therefore, the UnboundMethod object we receive must be
bound to an object that is a kind_of?(Fixnum). Had the + method been
defined in Numeric (from which both
Fixnum and Float inherit), the preceding code would have returned 5.5.
Blocks to Procs and Procs to blocks
One downside to the current implementation of Ruby: blocks are
not always Procs, and vice versa.
Ordinary blocks (created with doâ¦end or {}) must be attached to a method
call, and are not automatically objects. For example, you cannot say
code_ block ={puts"abc"}. This is
what the Kernel#lambda and
Proc.new functions are for:
converting blocks to Procs.
[9]
block_1 = lambda { puts "abc" } # => #<Proc:0x00024914@-:20>
block_2 = Proc.new { puts "abc" } # => #<Proc:0x000246a8@-:21>There is a slight difference between Kernel#lambda and Proc.new. Returning from a Proc created with Kernel#lambda returns the given value to
the calling function; returning from a Proc created with Proc.new attempts to return
from the calling function, raising a LocalJumpError if that is impossible. Here
is an example:
def block_test
lambda_proc = lambda { return 3 }
proc_new_proc = Proc.new { return 4 }
lambda_proc.call # => 3
proc_new_proc.call # =>
puts "Never reached"
end
block_test # => 4The return statement in lambda_proc returns the value 3 from the
lambda. Conversely, the return statement in proc_new_proc returns from the calling
function, block_testâ thus, the
value 4 is returned from block_test. The puts statement is never
executed, because the proc_new_proc.call statement returns from
block_test first.
Blocks can also be converted to Procs by passing them to a function, using
& in the functionâs formal parameters:
def some_function(&b)
puts "Block is a #{b} and returns #{b.call}"
end
some_function { 6 + 3 }
# >> Block is a #<Proc:0x00025774@-:7> and returns 9Conversely, you can also substitute a Proc with & when a function expects a
block:
add_3 = lambda {|x| x+3}
(1..5).map(&add_3) # => [4, 5, 6, 7, 8]Closures
Closures are created when a block or
Proc accesses variables defined
outside of its scope. Even though the containing block may go out of
scope, the variables are kept around until the block or Proc referencing them goes out of scope. A
simplistic example, though not practically useful, demonstrates the
idea:
def get_closure
data = [1, 2, 3]
lambda { data }
end
block = get_closure
block.call # => [1, 2, 3]The anonymous function (the lambda) returned from get_closure references the local variable
data, which is defined outside of its scope. As long as the block variable is in scope, it will hold
its own reference to data, and
that instance of data will not be
destroyed (even though the get_closure function returns). Note that
each time get_closure is called,
data references a different
variable (since it is function-local):
block = get_closure block2 = get_closure block.call.object_id # => 76200 block2.call.object_id # => 76170
A classic example of closures is the make_counter function, which returns a
counter function (a Proc) that,
when executed, increments and returns its counter. In Ruby, make_counter can be implemented like
this:
def make_counter(i=0) lambda { i += 1 } end x = make_counter x.call # => 1 x.call # => 2 y = make_counter y.call # => 1 y.call # => 2
The lambda function creates
a closure that closes over the current value of the local variable
i. Not only can the variable be
accessed, but its value can be modified. Each closure gets a
separate instance of the variable (because it is a variable local to
a particular instantiation of make_counter). Since x and y
contain references to different instances of the local variable
i, they have different
state.
Metaprogramming Techniques
Now that weâve covered the fundamentals of Ruby, we can examine some of the common metaprogramming techniques that are used in Rails.
Although we write examples in Ruby, most of these techniques are applicable to any dynamic programming language. In fact, many of Rubyâs metaprogramming idioms are shamelessly stolen from either Lisp, Smalltalk, or Perl.
Delaying Method Lookup Until Runtime
Often we want to create an interface whose methods vary depending on some piece of runtime data.
The most prominent example of this in Rails is ActiveRecordâs
attribute accessor methods. Method calls on an ActiveRecord object
(like person.name) are translated
at runtime to attribute accesses. At the class-method level,
ActiveRecord offers extreme flexibility: Person.find_all_by_user_id_and_active(42,
true) is translated into the appropriate SQL query, raising the
standard NoMethodError exception
should those attributes not exist.
The magic behind this is Rubyâs method_missing method. When a nonexistent
method is called on an object, Ruby first checks that objectâs class
for a method_missing method before
raising a NoMethodError.
method_missingâs first argument is the name of the method
called; the remainder of the arguments correspond to the arguments
passed to the method. Any block passed to the method is passed through
to method_missing. So, a complete
method signature is:
def method_missing(method_id, *args, &block) ... end
There are several drawbacks to using method_missing:
It is slower than conventional method lookup. Simple tests indicate that method dispatch with
method_missingis at least two to three times as expensive in time as conventional dispatch.Since the methods being called never actually existâthey are just intercepted at the last step of the method lookup processâthey cannot be documented or introspected as conventional methods can.
