Implementation
This section explains the implementation of Adaptor::DBI and Adaptor::File. We will cover only the key procedures that perform query processing and file or database I/O. Pay as much attention to the design gotchas and unimplemented features as you do to the code.
Adaptor::File
An
Adaptor::File instance represents all
objects stored in one file. When this adaptor is created (using
new), it reads the entire file and translates the
data to in-memory objects. Slurping the entire file into memory
avoids the problem of having to implement fancy on-disk schemes for
random access to variable-length data; after all, that is the job of
DBM and database implementations. For this reason, this approach is
not recommended for large numbers of objects (over 1,000, to pick a
number).
The file adaptor has an attribute called
all_instances, a hash table of all objects given
to its store method (and indexed by their
_id), as shown in Figure 11.2.
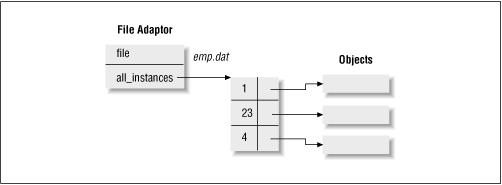
Figure 11-2. Structure of file adaptor
Storing objects
Let us examine the two methods for storing objects to files:
store() and flush ().
store
allocates a new unique identifier for
the object (if necessary) and simply pegs the object onto the
all_instances hash. It doesn’t send the data
to disk.
sub store { # adaptor->store($obj) (@_ == 2) || die 'Usage adaptor->store ($obj_to_store)'; my ($this, $obj_to_store) = @_; # $this is 'all_instances' my ...Get Advanced Perl Programming now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

