Most of the services we enjoy on the Web are provided by web database applications. Web-based email, online shopping, forums and bulletin boards, corporate web sites, and sports and news portals are all database-driven. To build a modern web site, you need to develop a database application.
This book presents a highly popular, easy, low-cost way to bring together the Web and databases to build applications. The most popular database management system used in these solutions is MySQL, a very fast and easy-to-use system distributed under an Open Source license by its manufacturer, MySQL AB. We discuss MySQL in detail in this book.
With a web server such as Apache (we assume Apache in this book, although the software discussed here works with other web servers as well) and MySQL, you have most of what you need to develop a web database application. The key glue you need is a way for the web server to talk to the database; in other words, a way to incorporate database operations into web pages. The most popular glue that accomplishes this task is PHP.
PHP is an open source project of the Apache Software Foundation and it's the most popular Apache web server add-on module, with around 53% of the Apache HTTP servers having PHP capabilities.[1] PHP is particularly suited to web database applications because of its integration tools for the Web and database environments. In particular, the flexibility of embedding scripts in HTML pages permits easy integration of HTML presentation and code. The database tier integration support is also excellent, with more than 15 libraries available to interact with almost all popular database servers. In this book, we present a comprehensive view of PHP along with a number of powerful extensions provided by a repository known as PEAR.
Apache, MySQL, and PHP can run on a wide variety of operating systems. In this book, we show you how to use them on Linux, Mac OS X, and Microsoft Windows.
This is an introductory book, but it gives you the sophisticated knowledge you need to build applications properly. This includes critical tasks such as checking user input, handling errors robustly, and locking your database operations to avoid data corruption. Most importantly, we explain the principles behind good web database applications. You'll finish the book with not only the technical skills to create an application, but also an appreciation for the strategies that make an application secure, reliable, maintainable, and expandable.
When you browse the Web, you use your web browser to request resources from a web server and the web server responds with the resources. You make these requests by filling in and submitting forms, clicking on links, or typing URLs into your browser. Often, resources are static HTML pages that are displayed in the browser. Figure 1-1 shows how a web browser communicates with a web server to retrieve this book's home page. This is the classic two-tier or client-server architecture used on the Web.

Figure 1-1. A two-tier architecture where a web browser makes a request and the web server responds
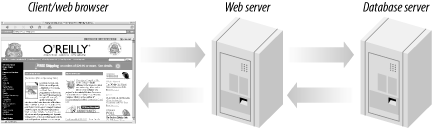
A web server is not sophisticated storage software. Complicated operations on data, done by commercial sites and anyone else presenting lots of dynamic data, should be handled by a separate database. This leads to a more complex architecture with three-tiers: the browser is still the client tier, the web server becomes the middle tier, and the database is the third or database tier. Figure 1-2 shows how a web browser requests a resource that's generated from a database, and how the database and web server respond to the request.
[1] From the Security Space web server survey, Apache module report, http://www.securityspace.com/s_survey/data/index.html (1 December 2003).
Get Web Database Applications with PHP and MySQL, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