Because all dynamic methods must go through the
method_missingmethod, the body of that method can become quite large if there are many different aspects of the code that need to add methods dynamically.Using
method_missingrestricts compatibility with future versions of an API. Once you rely onmethod_missingto do something interesting with undefined methods, introducing new methods in a future API version can break your usersâ expectations.
A good alternative is the approach taken by ActiveRecordâs
generate_read_methods feature.
Rather than waiting for method_missing to intercept the calls,
ActiveRecord generates an implementation for the attribute setter and
reader methods so that they can be called via conventional method
dispatch.
This is a powerful method in general, and the dynamic nature of Ruby makes it possible to write methods that replace themselves with optimized versions of themselves when they are first called. This is used in Rails routing, which needs to be very fast; we will see that in action later in this chapter.
Generative Programming: Writing Code On-the-Fly
One powerful technique that encompasses some of the others is generative programmingâcode that writes code.
This technique can manifest in the simplest ways, such as writing a shell script to automate some tedious part of programming. For example, you may want to populate your test fixtures with a sample project for each user:
brad_project: id: 1 owner_id: 1 billing_status_id: 12 john_project: id: 2 owner_id: 2 billing_status_id: 4 ...
If this were a language without scriptable test fixtures, you might be writing these by hand. This gets messy when the data starts growing, and is next to impossible when the fixtures have strange dependencies on the source data. Naïve generative programming would have you writing a script to generate this fixture from the source. Although not ideal, this is a great improvement over writing the complete fixtures by hand. But this is a maintenance headache: you have to incorporate the script into your build process, and ensure that the fixture is regenerated when the source data changes.
This is rarely, if ever, needed in Ruby or Rails (thankfully). Almost every aspect of Rails application configuration is scriptable, due in large part to the use of internal domain-specific languages (DSLs). In an internal DSL, you have the full power of the Ruby language at your disposal, not just the particular interface the library author decided you should have.
Returning to the preceding example, ERb makes our job a lot
easier. We can inject arbitrary Ruby code into the YAML file above
using ERbâs <% %> and <%=
%> tags, including whatever logic we need:
<% User.find_all_by_active(true).each_with_index do |user, i| %>
<%= user.login %>_project:
id: <%= i %>
owner_id: <%= user.id %>
billing_status_id: <%= user.billing_status.id %>
<% end %>ActiveRecordâs implementation of this handy trick couldnât be simpler:
yaml = YAML::load(erb_render(yaml_string))
using the helper method erb_render:
def erb_render(fixture_content) ERB.new(fixture_content).result end
Generative programming often uses either Module#define_method or class_eval and def to create methods on-the-fly.
ActiveRecord uses this technique for attribute accessors; the generate_read_methods feature defines the setter and reader methods as instance methods on the ActiveRecord class in order to reduce the
number of times method_missing (a
relatively expensive technique) is needed.
Continuations
Continuations are a very powerful control-flow mechanism. A continuation represents a particular state of the call stack and lexical variables. It is a snapshot of a point in time when evaluating Ruby code. Unfortunately, the Ruby 1.8 implementation of continuations is so slow as to be unusable for many applications. The upcoming Ruby 1.9 virtual machines may improve this situation, but you should not expect good performance from continuations under Ruby 1.8. However, they are useful constructs, and continuation-based web frameworks provide an interesting alternative to frameworks like Rails, so we will survey their use here.
Continuations are powerful for several reasons:
Continuations are often described as âstructured
GOTO.â As such, they should be
treated with the same caution as any kind of GOTO construct. Continuations have little or no place inside application
code; they should usually be encapsulated within libraries. I donât
say this because I think developers should be protected from
themselves. Rather, continuations are general enough that it makes
more sense to build abstractions around them than to use them
directly. The idea is that a programmer should think âexternal
iteratorâ or âcoroutineâ (both abstractions built on top of
continuations) rather than âcontinuationâ when building the
application software.
Seaside [10] is a Smalltalk web application framework built on top of continuations. Continuations are used in Seaside to manage session state. Each user session corresponds to a server-side continuation. When a request comes in, the continuation is invoked and more code is run. The upshot is that entire transactions can be written as a single stream of code, even if they span multiple HTTP requests. This power comes from the fact that Smalltalkâs continuations are serializable; they can be written out to a database or to the filesystem, then thawed and reinvoked upon a request. Rubyâs continuations are nonserializable. In Ruby, continuations are in-memory only and cannot be transformed into a byte stream.
Borges (http://borges.rubyforge.org/) is a straightforward port of Seaside 2 to Ruby. The major difference between Seaside and Borges is that Borges must store all current continuations in memory, as they are not serializable. This is a huge limitation that unfortunately prevents Borges from being successful for web applications with any kind of volume. If serializable continuations are implemented in one of the Ruby implementations, this limitation can be removed.
