Chapter 1. MySQL History and Architecturel
MySQL architecture is best understood in the context of its history. Thus, the two are discussed in the same chapter.
MySQL History
MySQL history goes back to 1979 when Monty Widenius, working for a small company called TcX, created a reporting tool written in BASIC that ran on a 4 Mhz computer with 16 KB RAM. Over time, the tool was rewritten in C and ported to run on Unix. It was still just a low-level storage engine with a reporting front end. The tool was known by the name of Unireg.
Working under the adverse conditions of little computational resources, and perhaps building on his God-given talent, Monty developed a habit and ability to write very efficient code naturally. He also developed, or perhaps was gifted from the start, with an unusually acute vision of what needed to be done to the code to make it useful in future development—without knowing in advance much detail about what that future development would be.
In addition to the above, with TcX being a very small company and Monty being one of the owners, he had a lot of say in what happened to his code. While there are perhaps a good number of programmers out there with Monty’s talent and ability, for a number of reasons, few get to carry their code around for more than 20 years. Monty did.
Monty’s work, talents, and ownership of the code provided a foundation upon which the Miracle of MySQL could be built.
Some time in the 1990s, TcX customers began to push for an SQL interface to their data. Several possibilities were considered. One was to load it into a commercial database. Monty was not satisfied with the speed. He tried borrowing mSQL code for the SQL part and integrating it with his low-level storage engine. That did not work well, either. Then came the classic move of a talented, driven programmer: “I’ve had enough of those tools that somebody else wrote that don’t work! I’m writing my own!”
Thus in May of 1996 MySQL version 1.0 was released to a limited group, followed by a public release in October 1996 of version 3.11.1. The initial public release provided only a binary distribution for Solaris. A month later, the source and the Linux binary were released.
In the next two years, MySQL was ported to a number of other operating systems as the feature set gradually increased. MySQL was originally released under a special license that allowed commercial use to those who were not redistributing it with their software. Special licenses were available for sale to those who wanted to bundle it with their product. Additionally, commercial support was also being sold. This provided TcX with some revenue to justify the further development of MySQL, although the purpose of its original creation had already been fulfilled.
During this period MySQL progressed to version 3.22. It supported a decent subset of the SQL language, had an optimizer a lot more sophisticated than one would expect could possibly be written by one person, was extremely fast, and was very stable. Numerous APIs were contributed, so one could write a client in pretty much any existing programming language. However, it still lacked support for transactions, subqueries, foreign keys, stored procedures, and views. The locking happened only at a table level, which in some cases could slow it down to a grinding halt. Some programmers unable to get around its limitations still considered it a toy, while others were more than happy to dump their Oracle or SQL Server in favor of MySQL, and deal with the limitations in their code in exchange for improvement in performance and licensing cost savings.
Around 1999–2000 a separate company named MySQL AB was established. It hired several developers and established a partnership with Sleepycat to provide an SQL interface for the Berkeley DB data files. Since Berkeley DB had transaction capabilities, this would give MySQL support for transactions, which it previously lacked. After some changes in the code in preparation for integrating Berkeley DB, version 3.23 was released.
Although the MySQL developers could never work out all the quirks of the Berkeley DB interface and the Berkeley DB tables were never stable, the effort was not wasted. As a result, MySQL source became equipped with hooks to add any type of storage engine, including a transactional one.
By April of 2000, with some encouragement and sponsorship from Slashdot, masterslave replication capability was added. The old nontransactional storage engine, ISAM, was reworked and released as MyISAM. Among a number of improvements, full-text search capabilities were now supported. A short-lived partnership with NuSphere to add Gemini, a transactional engine with row-level locking, ended in a lawsuit toward the end of 2001. However, around the same time, Heikki Tuuri approached MySQL AB with a proposal to integrate his own storage engine, InnoDB, which was also capable of transactions and row-level locking.
Heikki’s contribution integrated much more smoothly with the new table handler interface already polished off by the Berkeley DB integration efforts. The MySQL/ InnoDB combination became version 4.0, and was released as alpha in October of 2001. By early 2002 the MySQL/InnoDB combo was stable and instantly took MySQL to another level. Version 4.0 was finally declared production stable in March 2003.
