During a conference brainstorming session in 2003, web pioneer Dale Dougherty observed that far from having “crashed” after the dot-com bust, the Internet was thriving and had become more important than ever. He was excited about the wide range of new applications coming online and the high frequency with which they were appearing. What’s more, the conference participants noted that the companies that had survived the Internet industry’s 2000–2002 collapse seemed to have some things in common. These observations led to the development of the concept of “Web 2.0.”
To foster a better understanding of Web 2.0, Tim O’Reilly compiled a list comprising companies deemed Web 1.0 and those deemed Web 2.0, explaining his reasoning in his article “What Is Web 2.0.”[9] This list of companies, discussed in Chapter 1 and Chapter 3, is among the most widely published artifacts used to explain Web 2.0, and it provided us with an excellent set of examples from which to draw patterns of common experience.
While we were mining the examples in Tim’s list, a set of abstract patterns emerged. Although the names we use in this book might not match precisely the patterns Tim discussed in his article,[10] the concepts remain aligned. For example, we have renamed Tim’s “Cooperate, Don’t Control” pattern “Participation-Collaboration.” We developed the patterns using a single template, explained in Chapter 6, to express all of them in a consistent and unambiguous format. We present the patterns in that template format as a set of reusable artifacts to help developers, businesspeople, and futurists understand and use them.
We also defined an abstract model based on commonalities across the patterns, discussed in Chapter 4, which represents the evolution of the core model for Internet applications. Unlike the client/server model, often considered the core model for the first iteration of the Internet, this new Web 2.0 model captures the ways in which servers, clients, and users have evolved in the past decade. The abstraction makes it easier to find similarities at different scales in different environments. Although it can describe the interaction between an enterprise and a customer, it’s equally applicable to a cell phone providing a Bluetooth-enabled device with some data, as well as to hundreds of other potential applications.
Chapter 5 contains a more formal abstract Web 2.0 reference architecture. Similar to the model in Chapter 4, the reference architecture is abstracted from all the technologies, protocols, standards, vendor products, and other dependencies that may impact its durability. It doesn’t rely on any one flavor of these things, so you can use it among a very wide cross section of technological choices.
Although architects or developers could optionally build more specialized architectures, that is beyond the scope of this book. Figure 1 depicts the relationships between the Web 2.0 design patterns, models, and reference architecture artifacts.
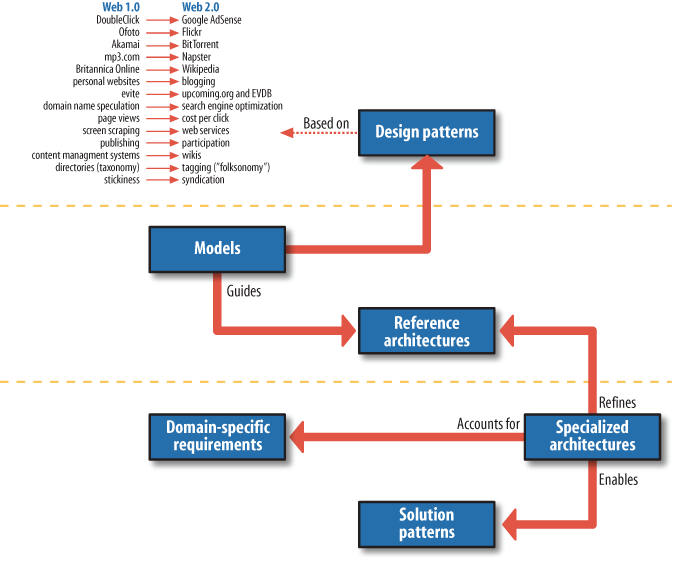
In several places in this book, it might seem as though the patterns we’re discussing are directly tied to a particular enterprise or other large corporate player. That’s not the intent, nor should readers infer such relationships from models or reference architectures. In fact, the beautiful truth about patterns is that they don’t depend on any specific implementation, and instead can be used as development or architecture guides in multiple technologies. Patterns let you share, reuse, and combine knowledge across multiple disciplines, even extending beyond the technology realm and into the business world.
Get Web 2.0 Architectures now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