The power of continuations is evident in the following Borges sample code, which renders a list of items from an online store:
class SushiNet::StoreItemList < Borges::Component
def choose(item)
call SushiNet::StoreItemView.new(item)
end
def initialize(items)
@batcher = Borges::BatchedList.new items, 8
end
def render_content_on(r)
r.list_do @batcher.batch do |item|
r.anchor item.title do choose item end
end
r.render @batcher
end
end # class SushiNet::StoreItemListThe bulk of the action happens in the render_content_on method, which uses a
BatchedList (a paginator) to render
a paginated list of links to products. But the fun happens in the call
to anchor, which stores away the
call to choose, to be executed when the corresponding link is
clicked.
However, there is still vast disagreement on how useful continuations are for web programming. HTTP was designed as a stateless protocol, and continuations for web transactions are the polar opposite of statelessness. All of the continuations must be stored on the server, which takes additional memory and disk space. Sticky sessions are required, to direct a userâs traffic to the same server. As a result, if one server goes down, all of its sessions are lost. The most popular Seaside application, DabbleDB (http://dabbledb.com/), actually uses continuations very little.
Bindings
Bindings provide context for evaluation of Ruby code. A binding is the set of variables and methods that are
available at a particular (lexical) point in the code. Any place in Ruby code where
statements may be evaluated has a binding, and that binding can be obtained with Kernel#binding. Bindings are just objects of class Binding, and they can
be passed around as any objects can:
class C binding # => #<Binding:0x2533c> def a_method binding end end binding # => #<Binding:0x252b0> C.new.a_method # => #<Binding:0x25238>
The Rails scaffold generator provides a good example of the use of bindings:
class ScaffoldingSandbox include ActionView::Helpers::ActiveRecordHelper attr_accessor :form_action, :singular_name, :suffix, :model_instance def sandbox_binding binding end # ... end
ScaffoldingSandbox is a class
that provides a clean environment from which to render a template. ERb
can render templates within the context of a binding, so that an API
is available from within the ERb templates.
part_binding = template_options[:sandbox].call.sandbox_binding # ... ERB.new(File.readlines(part_path).join,nil,'-').result(part_binding)
Earlier I mentioned that blocks are closures. A closureâs
binding represents its stateâthe set of variables and methods it has
access to. We can get at a closureâs binding with the Proc#binding method:
def var_from_binding(&b)
eval("var", b.binding)
end
var = 123
var_from_binding {} # => 123
var = 456
var_from_binding {} # => 456Here we are only using the Proc as a method by which to get the
binding. By accessing the binding (context) of those blocks, we can
access the local variable var with
a simple eval against the
binding.
Introspection and ObjectSpace: Examining Data and Methods at Runtime
Ruby provides many methods for looking into objects at runtime. There are object methods to access instance variables. These methods break encapsulation, so use them with care.
class C def initialize @ivar = 1 end end c = C.new c.instance_variables # => ["@ivar"] c.instance_variable_get(:@ivar) # => 1 c.instance_variable_set(:@ivar, 3) # => 3 c.instance_variable_get(:@ivar) # => 3
The Object#methods method
returns an array of instance methods, including singleton methods, defined on the receiver. If the first parameter
to methods is false, only the objectâs singleton methods
are returned.
class C def inst_method end def self.cls_method end end c = C.new class << c def singleton_method end end c.methods - Object.methods # => ["inst_method", "singleton_method"] c.methods(false) # => ["singleton_method"]
Module#instance_methods
returns an array of the class or moduleâs instance methods. Note that
instance_methods is called on the
class, while methods is called on
an instance. Passing false to
instance_methods skips the
superclassesâ methods:
C.instance_methods(false) # => ["inst_method"]
We can also use Metaidâs metaclass method to examine Câs class methods:
C.metaclass.instance_methods(false) # => ["new", "allocate", "cls_method", "superclass"]
In my experience, most of the value from these methods is in satisfying curiosity. With the exception of a few well-established idioms, there is rarely a need in production code to reflect on an objectâs methods. Far more often, these techniques can be used at a console prompt to find methods available on an objectâitâs usually quicker than reaching for a reference book:
Array.instance_methods.grep /sort/ # => ["sort!", "sort", "sort_by"]
ObjectSpace
ObjectSpace is a module
used to interact with Rubyâs object system. It has a few useful
module methods that can make low-level hacking easier:
Garbage-collection methods:
define_finalizer(sets up a callback to be called just before an object is destroyed),undefine_finalizer(removes those call-backs), and garbage_collect (starts garbage collection)._id2refconverts an objectâs ID to a reference to that Ruby object.each_objectiterates through all objects (or all objects of a certain class) and yields them to a block.
As always, with great power comes great responsibility. Although these methods can be useful, they can also be dangerous. Use them judiciously.
An example of the proper use of ObjectSpace is found in Rubyâs Test::Unit frame-work. This code uses
ObjectSpace.each_object to
enumerate all classes in existence that inherit from Test::Unit::TestCase:
test_classes = []
ObjectSpace.each_object(Class) {
| klass |
test_classes << klass if (Test::Unit::TestCase > klass)
}ObjectSpace, unfortunately,
greatly complicates some Ruby virtual machines. In particular, JRuby
performance suffers tremendously when ObjectSpace is enabled, because the Ruby
interpreter cannot directly examine the JVMâs heap for extant
objects. Instead, JRuby must keep track of objects manually, which
adds a great amount of overhead. As the same tricks can be achieved
with methods like Module.extended
and Class.inherited, there are
not many cases where ObjectSpace
is genuinely necessary.