It might be worthy of mention that the version number change was not caused by the addition of InnoDB. MySQL developers have always viewed InnoDB as an important addition, but by no means something that they completely depend on for success. Back then, and even now, the addition of a new storage engine is not likely to be celebrated with a version number change. In fact, compared to previous versions, not much was added in version 4.0. Perhaps the most significant addition was the query cache, which greatly improved performance of a large number of applications. Replication code on the slave was rewritten to use two threads: one for network I/O from the master, and the other to process the updates. Some improvements were added to the optimizer. The client/server protocol became SSL-capable.
Version 4.1 was released as alpha in April of 2003, and was declared beta in June of 2004. Unlike version 4.0, it added a number of significant improvements. Perhaps the most significant was subqueries, a feature long-awaited by many users. Spatial indexing support was added to the MyISAM storage engine. Unicode support was implemented. The client/server protocol saw a number of changes. It was made more secure against attacks, and supported prepared statements.
In parallel with the alpha version of 4.1, work progressed on yet another development branch: version 5.0, which would add stored procedures, server-side cursors, triggers, views, XA transactions, significant improvements in the query optimizer, and a number of other features. The decision to create a separate development branch was made because MySQL developers felt that it would take a long time to stabilize 4.1 if, on top of all the new features that they were adding to it, they had to deal with the stored procedures. Version 5.0 was finally released as alpha in December 2003. For a while this created quite a bit of confusion—there were two branches in the alpha stage. Eventually 4.1 stabilized (October 2004), and the confusion was resolved.
Version 5.0 stabilized a year later, in October of 2005.
The first alpha release of 5.1 followed in November 2005, which added a number of improvements, some of which are table data partitioning, row-based replication, event scheduler, and a standardized plug-in API that facilitates the integration of new storage engines and other plug-ins.
At this point, MySQL is being actively developed. 5.0 is currently the stable version, while 5.1 is in beta and should soon become stable. New features at this point go into version 5.2.
MySQL Architecture
For the large part, MySQL architecture defies a formal definition or specification. When most of the code was originally written, it was not done to be a part of some great system in the future, but rather to solve some very specific problems. However, it was written so well and with enough insight that it reached the point where there were enough quality pieces to assemble a database server.
Core Modules
I make an attempt in this section to identify the
core modules in the system. However, let me add a
disclaimer that this is only an attempt to formalize what exists.
MySQL developers rarely think in those terms. Rather, they tend to
think of files, directories, classes, structures, and functions. It is
much more common to hear “This happens in mi_open( )" than to hear “This happens on
the MyISAM storage engine level.” MySQL developers know the code so
well that they are able to think conceptually on the level of
functions, structures, and classes. They will probably find the
abstractions in this section rather useless. However, it would be
helpful to a person used to thinking in terms of modules and
managers.
With regard to MySQL, I use the term “module” rather loosely. Unlike what one would typically call a module, in many cases it is not something you can easily pull out and replace with another implementation. The code from one module might be spread across several files, and you often find the code from several different modules in the same file. This is particularly true of the older code. The newer code tends to fit into the pattern of modules better. So in our definition, a module is a piece of code that logically belongs together in some way, and performs a certain critical function in the server.
One can identify the following modules in the server:
Server Initialization Module
Connection Manager
Thread Manager
Connection Thread
User Authentication Module
Access Control Module
Parser
Command Dispatcher
Query Cache Module
Optimizer
Table Manager
Table Modification Modules
Table Maintenance Module
Status Reporting Module
Abstracted Storage Engine Interface (Table Handler)
Storage Engine Implementations (MyISAM, InnoDB, MEMORY, Berkeley DB)
Logging Module
Replication Master Module
Replication Slave Module
Client/Server Protocol API
Low-Level Network I/O API
Core API
Interaction of the Core Modules
When the server is started on the command line, the Initialization Module takes control. It parses the configuration file and the command-line arguments, allocates global memory buffers, initializes global variables and structures, loads the access control tables, and performs a number of other initialization tasks. Once the initialization job is complete, the Initialization Module passes control to the Connection Manager, which starts listening for connections from clients in a loop.
When a client connects to the database server, the Connection Manager performs a number of low-level network protocol tasks and then passes control to the Thread Manager, which in turn supplies a thread to handle the connection (which from now on will be referred to as the Connection Thread). The Connection Thread might be created anew, or retrieved from the thread cache and called to active duty. Once the Connection Thread receives control, it first invokes the User Authentication Module. The credentials of the connecting user are verified, and the client may now issue requests.
