Chapter 2. Parsing Techniques
One thing Perl is particularly good at is throwing data around. There are two types of data in the world: regular, structured data and everything else. The good news is that regular data—colon delimited, tab delimited, and fixed-width files—is really easy to parse with Perl. We won’t deal with that here. The bad news is that regular, structured data is the minority.
If the data isn’t regular, then we need more advanced techniques to parse it. There are two major types of parser for this kind of less predictable data. The first is a bottom-up parser. Let’s say we have an HTML page. We can split the data up into meaningful chunks or tokens—tags and the data between tags, for instance—and then reconstruct what each token means. See Figure 2-1. This approach is called bottom-up parsing because it starts with the data and works toward a parse.
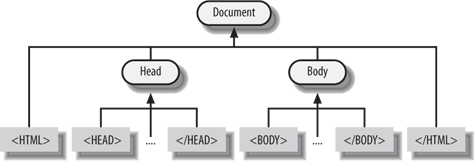 |
The other major type of parser is a top-down parser. This starts with some ideas of what an HTML file ought to look like: it has an <html> tag at the start and an </html> at the end, with some stuff in the middle. The parser can find that pattern in the document and then look to see what the stuff in the middle is likely to be. See Figure 2-2. This is called a top-down parse because it starts with all the possible parses and works down until it matches the actual contents of the document. ...
Get Advanced Perl Programming, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