Delegation with Proxy Classes
Delegation is a form of composition. It is similar to inheritance, except with more conceptual âspaceâ between the objects being composed. Delegation implies a âhas-aâ rather than an âis-aâ relationship. When one object delegates to another, there are two objects in existence, rather than the one object that would result from an inheritance hierarchy.
Delegation is used in ActiveRecordâs associations. The AssociationProxy class delegates most
methods (including class) to its
target. In this way, associations can be lazily loaded (not loaded
until their data is needed) with a completely transparent
interface.
DelegateClass and Forwardable
Rubyâs standard library includes facilities for delegation.
The simplest is DelegateClass. By inheriting from DelegateClass(klass) and calling super(instance) in the constructor, a
class delegates any unknown method calls to the provided instance of
the class klass. As an example,
consider a Settings class that
delegates to a hash:
require 'delegate'
class Settings < DelegateClass(Hash)
def initialize(options = {})
super({:initialized_at => Time.now - 5}.merge(options))
end
def age
Time.now - self[:initialized_at]
end
end
settings = Settings.new :use_foo_bar => true
# Method calls are delegated to the object
settings[:use_foo_bar] # => true
settings.age # => 5.000301The Settings constructor
calls super to set the delegated
object to a new hash. Note the difference between composition and
inheritance: if we had inherited from Hash, then Settings would be a
hash; in this case, Settings
has a hash and delegates to it. This
composition relationship offers increased flexibility, especially
when the object to be delegated to may change (a function provided
by SimpleDelegator).
The Ruby standard library also includes Forwardable, which provides a simple
interface by which individual methods, rather than all undefined methods, can be
delegated to another object. ActiveSupport in Rails provides similar
functionality with a cleaner API through Module#delegate:
class User < ActiveRecord::Base belongs_to :person delegate :first_name, :last_name, :phone, :to => :person end
Monkeypatching
In Ruby, all classes are open. Any object or class is fair game to be modified at any time. This gives many opportunities for extending or overriding existing functionality. This extension can be done very cleanly, without modifying the original definitions.
Rails takes advantage of Rubyâs open class system extensively. Opening classes and adding code is referred to as monkeypatching (a term from the Python community). Though it sounds derogatory, this term is used in a decidedly positive light; monkey-patching is, on the whole, seen as an incredibly useful technique. Almost all Rails plugins monkeypatch the Rails core in some way or another.
Disadvantages of monkeypatching
There are two primary disadvantages to monkeypatching. First,
the code for one method call may be spread over several files. The
foremost example of this is in ActionControllerâs process method. This method is intercepted
by methods in up to five different files during the course of a
request. Each of these methods adds another feature: filters,
exception rescue, components, and session management. The end result
is a net gain: the benefit gained by separating each functional
component into a separate file outweighs the inflated call
stack.
Another consequence of the functionality being spread around is that it can be
difficult to properly document a method. Because the function of the
process method can change depending
on which code has been loaded, there is no good place to document what
each of the methods is adding. This problem exists because the
actual identity of the process
method changes as the methods are chained together.
Adding Functionality to Existing Methods
Because Rails encourages the philosophy of separation of concerns, you often will have the need to extend the functionality of existing code. Many times you will want to âpatchâ a feature onto an existing function without disturbing that functionâs code. Your addition may not be directly related to the functionâs original purpose: it may add authentication, logging, or some other important cross-cutting concern.
We will examine several approaches to the problem of cross-cutting concerns, and explain the one (method chaining) that has acquired the most momentum in the Ruby and Rails communities.
Subclassing
In traditional object-oriented programming, a class can be extended by inheriting from it and changing its data or behavior. This paradigm works for many purposes, but it has drawbacks:
The changes you want to make may be small, in which case setting up a new class may be overly complex. Each new class in an inheritance hierarchy adds to the mental overhead required to understand the code.
You may need to make a series of related changes to several otherwise-unrelated classes. Subclassing each one individually would be overkill and would separate functionality that should be kept together.
The class may already be in use throughout an application, and you want to change its behavior globally.
You may want to add or remove a feature at runtime, and have it take effect globally. (We will explore this technique with a full example later in the chapter.)
In more traditional object-oriented languages, these features would require complex code. Not only would the code be complex, it would be tightly coupled to either the existing code or the code that calls it.
Aspect-oriented programming
Aspect-oriented programming (AOP) is one technique that attempts to solve the issues of cross-cutting concerns. There has been much talk about the applicability of AOP to Ruby, since many of the advantages that AOP provides can already be obtained through metaprogramming. There is a Ruby proposal for cut-based AOP, [11] but it may be months or years before this is incorporated.
In cut-based AOP, cuts are sometimes called "transparent subclassesâ because they extend a classâs functionality in a modular way. Cuts act as subclasses but without the need to instantiate the subclass rather than the parent class.