The Connection Thread passes the request data to the Command Dispatcher. Some requests, known in the MySQL code terminology as commands, can be accommodated by the Command Dispatcher directly, while more complex ones need to be redirected to another module. A typical command may request the server to run a query, change the active database, report the status, send a continuous dump of the replication updates, close the connection, or perform some other operation.
In MySQL server terminology, there are two types of client
requests: a query and a command. A query is
anything that has to go through the parser. A
command is a request that can be executed without
the need to invoke the parser. We will use the term query in the
context of MySQL internals. Thus, not only a SELECT but also a DELETE or INSERT in our terminology would be called a
query. What we would call a query is sometimes called an SQL
statement.
If full query logging is enabled, the Command Dispatcher will ask the Logging Module to log the query or the command to the plain-text log prior to the dispatch. Thus in the full logging configuration all queries will be logged, even the ones that are not syntactically correct and will never be executed, immediately returning an error.
The Command Dispatcher forwards queries to the Parser through the Query Cache Module. The Query Cache Module checks whether the query is of the type that can be cached, and if there exists a previously computed cached result that is still valid. In the case of a hit, the execution is short-circuited at this point, the cached result is returned to the user, and the Connection Thread receives control and is now ready to process another command. If the Query Cache Module reports a miss, the query goes to the Parser, which will make a decision on how to transfer control based on the query type.
One can identify the following modules that could continue from that point: the Optimizer, the Table Modification Module, the Table Maintenance Module, the Replication Module, and the Status Reporting Module. Select queries are forwarded to the Optimizer; updates, inserts, deletes, and table-creation and schema-altering queries go to the respective Table Modification Modules; queries that check, repair, update key statistics, or defragment the table go to the Table Maintenance module; queries related to replication go to the Replication Module; and status requests go to the Status Reporting Module. There also exist a number of Table Modification Modules: Delete Module, Create Module, Update Module, Insert Module, and Alter Module.
At this point, each of the modules that will receive control from the Parser passes the list of tables involved in the query to the Access Control Module and then, upon success, to the Table Manager, which opens the tables and acquires the necessary locks. Now the table operation module is ready to proceed with its specific task and will issue a number of requests to the Abstracted Storage Engine Module for low-level operations such as inserting or updating a record, retrieving the records based on a key value, or performing an operation on the table level, such as repairing it or updating the index statistics.
The Abstracted Storage Engine Module will automatically translate the calls to the corresponding methods of the specific Storage Engine Module via object polymorphism. In other words, when dealing with a Storage Engine object, the caller thinks it is dealing with an abstracted one, when in fact the object is of a more specific type: it is the Storage Engine object corresponding to the given table type. The interface methods are virtual, which creates the effect of transparency. The correct method will be called, and the caller does not need to be aware of the exact object type of the Storage Engine object.
As the query or command is being processed, the corresponding module may send parts of the result set to the client as they become available. It may also send warnings or an error message. If an error message is issued, both the client and the server will understand that the query or command has failed and take the appropriate measures. The client will not accept any more result set, warning, or error message data for the given query, while the server will always transfer control to the Connection Thread after issuing an error. Note that since MySQL does not use exceptions for reasons of implementation stability and portability, all calls on all levels must be checked for errors with the appropriate transfer of control in the case of failure.
If the low-level module has made a modification to the data in some way and if the binary update logging is enabled, the module will be responsible for asking the Logging Module to log the update event to the binary update log, sometimes known as the replication log, or, among MySQL developers and power users, the binlog.
Once the task is completed, the execution flow returns to the Connection Thread, which performs the necessary clean-up and waits for another query or command from the client. The session continues until the client issues the Quit command.
In addition to interacting with regular clients, a server may receive a command from a replication slave to continuously read its binary update log. This command will be handled by the Replication Master Module.
If the server is configured as a replication slave, the Initialization Module will call the Replication Slave Module, which in turn will start two threads, called the SQL Thread and the I/O thread. They take care of propagating updates that happened on the master to the slave. It is possible for the same server to be configured as both a master and a slave.
Network communication with a client goes through the Client/Server Protocol Module, which is responsible for packaging the data in the proper format, and depending on the connection settings, compressing it. The Client/Server Protocol Module in turn uses the Low-Level Network I/O module, which is responsible for sending and receiving the data on the socket level in a cross-platform portable way. It is also responsible for encrypting the data using the OpenSSL library calls if the connection options are set appropriately.
