Chapter 1. Embracing Uncertainty
The web platform is Write Once, Cry Everywhere.
â Yehuda Katz
I love the Web. Iâve been making sites for a living since 1999, and I still love the work as much as I did in those crazy days. Iâm not sure how many other folks I know who can say the same thing about their profession. Admittedly, the Web has been very good to me. Iâve been able to travel the world, have written a bunch of articles and a couple of books, and have paid my bills with nothing but a keyboard for the past decade and a half. The thing is, while all that is great and I thank my lucky stars that Iâve had this career, what I really love about the Web is that it made good on its early promise. It might have sounded a little hokey or looked like just hype to fill a five-minute slot on the evening news, but the Web really has managed to connect people in incredible waysâways we couldnât even have imagined 25 years ago. Individuals who would never have had a voice can now broadcast to the world with blogs, YouTube, Twitter, and Facebook. Politicians, filmmakers, video game developers, and anyone else with an idea can tap into the power of individuals to finance their dreams, five dollars at a time. Lessons from the worldâs great universities like Stanford and MIT, as well as lessons made directly for the Web from organizations like Khan Academy, are available for free to anyone in the world who can connect to the Web. With sites like GitHub, taking part in open source software is as easy as firing up a web browser and finding a place to help out with even the most massive open source projects like jQuery, Node.js, or Ruby on Rails.
Itâs only getting better. As more and more people come online, theyâre exposed to these same opportunities and start to feed back into the system with a unique voice: hard work on some open source bug, adding to the coverage of breaking news (say, sharing a photo of a plane landing on the Hudson River), or something as simple as buying a business cat tie on Etsy and turning the wheels of commerce.
Itâs really pretty cool.
I could go on about this for a while and, if I didnât have other plans, Iâd be tempted to do just that. I do have plans though, so Iâm going to resist the impulse.
This chapter will introduce the core concept of uncertainty in the context of web development. From there, weâll look at where we came from with Microsoftâs monoculture in the early 2000s, and then weâll look in depth at where we are today. Throughout, weâll look at what the factors that have gotten us here can teach us about the future of the Open Web Platform and related ecosystem.
You wonât be an absolute expert on everything the Web has to offer just by reading this chapter, but you should have a much better sense of where weâve been, where we are, whatâs on the horizon, what some current issues are, and what kinds of things might surprise us in the future.
Embrace Uncertainty
Along with the landscape, the general philosophy of making websites and applications has slowly shifted over the past decade or so. Itâs moved gradually from the rigorously defined boundaries of the Microsoft monoculture to the fluid environment we have today. Design approaches like responsive web design, technology patterns like progressive enhancement, and libraries like Modernizr are all much better suited to todayâs Web than anything that came before. Fixed-width sites with âbest viewed withâ banners that broke without third-party plug-ins like Adobe Flash or failed to function if the user visited with a new, novel web browser (no matter how powerful) donât have to exist anymore. Weâre better than that.
Thatâs a good start.
The thing is, although weâve mostly shifted away from static 960px grids and all of the other baggage that came with the limited universe, the shift has been isolated to islands of innovation and has generally only happened in reaction to outside stimuli. Every change in the browser and device landscape has sent people scurrying, trying to solve problems caused by new features, browsers, or form factors. Although there have been some truly flexible solutions crafted for these issues, there are just as likely to be a newly revised set of inflexible guidelines put up, only to be revisited the next time the landscape shifts. Itâs time to get ahead of the curve and do our best to cure the disease and not just treat the symptoms.
Itâs time to embrace uncertainty.
Embracing uncertainty means that we need to make the final leap away from the search for absolutes in order to appreciate the Web for what it actually is. As weâll examine in this chapter, itâs a place where a wide range of devices running a wide range of web browsers in the hands of many different kinds of people are all trying to find their way to something that matters to them. Whether itâs a farmer in Africa trying to figure out the score of the latest Manchester United match, a banker in Hong Kong trying to get a price for Bordeaux futures, or a small business owner in the United States setting up an Etsy shop, the Web is making important connections for people, and we need to help them on their way.
So how to do it?
Weâll start by looking at specific recommendations beginning with the next chapter, but even before you start to look at the particulars, you can start to change the way you look at the process.