The Ruby Facets library (facets.rubyforge.org) includes a pure-Ruby cut-based AOP library. http://facets.rubyforge.org/api/more/classes/Cut.html It has some limitations due to being written purely in Ruby, but the usage is fairly clean:
class Person def say_hi puts "Hello!" end end cut :Tracer < Person do def say_hi puts "Before method" super puts "After method" end end Person.new.say_hi # >> Before method # >> Hello! # >> After method
Here we see that the Tracer
cut is a transparent subclass: when we create an instance of
Person, it is affected by
Tracer without having to know
about Tracer. We can also change
Person#say_hi without disrupting
our cut.
For whatever reason, Ruby AOP techniques have not taken off. We will now introduce the standard way to deal with separation of concerns in Ruby.
Method chaining
The standard Ruby solution to this problem is method
chaining: aliasing an existing method to a new name and
overwriting its old definition with a new body. This new body
usually calls the old method definition by referring to the aliased
name (the equivalent of calling super in an inherited overriden method).
The effect is that a feature can be patched around an existing
method. Due to Rubyâs open class nature, features can be added to
almost any code from anywhere. Needless to say, this must be done
wisely so as to retain clarity.
There is a standard Ruby idiom for chaining methods. Assume we have some library code that grabs a
Person object from across the
network:
class Person def refresh # (get data from server) end end
This operation takes quite a while, and we would like to time
it and log the results. Leveraging Rubyâs open classes, we can just
open up the Person class again
and monkeypatch the logging code into refresh:
class Person def refresh_with_timing start_time = Time.now.to_f retval = refresh_without_timing end_time = Time.now.to_f logger.info "Refresh: #{"%.3f" % (end_time-start_time)} s." retval end alias_method :refresh_without_timing, :refresh alias_method :refresh, :refresh_with_timing end
We can put this code in a separate file (perhaps alongside
other timing code), and, as long as we require it after the original definition
of refresh, the timing code will
be properly added around the original method call. This aids in
separation of concerns because we can separate code into different
files based on its functional concern, not necessarily based on the
area that it modifies.
The two alias_method calls
patch around the original call to refresh, adding our timing code. The first
call aliases the original method as refresh_without_timing (giving us a name
by which to call the original method from refresh_with_timing); the second method
points refresh at our new
method.
This paradigm of using a two alias_method calls to add a feature is
common enough that it has a name in Rails: alias_method_chain. It takes two
arguments: the name of the original method and the name of the
feature.
Using alias_method_chain,
we can now collapse the two alias_method calls into one simple
line:
alias_method_chain :refresh, :timing
Modulization
Monkeypatching affords us a lot of power, but it pollutes the namespace of the patched class. Things can often be made cleaner by modulizing the additions and inserting the module in the classâs lookup chain. Tobias Lütkeâs Active Merchant Rails plugin uses this approach for the view helpers. First, a module is created with the helper method:
module ActiveMerchant module Billing module Integrations module ActionViewHelper def payment_service_for(order, account, options = {}, &proc) ... end end end end end
Then, in the pluginâs init.rb script, the
module is included in ActionView::Base:
require 'active_merchant/billing/integrations/action_view_helper' ActionView::Base.send(:include, ActiveMerchant::Billing::Integrations::ActionViewHelper)
It certainly would be simpler in code to directly open ActionView::Base and add the method, but
this has the advantage of modularity. All Active Merchant code is
contained within the ActiveMerchant
module.
There is one caveat to this approach. Because any included modules are searched for methods after the classâs own methods are searched, you cannot directly overwrite a classâs methods by including a module:
module M def test_method "Test from M" end end class C def test_method "Test from C" end end C.send(:include, M) C.new.test_method # => "Test from C"
Instead, you should create a new name in the module and use
alias_method_chain:
module M
def test_method_with_module
"Test from M"
end
end
class C
def test_method
"Test from C"
end
end
# for a plugin, these two lines would go in init.rb
C.send(:include, M)
C.class_eval { alias_method_chain :test_method, :module }
C.new.test_method # => "Test from M"Functional Programming
The paradigm of functional programming focuses on values rather than the side effects of evaluation. In contrast to imperative programming, the functional style deals with the values of expressions in a mathematical sense. Function application and composition are first-class concepts, and mutable state (although it obviously exists at a low level) is abstracted away from the programmer.
This is a somewhat confusing concept, and it is often unfamiliar even to experienced programmers. The best parallels are drawn from mathematics, from which functional programming is derived.
Consider the mathematical equation x = 3. The
equals sign in that expression indicates equivalence:
"x is equal to 3.â On the contrary, the Ruby
statement x = 3 is of a completely
different nature. That equals sign denotes assignment: âassign 3 to x.â
In a functional programming language, equals usually denotes equality
rather than assignment. The key difference here is that functional
programming languages specify what is to be
calculated; imperative programming languages tend to specify
how to calculate it.
Higher-Order Functions
The cornerstone of functional programming, of course, is functions. The primary way that the functional paradigm influences mainstream Ruby programming is in the use of higher-order functions (also called first-class functions, though these two terms are not strictly equivalent). Higher-order functions are functions that operate on other functions. Higher-order functions usually either take one or more functions as an argument or return a function.