As they perform their respective tasks, the core components of the server heavily rely on the Core API. The Core API provides a rich functionality set, which includes file I/O, memory management, string manipulation, implementations of various data structures and algorithms, and many other useful capabilities. MySQL developers are encouraged to avoid direct libc calls, and use the Core API to facilitate ports to new platforms and code optimization in the future.
Figure 1-1 illustrates the core modules and their interaction.
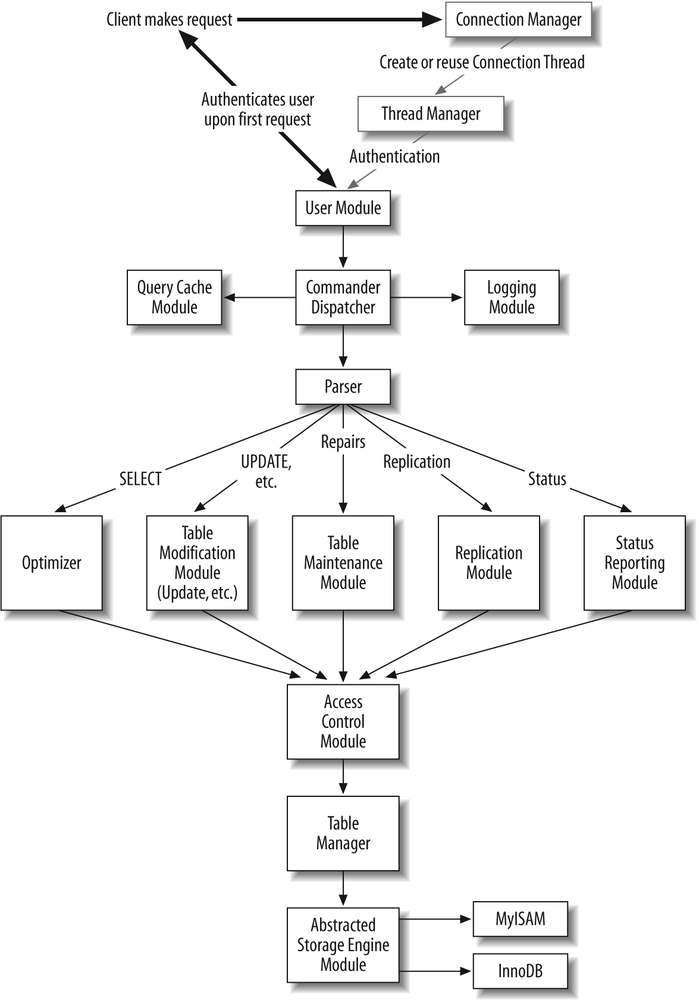
Detailed Look at the Core Modules
We will now take a closer look at each of the components. One purpose of the discussion is to connect the conceptual language used earlier with the actual source. In addition, we will cover the some of the history of each component and try to estimate its future development path.
Frequent references to the source will be made, and you may find it helpful to open the mentioned files in a text editor and locate the function references. This can also be done in a debugger, as shown in Chapter 3. That chapter will also tell you how to get the source code.
Server Initialization Module
The Server Initialization Module is responsible for the
server initialization on startup. Most of the code is found in the
file sql/mysqld.cc. The entry point is what a
C/ C++ programmer would expect: main(
). Some other functions of interest follow. If the file is
not mentioned, the location is
sql/mysqld.cc:
init_common_variables( )init_thread_environment( )init_server_components( )grant_init( )in sql/sql_acl.ccinit_slave( )in sql/slave.ccget_options( )
Although the code found in version 3.22 was never rewritten
from scratch, it has been significantly refactored as new features
were added to MySQL. One big chunk of initialization code that used
to be under main( ) got
reorganized gradually into a number of helper functions over the
lifetime of the code. Additionally, the command line and
configuration file option parsing got switched from the GNU getopt( ) to the MySQL Core API option
parser once it became available in version 4.0.
In version 5.1, a significant portion was added to init_server_components( ) for plugin
initialization.
Overall, this area of the code is fairly stable. Based on the past history, we should anticipate possible incremental additions in the future as new features that require special initialization on startup are added. However, a rewrite of this code is unlikely.
Connection Manager
The Connection Manager listens for incoming connections
from clients, and dispatches the requests to the Thread Manager.
