Data used by multiple documents can either be embedded (denormalized) or referenced (normalized). Denormalization isnât better than normalization and visa versa: each have their own trade-offs and you should choose to do whatever will work best with your application.
Denormalization can lead to inconsistent data: suppose you want to
change the apple to a pear in Figure 1-1. If you change
the value in one document but the application crashes before you can
update the other documents, your database will have two different values
for fruit floating around.
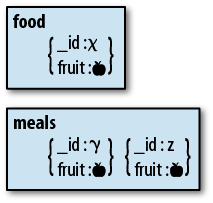
Inconsistency isnât great, but the level of ânot-greatnessâ depends on what youâre storing. For many applications, brief periods of inconsistency are OK: if someone changes his username, it might not matter that old posts show up with his old username for a few hours. If itâs not OK to have inconsistent values even briefly, you should go with normalization.
However, if you normalize, your application must do an extra query
every time it wants to find out what fruit is (Figure 1-2). If your application cannot afford this performance
hit and it will be OK to reconcile inconsistencies later, you should
denormalize.
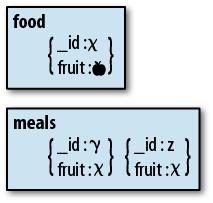
This is a trade-off: you cannot have both the fastest performance and guaranteed immediate consistency. You must decide which is more important for your application.
Suppose that we are designing a schema for a shopping cart application. Our application stores orders in MongoDB, but what information should an order contain?
- Normalized schema
A product:
{ "_id" :productId, "name" :name, "price" :price, "desc" :description}An order:
{ "_id" :orderId, "user" :userInfo, "items" : [productId1,productId2,productId3] }We store the
_idof each item in the order document. Then, when we display the contents of an order, we query the orders collection to get the correct order and then query the products collection to get the products associated with our list of_ids. There is no way to get a the full order in a single query with this schema.If the information about a product is updated, all of the documents referencing this product will âchange,â as these documents merely point to the definitive document.
Normalization gives us slower reads and a consistent view across all orders; multiple documents can atomically change (as only the reference document is actually changing).
- Denormalized schema
A product (same as previous):
{ "_id" :productId, "name" :name, "price" :price, "desc" :description}An order:
{ "_id" :orderId, "user" :userInfo, "items" : [ { "_id" :productId1, "name" :name1, "price" :price1}, { "_id" :productId2, "name" :name2, "price" :price2}, { "_id" :productId3, "name" :name3, "price" :price3} ] }We store the product information as an embedded document in the order. Then, when we display an order, we only need to do a single query.
If the information about a product is updated and we want the change to be propagated to the orders, we must update every cart separately.
Denormalization gives us faster reads and a less consistent view across all orders; product details cannot be changed atomically across multiple documents.
So, given these options, how do you decide whether to normalize or denormalize?
There are three major factors to consider:
Are you paying a price on every read for the very rare occurrence of data changing? You might read a product 10,000 times for every one time its details change. Do you want to pay a penalty on each of 10,000 reads to make that one write a bit quicker or guaranteed consistent? Most applications are much more read-heavy than write-heavy: figure out what your proportion is.
How often does the data youâre thinking of referencing actually change? The less it changes, the stronger the argument for denormalization. It is almost never worth referencing seldom-changing data such as names, birth dates, stock symbols, and addresses.
How important is consistency? If consistency is important, you should go with normalization. For example, suppose multiple documents need to atomically see a change. If we were designing a trading application where certain securities could only be traded at certain times, weâd want to instantly âlockâ them all when they were untradable. Then we could use a single lock document as a reference for the relevant group of securities documents. This sort of thing might be better to do at an application level, though, as the application will need to know the rules for when to lock and unlock anyway.
Another time consistency is important is for applications where inconsistencies are difficult to reconcile. In the orders example, we have a strict hierarchy: orders get their information from products, products never get their information from orders. If there were multiple âsourceâ documents, it would be difficult to decide which should win.
However, in this (somewhat contrived) order application, consistency could actually be detrimental. Suppose we want to put a product on sale at 20% off. We donât want to change any information in the existing orders, we just want to update the product description. So, in this case, we actually want a snapshot of what the data looked like at a point in time (see Tip #5: Embed âpoint-in-timeâ data).