Ruby supports functions as mostly first-class objects; they can
be created, manipulated, passed, returned, and called. Anonymous functions are represented as Proc objects, created with Proc.new or Kernel#lambda:
add = lambda{|a,b| a + b}
add.class # => Proc
add.arity # => 2
# call a Proc with Proc#call
add.call(1,2) # => 3
# alternate syntax
add[1,2] # => 3The most common use for blocks in Ruby is in conjunction with iterators. Many programmers who come to Ruby from other, more imperative-style languages start out writing code like this:
collection = (1..10).to_a for x in collection puts x end
The more Ruby-like way to express this is using an iterator,
Array#each, and passing it a block.
This is second nature to seasoned Ruby programmers:
collection.each {|x| puts x}This method is equivalent to creating a Proc object and passing it to each:
print_me = lambda{|x| puts x}
collection.each(&print_me)All of this is to show that functions are first-class objects and can be treated as any other object.
Enumerable
Rubyâs Enumerable module
provides several convenience methods to be mixed in to classes that
are âenumerable,â or can be iterated over. These methods rely on an
each instance method, and
optionally the <=> (comparison or âspaceshipâ) method. Enumerableâs methods fall into several
categories.
Filters
These methods return a subset of the items in the collection.
detect, findReturns the first item in the collection for which the block evaluates to
true,ornilif no such item was found.select, find_allReturns an array of all items in the collection for which the block evaluates to
true.rejectReturns an array of all items in the collection for which the block evaluates to
false.grep(x)Returns an array of all items in the collection for which
x === itemistrue. This usage is equivalent toselect{|item| x === item}.
Transformers
These methods transform a collection into another collection by one of several rules.
map, collectReturns an array consisting of the result of the given block being applied to each element in turn.
partitionsortReturns a new array of the elements in this collection, sorted by either the given block (treated as the
<=>method) or the elementsâ own<=>method.sort_byLike sort, but yields to the given block to obtain the values on which to sort. As array comparison is performed in element order, you can sort on multiple fields with
person.sort_by{|p| [p.city, p.name]}. Internally,sort_byperforms a Schwartzian transform, so it is more efficient thansortwhen the block is expensive to compute.zip(*others)Returns an array of tuples, built up from one element each from
selfandothers:puts [1,2,3].zip([4,5,6],[7,8,9]).inspect # >> [[1, 4, 7], [2, 5, 8], [3, 6, 9]]
When the collections are all of the same size,
zip(*others)is equivalent to([self]+others).transpose:puts [[1,2,3],[4,5,6],[7,8,9]].transpose.inspect # >> [[1, 4, 7], [2, 5, 8], [3, 6, 9]]
When a block is given, it is executed once for each item in the resulting array:
[1,2,3].zip([4,5,6],[7,8,9]) {|x| puts x.inspect} # >> [1, 4, 7] # >> [2, 5, 8] # >> [3, 6, 9]
Aggregators
These methods aggregate or summarize the data.
inject(initial)Folds an operation across a collection. Initially, yields an accumulator (
initialprovides the first value) and the first object to the block. The return value is used as the accumulator for the next iteration. Collection sum is often defined thus:module Enumerable def sum inject(0){|total, x| total + x} end end
If no initial value is given, the first iteration yields the first two items.
maxReturns the maximum value in the collection, as mined by the same logic as the
sortmethod.min
Other
The Enumerable methods are
fun, and you can usually find a customized method to do exactly what
you are looking for, no matter how obscure. If these methods fail
you, visit Ruby Facets (http://facets.rubyforge.org) for some
inspiration.
Enumerator
Ruby has yet another little-known trick up its sleeve, and that
is Enumerator from the standard
library. (As it is in the standard library and not the core language,
you must require "enumerator" to
use it.)
Enumerable provides many
iterators that can be used on any enumerable object, but it has one
limitation: all of the iterators are based on the each instance
method. If you want to use some iterator other than each as the basis
for map, inject, or any of the
other functions in Enumerable, you
can use Enumerator as a
bridge.
The signature of Enumerator.new is
Enumerator.new(obj, method,*args), where obj is the object to enumerate over,
method is the base iterator, and
args are any arguments that the
iterator receives. As an example, you could write a map_with_index function (a version of
map that passes the object and its
index to the given block) with the following code:
require "enumerator"
module Enumerable
def map_with_index &b
enum_for(:each_with_index).map(&b)
end
end
puts ("a".."f").map_with_index{|letter, i| [letter, i]}.inspect
# >> [["a", 0], ["b", 1], ["c", 2], ["d", 3], ["e", 4], ["f", 5]]The enum_for method returns
an Enumerator object whose each
method functions like the each_with_index method of the original
object. That Enumerator object has
already been extended with the instance methods from Enumerable, so we can just call map on it, passing the given block.
