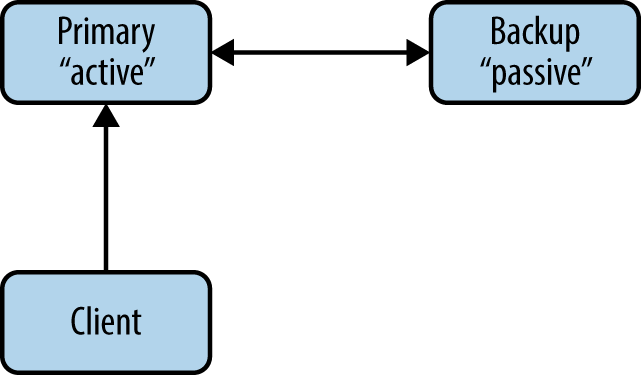
The Binary Star pattern configures two servers as a primary/backup high-availability pair (Figure 4-6). At any given time, one of these (the active server) accepts connections from client applications. The other (the passive server) does nothing, but the two servers monitor each other. If the active one disappears from the network, after a certain time the passive one takes over as active.
We developed the Binary Star pattern at iMatix for our OpenAMQ server. We designed it:
To provide a straightforward high-availability solution
To be simple enough to actually understand and use
To fail over reliably when needed, and only when needed
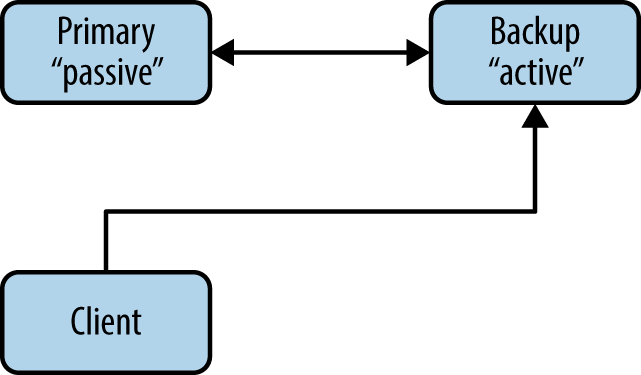
Assuming we have a Binary Star pair running, here are the different scenarios that will result in a failover (Figure 4-7):
The hardware running the primary server has a fatal problem (power supply explodes, machine catches fire, or someone simply unplugs it by mistake), and disappears. Applications see this and reconnect to the backup server.
The network segment on which the primary server sits crashesâperhaps because a router gets hit by a power spikeâand applications start to reconnect to the backup server.
The primary server crashes or is killed by the operator and does not restart automatically.
Recovery from failover works as follows:
The operators restart the primary server and fix whatever problems were causing it to disappear from the network.
The operators stop the backup server at a moment when it will cause minimal disruption to applications.
When applications have reconnected to the primary server, the operators restart the backup server.
Recovery (to using the primary server as the active one) is a manual operation. Painful experience has taught us that automatic recovery is undesirable. There are several reasons:
Failover creates an interruption of service to applications, possibly lasting 10â30 seconds. If there is a real emergency, this is much better than total outage. But if recovery creates a further such outage, it is better that this happens off-peak, when users have gone off the network.
When there is an emergency, the absolute first priority is certainty for those trying to fix things. Automatic recovery creates uncertainty for system administrators, who can no longer be sure which server is in charge without double-checking.
Automatic recovery can create situations where networks fail over and then recover, placing operators in the difficult position of analyzing what happened. There was an interruption of service, but the cause isnât clear.
Having said this, the Binary Star pattern will automatically fail back to the primary server if this is running (again) and the backup server fails. In fact, this is how we provoke recovery.
The shutdown process for a Binary Star pair is to do one of the following:
Stop the passive server and then stop the active server at any later time.
Stop both servers in any order, but within a few seconds of each other.
Stopping the active and then the passive server with any delay longer than the failover timeout will cause applications to disconnect, then reconnect, and then disconnect again, which may disturb users.
Get ZeroMQ now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