This module is really just one function in
sql/mysqld.cc: handle_connections_sockets( ). However, it
deserves to be classified as a separate module due to its critical
role in the operation of the server. The abundance of #ifdef directives speaks to the challenge
of porting networking code to a variety of operating systems.
Over time, the code evolved somewhat to accommodate quirks in the network system calls of different operating systems. Further changes might be necessary in the future as new ports are attempted, or as the different operating system vendors introduce new quirks into new versions of their products.
Thread Manager
The Thread Manager is responsible for keeping track of
threads and for making sure a thread is allocated to handle the
connection from a client. This is another very small module. Most of
the code is found in sql/mysqld.cc. The entry
point is create_ new_thread( ).
Another function of interest is start_cached_thread( ), defined in the
same file.
One could perhaps consider the THD class defined in
sql/sql_class.h and implemented in
sql/sql_class.cc as a part of this module.
Objects of the THD type are
thread descriptors, and are critical in the operation of most of the
server modules. Many functions take a THD pointer as their first
argument.
The thread management code was significantly reworked in version 3.23 when the thread cache was added. Since then it has not been changed significantly. It is reasonable to expect that it will not receive any significant changes in the future.
However, if we, in our abstraction, consider the THD class
itself as part of this module, we have a different story as far as
changes are concerned. The addition of new features such as prepared
statements, server-side cursors, and stored procedures led to a
significant rework of THD in versions 4.1 and 5.0. It is now a
super-class of the Query_arena, Statement,
Security_context, and Open_tables_state classes, which are also
defined in sql/sql_class.h.
Connection Thread
The Connection Thread is the heart of the work of
processing client requests on an established connection. This module
is also very small. It consists of just one function: handle_one_connection( ) in
sql/sql_parse.cc. However, despite its size, it
deserves to be classified as a module due to its role in the
server.
The code evolved over time, gradually becoming more compact
and readable as various initializations involving THD variables were moved under the
THD class. It is reasonable to
expect that the code will not change much in the future.
User Authentication Module
The User Authentication Module authenticates the
connecting user and initializes the structures and variables
containing the information on his level of privileges. The entry
point for this module is check_connection(
) in sql/sql_parse.cc. However, the
rest of the functionality is found in
sql/sql_acl.cc and
sql/password.cc. Some interesting functions to
examine include:
acl_check_host( )in sql/sql_acl.cccreate_random_string( )in sql/password.cc
check_user( )in sql/sql_parse.cc
acl_getroot( )in sql/sql_acl.cc
The code has been significantly reworked only once, in version 4.1. Due to the possible impact of the changes, MySQL developers waited a while before they attempted the updates in the protocol needed to implement a more secure authentication.
Since then, there have not been many changes to this code. However, with the addition of plug-in capability in 5.1, MySQL developers are planning to add pluggable authentication and roles capabilities, which will require changes in this code.
Access Control Module
The Access Control Module verifies that the client user
has sufficient privileges to perform the requested operation. Most
of the code is in sql/sql_acl.cc. However, one
of the most frequently used functions, check_access( ), is found in
sql/sql_parse.cc. Some other functions of
interest follow, all located in sql/sql_acl.cc
unless otherwise indicated:
check_grant( )check_table_access( )in sql/sql_parse.cccheck_grant_column( )acl_get( )
The code itself has not changed very much since version 3.22. However, new privilege types were added in version 4.0, which somewhat changed the way this module was used by the rest of the code. MySQL developers are planning to add support for roles, which will require significant changes to this module.
Parser
The Parser is responsible for parsing queries and
generating a parse tree. The entry point is mysql_parse( ) in
sql/sql_parse.cc, which performs some
initializations and then invokes yyparse(
), a function in sql/sql_yacc.cc
generated by GNU Bison from sql/sql_yacc.yy,
which contains the definition of the SQL language subset understood
by MySQL. Note that unlike many open source projects, MySQL has its
own generated lexical scanner instead of using
lex. The MySQL lexical scanner is discussed in
detail in Chapter 9.