Enumerator also adds some
convenience methods to Enumerable,
which are useful to have. Enumerable#each_slice(n) iterates over
slices of the array, n-at-a-time:
(1..10).each_slice(3){|slice| puts slice.inspect}
# >> [1, 2, 3]
# >> [4, 5, 6]
# >> [7, 8, 9]
# >> [10]Similarly, Enumerable#each_cons(n) moves a âsliding
windowâ of size n over the
col-lection, one at a time:
(1..10).each_cons(3){|slice| puts slice.inspect}
# >> [1, 2, 3]
# >> [2, 3, 4]
# >> [3, 4, 5]
# >> [4, 5, 6]
# >> [5, 6, 7]
# >> [6, 7, 8]
# >> [7, 8, 9]
# >> [8, 9, 10]Enumeration is getting a facelift in Ruby 1.9. Enumerator is becoming part of the core
language. In addition, iterators return an Enumerator object automatically if they are
not given a block. In Ruby 1.8, you would usually do the following to
map over the values of a hash:
hash.values.map{|value| ... }This takes the hash, builds an array of values, and maps over
that array. To remove the intermediate step, you could use an Enumerator:
hash.enum_for(:each_value).map{|value| ... }That way, we have a small Enumerator object whose each method behaves
just as hashâs each_value method
does. This is preferable to creating a potentially large array and
releasing it moments later. In Ruby 1.9, this is the default behavior
if the iterator is not given a block. This simplifies our code:
hash.each_value.map{|value| ... }Examples
Runtime Feature Changes
This example ties together several of the techniques we have
seen in this chapter. We return to the Person example, where we want to time
several expensive methods:
class Person def refresh # ... end def dup # ... end end
In order to deploy this to a production environment, we may not want to leave our timing code in place all of the time because of overhead. However, we probably want to have the option to enable it when debugging. We will develop code that allows us to add and remove features (in this case, timing code) at runtime without touching the original source.
First, we set up methods wrapping each of our expensive methods
with timing commands. As usual, we do this by monkeypatching the
timing methods into Person from
another file to separate the timing code from the actual model
logic: [12].
class Person
TIMED_METHODS = [:refresh, :dup]
TIMED_METHODS.each do |method|
# set up _without_timing alias of original method
alias_method :"#{method}_without_timing", method
# set up _with_timing method that wraps the original in timing code
define_method :"#{method}_with_timing" do
start_time = Time.now.to_f
returning(self.send(:"#{method}_without_timing")) do
end_time = Time.now.to_f
puts "#{method}: #{"%.3f" % (end_time-start_time)} s."
end
end
end
endWe add singleton methods to Person to enable or disable tracing:
class << Person
def start_trace
TIMED_METHODS.each do |method|
alias_method method, :"#{method}_with_timing"
end
end
def end_trace
TIMED_METHODS.each do |method|
alias_method method, :"#{method}_without_timing"
end
end
endTo enable tracing, we wrap each method call in the timed method
call. To disable it, we simply point the method call back to the
original method (which is now only accessible by its _without_timing alias).
To use these additions, we simply call the Person.trace method:
p = Person.new p.refresh # => (...) Person.start_trace p.refresh # => (...) # -> refresh: 0.500 s. Person.end_trace p.refresh # => (...)
Now that we have the ability to add and remove the timing code during execution, we can expose this through our application; we could give the administrator or developer an interface to trace all or specified functions without restarting the application. This approach has several advantages over adding logging code to each function separately:
The original code is untouched; it can be changed or upgraded without affecting the tracing code.
When tracing is disabled, the code performs exactly as it did before tracing; the tracing code is invisible in stack traces. There is no performance overhead when tracing is disabled.
However, there are some disadvantages to writing what is essentially self-modifying code:
Tracing is only available at the function level. More detailed tracing would require changing or patching the original code. Rails code tends to address this by making methods small and their names descriptive.
Stack traces do become more complicated when tracing is enabled. With tracing, a stack trace into the
Person#refreshmethod would have an extra level:#refresh_with_timing, then#refresh_without_timing(the original method).This approach may break when using more than one application server, as the functions are aliased in-memory. The changes will not propagate between servers, and will revert when the server process is restarted. However, this can actually be a feature in production; typically, you will not want to profile all traffic in a high-traffic production environment, but only a subset of it.
Rails Routing Code
The Rails routing code is perhaps some of the most conceptually difficult code in Rails. The code faces several constraints:
Path segments may capture multiple parts of the URL:
â Controllers may be namespaced, so the route
":controller/:action/:id"can match the URL"/store/product/edit/15",with the controller being"store/product".â Routes may contain
path_infosegments that destructure multiple URL seg-ments: the route"page/*path_info"can match the URL"/page/products/ top_products/15", with thepath_infosegment capturing the remainder of the URL.Routes can be restricted by conditions that must be met in order for the route to match.
The routing system must be bidirectional; it is run forward to recognize routes and in reverse to generate them.
Route recognition must be fast because it is run once per HTTP request. Route generation must be lightning fast because it may be run tens of times per HTTP request (once per outgoing link) when generating a page.