Do reads need to be fast? If reads need to be as fast as possible, you should denormalize. In this application, they donât, so this isnât really a factor. Real-time applications should usually denormalize as much as possible.
There is a good case for denormalizing the order document: information doesnât change much and even when it does, we donât want orders to reflect the changes. Normalization doesnât give us any particular advantage here.
In this case, the best choice is to denormalize the orders schema.
Further reading:
Your Coffee Shop Doesnât Use Two-Phase Commit gives an example of how real-world systems handle consistency and how that relates to database design.
Normalization âfuture-proofsâ your data: you should be able to use normalized data for different applications that will query the data in different ways in the future.
This assumes that you have some data set that application after application, for years and years, will have to use. There are data sets like this, but most peopleâs data is constantly evolving, and old data is either updated or drops by the wayside. Most people want their database performing as fast as possible on the queries theyâre doing now, and if they change those queries in the future, theyâll optimize their database for the new queries.
Also, if an application is successful, its data set often becomes very application-specific. That isnât to say it couldnât be used for more that one application; often youâll at least want to do meta-analysis on it. But this is hardly the same as âfuture-proofingâ it to stand up to whatever queries people want to run in 10 years.
Note
Throughout this section, application unit is used as a general term for some application work. If you have a web or mobile application, you can think of an application unit as a request to the backend. Some other examples:
For a desktop application, this might be a user interaction.
For an analytics system, this might be one graph loaded.
It is basically a discrete unit of work that your application does that may involve accessing the database.
MongoDB schemas should be designed to do query per application unit.
If we were designing a blog application, a request for a blog post might be one application unit. When we display a post, we want the content, tags, some information about the author (although probably not her whole profile), and the postâs comments. Thus, we would embed all of this information in the post document and we could fetch everything needed for that view in one query.
Keep in mind that the goal is one query, not one document, per page: sometimes we might return multiple documents or portions of documents (not every field). For example, the main page might have the latest ten posts from the posts collection, but only their title, author, and a summary:
> db.posts.find({}, {"title" : 1, "author" : 1, "slug" : 1, "_id" : 0}).sort(
... {"date" : -1}).limit(10)There might be a page for each tag that would have a list of the last 20 posts with the given tag:
> db.posts.find({"tag" : someTag}, {"title" : 1, "author" : 1,
... "slug" : 1, "_id" : 0}).sort({"date" : -1}).limit(20)There would be a separate authors collection which would contain a complete profile for each author. An author page is simple, it would just be a document from the authors collection:
> db.authors.findOne({"name" : authorName})Documents in the posts collection might contain a subset of the information that appears in the author document: maybe the authorâs name and thumbnail profile picture.
Note that an application unit does not have to correspond with a single document, although it happens to in some of the previously described cases (a blog post and an authorâs page are each contained in a single document). However, there are plenty of cases in which an application unit would be multiple documents, but accessible through a single query.
Suppose we have an image board where users post messages consisting of an image and some text in either a new or an existing thread. Then an application unit is viewing 20 messages on a thread, so weâll have each personâs post be a separate document in the posts collection. When we want to display a page, weâll do the query:
> db.posts.find({"threadId" : id}).sort({"date" : 1}).limit(20)Then, when we want to get the next page of messages, weâll query for the next 20 messages on that thread, then the 20 after that, etc.:
> db.posts.find({"threadId" : id, "date" : {"$gt" : latestDateSeen}}).sort(
... {"date" : 1}).limit(20)Then we could put an index on {threadId :
1, date : 1} to get good performance on these queries.
Note
We donât use skip(20), as
ranges work better for pagination.
As your application becomes more complicated and users and managers request more features, do not despair if you need to make more than one query per application unit. The one-query-per-unit goal is a good starting point and metric to judging your initial schema, but the real world is messy. With any sufficiently complex application, youâre probably going to end up making more than one query for one of your applicationâs more ridiculous features.
When considering whether to embed or reference a document, ask yourself if youâll be querying for the information in this field by itself, or only in the framework of the larger document. For example, you might want to query on a tag, but only to link back to the posts with that tag, not for the tag on its own. Similarly with comments, you might have a list of recent comments, but people are interested in going to the post that inspired the comment (unless comments are first-class citizens in your application).