Some files of interest, in addition to the ones just mentioned,
include:
sql/gen_lex_hash.cc
sql/lex.h
sql/lex_symbol.h
sql/lex_hash.h (generated file)
sql/sql_lex.h
sql/sql_lex.cc
The group of files under sql/ with names starting in item_ and extensions of .h or .cc
As the new SQL features are added, the parser keeps changing to accommodate them. However, the core structure of the parser is fairly stable, and so far has been able to accommodate the growth. It is reasonable to expect that while some elements will be added on, the core will not be changed very much for some time. MySQL developers have been, and sometimes still are, talking about a core rewrite of the parser and moving it away from yacc/Bison to make it faster. However, they have been talking about it for at least seven years already, and this has not yet become a priority.
Command Dispatcher
The Command Dispatcher is responsible for directing
requests to the lower-level modules that will know how to resolve them. It
consists of two functions in sql/sql_ parse.cc:
do_command( ) and dispatch_command( ).
The module kept growing over time as the set of supported commands increased. Small growth is expected in the future, but the core structure is unlikely to change.
Query Cache Module
The Query Cache Module caches query results, and tries to short-circuit the execution of queries by delivering the cached result whenever possible. It is implemented in sql/sql_cache.cc. Some methods of interest include:
Query_cache::store_query( )Query_cache::send_result_to_client( )
The module was added in version 4.0. Few changes aside from bug fixes are expected in the future.
Optimizer
The Optimizer is responsible for creating the best
strategy to answer the query, and executing it to deliver the result
to the client. It is perhaps the most complex module in the MySQL
code. The entry point is mysql_select(
) in sql/sql_select.cc. This module
is discussed in detail in Chapter 9. Some other
functions and methods of interest, all in
sql/sql_select.cc, include:
JOIN::prepare( )JOIN::optimize( )JOIN::exec( )make_join_statistics( )find_best_combination( )optimize_cond( )
As you descend into the depths of the optimizer, there is a
cave worth visiting. It is the range optimizer, which was separate
enough from the optimizer core and complex enough to be isolated
into a separate file, sql/opt_range.cc. The
range optimizer is responsible for optimizing queries that use a key
with a given value range or set of ranges. The entry point for the
range optimizer is SQL_SELECT::test_quick_select( ).
The optimizer has always been in a state of change. The addition of subqueries in 4.1 has added another layer of complexity. Version 5.0 added a greedy search for the optimal table join order, and the ability to use several keys per table (index merge). It is reasonable to expect that many more changes will be made in the future. One long-awaited change is improvements in the optimization of sub-queries.
Table Manager
The Table Manager is responsible for creating, reading, and modifying the table definition files (.frm extension), maintaining a cache of table descriptors called table cache, and managing table-level locks. Most of the code is found in sql/sql_base.cc, sql/table.cc, sql/unireg.cc, and sql/lock.cc. This module will be discussed in detail in Chapter 9. Some functions of interest include:
openfrm( )in sql/table.ccmysql_create_frm( )in sql/unireg.ccopen_table( )in sql/sql_base.ccopen_tables( )in sql/sql_base.ccopen_ltable( )in sql/sql_base.ccmysql_lock_table( )in sql/lock.cc
The code has not changed much since version 3.22 except for the new table definition file format in version 4.1. In the past, Monty has expressed some dissatisfaction with the inefficiencies in the table cache code, and wanted to rewrite it. For a while, this was not a top priority. However, some progress has finally been made in version 5.1.
Table Modification Modules
This collection of modules is responsible for operations such as creating, deleting, renaming, dropping, updating, or inserting into a table. This is actually a very significant chunk of code. Unfortunately, due to the space constraints, this book will not cover it in detail. However, once you become familiar with the rest of the code, you should be able to figure out the details by reading the source and using the debugger without too much trouble by starting from the following entry points:
mysql_update( )andmysql_multi_update( )in sql/sql_update.ccmysql_insert( )in sql/sql_insert.ccmysql_create_table( )in sql/sql_table.ccmysql_alter_table( )in sql/sql_table.ccmysql_rm_table( )in sql/sql_table.ccmysql_delete( )in sql/sql_delete.cc
The Update and Delete modules have been changed significantly in version 4.0 with the addition of multi-table updates and deletes. Some reorganization also happened in Update, Insert, and Delete modules to support prepared statements in version 4.1 and triggers in 5.1. Otherwise, aside from fairly minor improvements from time to time, they have not changed much. It is reasonable to expect that for the large part the code will remain as it is in the future.