Tip
Michael Koziarskiâs new routing_optimisation code in Rails 2.0
(actionpack/lib/action_controller/routing_optimisation.rb)
addresses the complexity of Rails routing. This new code optimizes
the simple case of generation of named routes with no extra
:requirements.
Because of the speed needed in both generation and recognition,
the routing code modifies itself at runtime. The ActionController::Routing::Route class
represents a single route (one entry in
config/routes.rb). The Route#recognize method
rewrites itself:
class Route
def recognize(path, environment={})
write_recognition
recognize path, environment
end
endThe recognize method calls
write_recognition, which processes
the route logic and creates a compiled version of the route. The
write_recognition method then
over-writes the definition of recognize with that definition. The last
line in the original recognize
method then calls recognize (which
has been replaced by the compiled version) with the original
arguments. This way, the route is compiled on the first call to
recognize. Any subsequent calls use
the compiled version, rather than having to reparse the routing DSL
and go through the routing logic again.
Here is the body of the write_recognition method:
def write_recognition
# Create an if structure to extract the params from a match if it occurs.
body = "params = parameter_shell.dup\n#{recognition_extraction * "\n"}\nparams"
body = "if #{recognition_conditions.join(" && ")}\n#{body}\nend"
# Build the method declaration and compile it
method_decl = "def recognize(path, env={})\n#{body}\nend"
instance_eval method_decl, "generated code (#{__FILE__}:#{__LINE__})"
method_decl
endThe local variable body is
built up with the compiled route code. It is wrapped in a method
declaration that overwrites recognize. For the default route:
map.connect ':controller/:action/:id'
write_recognition generates
code looking like this:
def recognize(path, env={})
if (match = /(long regex)/.match(path))
params = parameter_shell.dup
params[:controller] = match[1].downcase if match[1]
params[:action] = match[2] || "index"
params[:id] = match[3] if match[3]
params
end
endThe parameter_shell method
returns the default set of parameters associated with the route. This
method body simply tests against the regular expression, populating
and returning the params hash if
the regular expression matches. If there is no match, the method
returns nil.
Once this method body is created, it is evaluated in the context
of the route using instance_eval.
This overwrites that particular routeâs recognize method.
Further Reading
Minero AOKIâs Ruby Hacking Guide is an excellent introduction to Rubyâs internals. It is being translated into English at http://rhg.rubyforge.org/.
Eigenclass (http://eigenclass.org/) has several more technical articles on Ruby.
Evil.rb is a library for accessing the internals of Ruby objects.
It can change objectsâ internal state, traverse and examine the klass and super pointers, change an objectâs class, and
cause general mayhem. Use with caution. It is available at http:// rubyforge.org/projects/evil/. Mauricio Fernández
gives a taste of Evil at http://eigenclass. org/hiki.rb?evil.rb+dl+and+unfreeze.
Jamis Buck has a very detailed exploration of the Rails routing code, as well as several other difficult parts of Rails, at http://weblog.jamisbuck.org/under-the-hood.
One of the easiest-to-understand, most well-architectured pieces of Ruby software I have seen is Capistrano 2, also developed by Jamis Buck. Not only does Capistrano have a very clean API, it is extremely well built from the bottom up. If you havenât been under Capistranoâs hood, it will be well worth your time. The source is available via Subversion from http://svn.rubyonrails.org/rails/tools/capistrano/.
Mark Jason Dominusâs book Higher-Order Perl (Morgan Kaufmann Publishers) was revolutionary in introducing functional programming concepts into Perl. When Higher-Order Perl was released in 2005, Perl was a language not typically known for its functional programming support. Most of the examples in the book can be translated fairly readily into Ruby; this is a good exercise if you are familiar with Perl. James Edward Gray II has written up his version in his âHigher-Order Rubyâ series, at http://blog.grayproductions.net/categories/higherorder_ruby.
The Ruby Programming Language, by David Flanagan and Yukihiro Matsumoto (OâReilly), is a book covering both Ruby 1.8 and 1.9. It is due out in January 2008. The book includes a section on functional programming techniques in Ruby.
[3] If that werenât confusing enough, the Class object has class Class as well.
[4] Except immediate objects (Fixnums,
symbols, true, false, and nil); weâll get to those
later.
[5] Ruby often co-opts Smalltalkâs message-passing
terminology: when a method is called, it is said that one is
sending a message. The receiver is the object that the
message is sent to.
[6] ICLASS is Mauricio Fernándezâs term for these proxy
classes. They have no official name but are of type T_ICLASS in the Ruby source.
[7] âSeeing Metaclasses Clearly.â http://whytheluckystiff.net/articles/seeingMetaclassesClearly.html
[8] There are also constants, but they shouldnât vary. (They can, but Ruby will complain.)
[9] Kernel#proc is another
name for Kernel#lambda, but
its usage is deprecated.
[12] This code sample uses variable interpolation inside a symbol
literal. Because the symbol is defined using a double-quoted
string, variable interpolation is just as valid as in any other
double-quoted string: the symbol :âsym#{2+2}" is the same symbol as
:sym4
Get Advanced Rails now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