If you have been using a relational database and are migrating an existing schema to MongoDB, join tables are excellent candidates for embedding. Tables that are basically a key and a valueâsuch as tags, permissions, or addressesâalmost always work better embedded in MongoDB.
Finally, if only one document cares about certain information, embed the information in that document.
As mentioned in the orders example in Tip #1: Duplicate data for speed, reference data for integrity, you donât actually want the information in the order to change if a product, say, goes on sale or gets a new thumbnail. Any sort of information like this, where you want to snapshot the data at a particular time, should be embedded.
Another example from the order document: the address fields also fall into the âpoint-in-timeâ category of data. You donât want a userâs past orders to change if he updates his profile.
Because of the way MongoDB stores data, it is fairly inefficient to constantly be appending information to the end of an array. You want arrays and objects to be fairly constant in size during normal usage.
Thus, it is fine to embed 20 subdocuments, or 100, or 1,000,000, but do so up front. Allowing a document to grow a lot as it is used is probably going to be slower than youâd like.
Comments are often a weird edge case that varies on the application. Comments should, for most applications, be stored embedded in their parent document. However, for applications where the comments are their own entity or there are often hundreds or more, they should be stored as separate documents.
As another example, suppose we are creating an application solely for the purpose of commenting. The image board example in Tip #3: Try to fetch data in a single query is like this; the primary content is the comments. In this case, weâd want comments to be separate documents.
If you know that your document is going to need certain fields in the future, it is more efficient to populate them when you first insert it than to create the fields as you go. For example, suppose you are creating an application for site analytics, to see how many users visited different pages every minute over a day. We will have a pages collection, where each document represents a 6-hour slice in time for a page. We want to store info per minute and per hour:
{
"_id" : pageId,
"start" : time,
"visits" : {
"minutes" : [
[num0, num1, ..., num59],
[num0, num1, ..., num59],
[num0, num1, ..., num59],
[num0, num1, ..., num59],
[num0, num1, ..., num59],
[num0, num1, ..., num59]
],
"hours" : [num0, ..., num5]
}
}We have a huge advantage here: we know what these documents are going to look like from now until the end of time. There will be one with a start time of now with an entry every minute for the next six hours. Then there will be another document like this, and another one.
Thus, we could have a batch job that either inserts these âtemplateâ
documents at a non-busy time or in a steady trickle over the course of the
day. This script could insert documents that look like this, replacing
someTime with whatever the next 6-hour interval
should be:
{
"_id" : pageId,
"start" : someTime,
"visits" : {
"minutes" : [
[0, 0, ..., 0],
[0, 0, ..., 0],
[0, 0, ..., 0],
[0, 0, ..., 0],
[0, 0, ..., 0],
[0, 0, ..., 0]
],
"hours" : [0, 0, 0, 0, 0, 0]
}
}Now, when you increment or set these counters, MongoDB does not need to find space for them. It merely updates the values youâve already entered, which is much faster.
For example, at the beginning of the hour, your program might do something like:
> db.pages.update({"_id" : pageId, "start" : thisHour},
... {"$inc" : {"visits.0.0" : 3}})This idea can be extended to other types of data and even collections and databases themselves. If you use a new collection each day, you might as well create them in advance.
This is closely related to both Tip #6: Do not embed fields that have unbound growth and Tip #7: Pre-populate anything you can. This is an optimization for once you know that your documents usually grow to a certain size, but they start out at a smaller size. When you initially insert the document, add a garbage field that contains a string the size that the document will (eventually) be, then immediately unset that field:
> collection.insert({"_id" : 123, /* other fields */, "garbage" : someLongString})
> collection.update({"_id" : 123}, {"$unset" : {"garbage" : 1}})This way, MongoDB will initially place the document somewhere that gives it enough room to grow (Figure 1-3).
A question that often comes up is whether to embed information in an array or a subdocument. Subdocuments should be used when youâll always know exactly what youâll be querying for. If there is any chance that you wonât know exactly what youâre querying for, use an array. Arrays should usually be used when you know some criteria about the element youâre querying for.