Table Maintenance Module
The Table Maintenance Module is responsible for table
maintenance operations such as check, repair, back up, restore,
optimize (defragment), and analyze (update key distribution
statistics). The code is found in
sql/sql_table.cc. The core function is mysql_admin_table( ), with the following
convenience wrappers:
mysql_check_table( )mysql_repair_table( )mysql_backup_table( )mysql_restore_table( )mysql_optimize_table( )mysql_analyze_table( )
mysql_admin_table( ) will
further dispatch the request to the appropriate storage engine
method. The bulk of the work happens on the storage engine
level.
The module was introduced in version 3.23 to provide an SQL interface for table maintenance. Prior to that table maintenance had to be performed offline. In version 4.1, significant changes were made to the Network Protocol Module to support prepared statements. This affected all the modules that talk back to the client, including the Table Maintenance Module. Otherwise, not much has changed since its introduction, and it is reasonable to expect that not much will in the future.
Status Reporting Module
The Status Reporting Module is responsible for
answering queries about server configuration settings, performance
tracking variables, table structure information, replication
progress, condition of the table cache, and other things. It handles
queries that begin with SHOW.
Most of the code is found in sql/sql_show.cc.
Some functions of interest, all in
sql/sql_show.cc unless indicated otherwise,
are:
mysqld_list_processes( )mysqld_show( )mysqld_show_create( )mysqld_show_fields( )mysqld_show_open_tables( )mysqld_show_warnings( )show_master_info( )in sql/slave.ccshow_binlog_info( )in sql/sql_repl.cc
The module has been constantly evolving. The addition of new functionality has created the need for additional status reporting. It is reasonable to expect that this pattern will continue in the future.
Abstracted Storage Engine Interface (Table Handler)
This module is actually an abstract class named handler and a structure called a handlerton. The handlerton structure was added in version 5.1 for plug-in integration. It provides a standardized interface to perform low-level storage and retrieval operations.
The table hander is defined in sql/handler.h and partially implemented in sql/handler.cc. The derived specific storage engine classes will have to implement all the pure virtual methods of this class. It will be discussed in greater detail in Chapter 9.
This module was introduced in version 3.23 to facilitate the integration of Berkeley DB tables. This move had far-reaching consequences: now a variety of low-level storage engines could be put underneath MySQL with a fair amount of ease. The code was further refined during the integration of InnoDB. The future of the module will largely depend on what new storage engines will be integrated into MySQL, and on the way the existing ones will change. For example, sometimes a new feature in some underlying storage engine may require an addition to the abstracted interface to make it available to the higher-level modules.
Storage Engine Implementations (MyISAM, InnoDB, MEMORY, Berkeley DB)
Each of the storage engines provides a standard interface for its operations by extending the handler class mentioned earlier. The methods of the derived class define the standard interface operations in terms of the low-level calls of the specific storage engine. This process and the individual storage engine will be discussed in detail in Chapter 10. Meanwhile, for a quick introduction, you may want to take a look at a few files and directories of interest:
sql/ha_myisam.h and sql/ha_myisam.cc
sql/ha_innodb.h and sql/ha_innodb.cc
sql/ha_heap.h and sql/ha_heap.cc
sql/ha_ndbcluster.h and sql/ha_ndbcluster.cc
myisam/
innobase/
heap/
ndb/
When the storage engine interface was first abstracted (version 3.23), there were only three fully functional storage engines: MyISAM, ISAM (older version of MyISAM), and MEMORY. (Note that the MEMORY storage engine used to be called HEAP, and some of the file and directory names in the source tree still reflect the earlier name.) However, the list grew rapidly with the addition of BerkeleyDB, MERGE, InnoDB, and more recently, NDB for the MySQL Cluster. Most storage engines are still in fairly active development, and we may see some new ones added in the future.
Logging Module
The Logging Module is responsible for maintaining higher-level (logical) logs. A storage engine may additionally maintain its own lower-level (physical or logical) logs for its own purposes, but the Logging Module would not be concerned with those; the storage engine itself takes charge. The logical logs at this point include the binary update log (used mostly for replication, otherwise), command log (used mostly for server monitoring and application debugging), and slow query log (used for tracking down poorly optimized queries).
Prior to version 5.1, the module was contained for the most
part by the class MYSQL_ LOG,
defined in sql/sql_class.h and implemented in
sql/log.cc. Version 5.1 brought a rewrite of
this module. Now there exists a hierarchy of log management classes,
and MYSQL_LOG is a super-class of TC_LOG, both of which are defined
in sql/log.h.