Suppose we are programming a game where the player picks up various items. We might model the player document as:
{
"_id" : "fred",
"items" : {
"slingshot" : {
"type" : "weapon",
"damage" : 23,
"ranged" : true
},
"jar" : {
"type" : "container",
"contains" : "fairy"
},
"sword" : {
"type" : "weapon",
"damage" : 50,
"ranged" : false
}
}
}Now, suppose we want to find all weapons where damage is greater than 20. We canât!
Subdocuments do not allow you to reach into items and say, âGive me any item with damage greater than 20.â You can only ask for
specific items: âIs
items.slingshot.damage greater than 20? How about
items.sword.damage?â and so on.
If you want to be able to access any item without knowing its identifier, you should arrange your schema to store items in an array:
{
"_id" : "fred",
"items" : [
{
"id" : "slingshot",
"type" : "weapon",
"damage" : 23,
"ranged" : true
},
{
"id" : "jar",
"type" : "container",
"contains" : "fairy"
},
{
"id" : "sword",
"type" : "weapon",
"damage" : 50,
"ranged" : false
}
]
}Now you can use a simple query such as {"items.damage" : {"$gt" : 20}}. If you need
more than one criteria of a given item matched (say, damage and ranged), you can use $elemMatch.
So, when should you use a subdocument instead of an array? When you know and will always know the name of the field that you are accessing.
For example, suppose we keep track of a playerâs abilities: her strength, intelligence, wisdom, dexterity, constitution, and charisma. We will always know which specific ability we are looking for, so we could store this as:
{
"_id" : "fred",
"race" : "gnome",
"class" : "illusionist",
"abilities" : {
"str" : 20,
"int" : 12,
"wis" : 18,
"dex" : 24,
"con" : 23,
"cha" : 22
}
}When we want to find a specific skill, we can look up abilities.str, or abilities.con, or whatever. Weâll never want to
find some ability thatâs greater than 20, weâll always know what weâre
looking for.
MongoDB is supposed to be a big, dumb data store. That is, it does almost no processing, it just stores and retrieves data. You should respect this goal and try to avoid forcing MongoDB to do any computation that could be done on the client. Even âtrivialâ tasks, such finding averages or summing fields should generally be pushed to the client.
If you want to query for information that must be computed and is not explicitly present in your document, you have two choices:
Incur a serious performance penalty (forcing MongoDB to do the computation using JavaScript, see Tip #11: Prefer $-operators to JavaScript)
Make the information explicit in your document
Generally, you should just make the information explicit in your document.
Suppose you want to query for documents where the total number of
apples and oranges is 30. That is, your documents look
something like:
{
"_id" : 123,
"apples" : 10,
"oranges" : 5
}Querying for the total, given the document above, will require
JavaScript and thus is very inefficient. Instead, add a total field to the document:
{
"_id" : 123,
"apples" : 10,
"oranges" : 5,
"total" : 15
}Then this total field can be incremented when apples or oranges are changed:
> db.food.update(criteria,
... {"$inc" : {"apples" : 10, "oranges" : -2, "total" : 8}})
> db.food.findOne()
{
"_id" : 123,
"apples" : 20,
"oranges" : 3,
"total" : 23
}This becomes trickier if you arenât sure whether an update will change anything. For example, suppose you want to be able to query for the number types of fruit, but you donât know whether your update will add a new type.
So, suppose your documents looked something like this:
{
"_id" : 123,
"apples" : 20,
"oranges : 3,
"total" : 2
} Now, if you do an update that might or might not create a new field,
do you increment total or not? If the update ends up
creating a new field, total should be updated:
> db.food.update({"_id" : 123}, {"$inc" : {"banana" : 3, "total" : 1}})Conversely, if the banana field already exists, we shouldnât increment the total. But from the client side, we donât know whether it exists!
There are two ways of dealing with this that are probably becoming familiar: the fast, inconsistent way, and the slow, consistent way.
The fast way is to chose to either add or not add 1 to
total and make our application aware that itâll need to
check the actual total on the client side. We can have an ongoing batch
job that corrects any inconsistencies we end up with.
If our application can take the extra time immediately, we could do
a findAndModify that âlocksâ the
document (setting a âlockedâ field that other writes will manually check),
return the document, and then issue an update unlocking the document and
updating the fields and total correctly:
> var result = db.runCommand({"findAndModify" : "food",
... "query" : {/* other criteria */, "locked" : false},
... "update" : {"$set" : {"locked" : true}}})
>
> if ("banana" in result.value) {
... db.fruit.update(criteria, {"$set" : {"locked" : false},
... "$inc" : {"banana" : 3}})
... } else {
... // increment total if banana field doesn't exist yet
... db.fruit.update(criteria, {"$set" : {"locked" : false},
... "$inc" : {"banana" : 3, "total" : 1}})
... } The correct choice depends on your application.
Certain operations cannot be done with
$-operators. For most applications, making a document
self-sufficient will minimize the complexity of the queries that you must
do. However, sometimes you will have to query for something that you
cannot express with $-operators. In that case,
JavaScript can come to your rescue: you can use a $where clause to execute arbitrary JavaScript as
part of your query.
To use $where in a query, write a
JavaScript function that returns true
or false (whether that document matches
the $where or not). So, suppose we only
wanted to return records where the value of member[0].age and member[1].age are equal. We could do this
with:
> db.members.find({"$where" : function() {
... return this.member[0].age == this.member[1].age;
... }})As you might imagine, $where
gives your queries quite a lot of power. However, it is also slow.
$where takes a long time
because of what MongoDB is doing behind the scenes: when you perform a
normal (non-$where) query, your
client turns that query into BSON and sends it to the database.
MongoDB stores data in BSON, too, so it can basically compare your query
directly against the data. This is very fast and efficient.
Now suppose you have a $where
clause that must be executed as part of your query. MongoDB will have to
create a JavaScript object for every document in the collection, parsing
the documentsâ BSON and adding all of their fields to the JavaScript
objects. Then it executes the JavaScript you sent against the documents,
then tears it all down again. This is extremely time- and
resource-intensive.
$where is a good hack when
necessary, but it should be avoided whenever possible. In fact, if you
notice that your queries require lots of $wheres, that is a good indication that you
should rethink your schema.
If a $where query is needed,
you can cut down on the performance hit by minimizing the number of
documents that make it to the $where.
Try to come up with other criteria that can be checked without a
$where and list that criteria first;
the fewer documents that are âin the runningâ by the time the query gets
to the $where, the less time the
$where will take.
For example, suppose that we have the $where example given above, and we realize
that, as weâre checking two membersâ ages, we are only for members with
at least a joint membership, maybe a family members:
> db.members.find({'type' : {$in : ['joint', 'family']},
... "$where" : function() {
... return this.member[0].age == this.member[1].age;
... }})Now all single membership documents will be excluded by the time
the query gets to the $where.
Whenever possible, compute aggregations over time with $inc. For example, in Tip #7: Pre-populate anything you can,
we have an analytics application with stats by the minute and the hour. We
can increment the hour stats at the same time that we increment the minute
ones.
If your aggregations need more munging (for example, finding the average number of queries over the hour), store the data in the minutes field and then have an ongoing batch process that computes averages from the latest minutes. As all of the information necessary to compute the aggregation is stored in one document, this processing could even be passed off to the client for newer (unaggregated) documents. Older documents would have already been tallied by the batch job.
Given MongoDBâs schemaless nature and the advantages to denormalizing, youâll need to keep your data consistent in your application.
Many ODMs have ways of enforcing consistent schemas to various levels of strictness. However, there are also the consistency issues brought up above: data inconsistencies caused by system failures (Tip #1: Duplicate data for speed, reference data for integrity) and limitations of MongoDBâs updates (Tip #10: Design documents to be self-sufficient). For these types of inconsistencies, youâll need to actually write a script that will check your data.
If you follow the tips in this chapter, you might end up with quite a few cron jobs, depending on your application. For example, you might have:
- Consistency fixer
Check computations and duplicate data to make sure that everyone has consistent values.
- Pre-populator
Create documents that will be needed in the future.
- Aggregator
Keep inline aggregations up-to-date.
Other useful scripts (not strictly related to this chapter) might be:
- Schema checker
Make sure the set of documents currently being used all have a certain set of fields, either correcting them automatically or notifying you about incorrect ones.
- Backup job
fsync, lock, and dump your database at regular intervals.
Running jobs in the background that check and protect your data give you more lassitude to play with it.
Get 50 Tips and Tricks for MongoDB Developers now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