However, most of the work in logging happens in the binary replication log. The classes for log event creation and reading for the binary replication log are defined in sql/log_event.h and implemented in sql/log_event.cc. Both the Replication Master and Replication Slave modules rely heavily on this functionality of the Logging Module.
Significant changes were made to this module with the introduction of replication. Version 5.0 brought on some changes required for XA transactions. Version 5.1 added the capability to search logs as if they were an SQL table, which required a significant refactoring of this code. The binary logging part required significant changes to accommodate row-based replication. At this point it is hard to anticipate where this code is going in the future.
Replication Master Module
The Replication Master Module is responsible for the
replication functionality on the master. The most common operation
for this module is to deliver a continuous feed of replication log
events to the slave upon request. Most of the code is found in
sql/ sql_repl.cc. The core function is mysql_binlog_send( ).
The module was added in version 3.23, and it has not experienced any major changes other than a thorough cleanup to isolate chunks of code into functions. In the beginning, the code had very ambitions development plans for fail-safe replication. However, before those plans could be realized, MySQL acquired NDB Cluster code from Ericsson, and began pursuing another route to the eventual goal of automatic failover. In light of those developments, it is not clear at this point how the native MySQL replication will progress.
This module will be discussed in greater detail in Chapter 12.
Replication Slave Module
The Replication Slave Module is responsible for the
replication functionality of the slave. The role of the slave is to
retrieve updates from the master, and apply them on the slave. The
slave starting in version 4.0 is two-threaded. The network I/O
thread requests and receives a continuous feed of updates from the
master, and logs them in a local relay log. The SQL thread applies
them as it reads them from the relay logs. The code for this module
is found in sql/slave.cc. The most important
functions to study are handle_slave_io(
) and handle_slave_sql(
).
The module was added in 3.23 along with the Replication Master module. It went through a substantial change in version 4.0 when the monolithic slave thread was broken down into the SQL thread and the I/O thread.
This module will be discussed in greater detail in Chapter 12.
Client/Server Protocol API
The MySQL client/server communication protocol sits on top of the operating system protocol (TCP/IP or local socket) in the protocol stack. This module implements the API used across the server to create, read, interpret, and send the protocol packets. The code is found in sql/protocol.cc, sql/protocol.h, and sql/net_serv.cc.
The files sql/protocol.h and
sql/protocol.cc define and implement a
hierarchy of classes. Protocol is
the base class, and Protocol_simple,
Protocol_prep, and Protocol_cursor are derived from it. Some
functions of interest in this module are:
my_net_read( )in sql/net_serv.ccmy_net_write( )in sql/net_serv.ccnet_store_data( )in sql/protocol.ccsend_ok( )in sql/protocol.ccsend_error( )in sql/protocol.cc
In version 4.0 the protocol was changed to support packets up to 4 GB in size. Prior to that, the limit was 24 MB. The Protocol class hierarchy was added in version 4.1 to deal with prepared statements. It appears that at this point most of the problematic areas in the protocol at this level have been addressed, and it is reasonable to expect that this code will not be changing much in the near future. However, MySQL developers are thinking about adding support for notifications.
This module will be discussed in greater detail in Chapter 5.
Low-Level Network I/O API
The Low-Level Network I/O API provides an abstraction for the
low-level network I/O and SSL sessions. The code is found in the
vio/ directory. All functions in this module
have names starting with vio_.
This module was introduced in 3.23, spurred by the need to support SSL connections. Abstracting the low-level network I/O also facilitated porting to new platforms and maintaining the old ports.
Core API
The Core API is the Swiss Army knife of MySQL. It provides functionality for portable file I/O, memory management, string manipulation, filesystem navigation, formatted printing, a rich collection of data structures and algorithms, and a number of other things. If a problem ever arises, there is usually a solution for it in the Core API Module. If there is not, it will be coded up. This module is to a great extent an expression of Monty’s ability and determination to never solve just one problem. It is perhaps the core component of the Miracle of MySQL.
The code is found in the mysys/ and
strings/ directories. Many of the core API
functions have names starting with my_.
The module has always been in a state of growth and improvement. As the new functionality is added, great care is put into preserving its stability and high level of performance. It is reasonable to expect that this pattern will continue in the future.
This module will be discussed in greater detail in Chapter 3.
Get Understanding MySQL Internals now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