The initial step is to understand, from the second that you start a site design, that you (probably) canât control what devices, browsers, and form factors will be ingesting your content. Even better, if you can let go of the desire to control what devices, browsers, and form factors are accessing your site, youâll be even happier with your results. While some organizations and certain applications can dictate specific browser and OS versions, youâre probably not going to be able to do so on your end. Unless youâre in control of your usersâ machines or are offering something no one can get anywhere else, you should be trying to satisfy as many browsers and devices as you possibly can.
âBut My Client Doesnât Careâ
A common issue when people start to embrace anything new in the web development sphere, whether itâs a formal usability program, an accessibility initiative, or a web performance optimization project, is getting buy-in from clients or internal stakeholders who might not immediately understand the benefit of something new and unfamiliar. I imagine much the same reaction to the concepts present in this book. Iâve certainly seen my share of pushback when sharing some of the ideas Iâll be discussing, so I expect other people will see the same thing. All you can do is do what Iâve done: make your case with enthusiasm and data to back it up. You canât force people to change their ways, but if you present good data with conviction, youâve got a better chance than if you sit idly by and do nothing.
The next, most important step is not only to accept that you canât control the browser and device environment, but to embrace the ecosystem for what it isâa sign that the Web is a healthy platform. Tens of thousands of browser/device/OS combinations is a feature of the Web, not a problem.
I talk to a lot of people, and there are plenty of complaints about the Web as a platform. Iâm not talking about specific complaints about specific features. Iâm talking about complaints about the Web itself.
Many Java/C/C++ developers just shake their heads at the idea that code written for the Web can be executed in so many different environments and can have just as many different results. To them, the Web is just nuts. On the other end of the spectrum, many web developers have their favorite browsers, great hardware, new smartphones, and everything else gets the short end of the stick. These are the folks who go over the top in GitHub issues with their hatred of Internet Explorer, test 99% of the time in Chrome, and are actively wishing for WebKit to be the only rendering engine on the Web because it would make things so much easier for them.
Donât be either extreme.
Instead of worrying about the fracture in the Web and wishing that it was something else, accept the Web for the blessing that it is. And it is a blessing. Because the core technology can run, unaltered, on billions of devices in the hands of billions of people, you have immediate access to all of those billions of people and all of those billions of devices.
How great is that?
From Microsoftâs Monoculture to Todayâs Healthy Chaos
In the early 2000s, there was basically one browser, one platform, and one screen resolution that mattered. You could test the experience of the vast majority of your users, with excellent fidelity, simply by running Windows XP with Internet Explorer 6 and switching between a couple of different screen resolutions (i.e., 800 Ã 600 and 1024 Ã 768 pixels). Add in Internet Explorer 5 and 5.5, and you could hit, by some estimates, more than 95% of the Web. In the end, Internet Explorer held market share of near or above 90% for most of the first half of the 2000s.
To Be Fair, Internet Explorer Was the Good Browser in 1999
Whatever you might think of their business practices at the time (and the courts certainly didnât take kindly to them), if you had to choose to develop for any browser in the late dot-com era, it was going to be Internet Explorer. Far from being the butt of jokes, Internet Explorer versions 4 through 6 were, at the time, each the best available browser by a wide margin. Iâve said it many times, and Iâll say it again here, the worst major browser ever was Netscape 4. Internet Explorer 6 may have overstayed its welcome by about seven years, but Netscape 4 was simply born bad.
Whatâs more, beyond simply being the most powerful browser, the Internet Explorer team consistently pushed out powerful features and APIs that still resonate on the Web today. For one example, the XMLHttpRequest object, which serves as the foundation of modern frontend development, was an Internet Explorer innovation. It really doesnât get any more important than that, in terms of single innovations that have changed the way that we architect web solutions.
For more perspective on what Internet Explorer brought to the Web in those early days, check out my blog post, âSome Internet Explorer Innovations You Probably Forgot About While Waiting for IE6 To Dieâ and Nicholas Zakasâ blog post, âThe Innovations of Internet Explorer.â
Slowly, from the height of Internet Explorerâs dominance (reached in the middle of 2004), things began to turn. It really started with Firefox, the heir to the Netscape mantle, chipping away at Internet Explorerâs dominance by presenting an independent, standards-compliant alternative. With Opera revamped for modern development in 2003 (it had previously been great for CSS and weird for JavaScript), the 2003 release of Apple Safari, and 2008 release of Googleâs Chrome browser, Internet Explorer had real competition on multiple fronts, each taking a chunk out of the giant until it was eventually toppled as not only the dominant browser version, but the dominant browser family in May 2012.
Whatâs more, while all that desktop competition was heating up, an entirely new front in the browser wars opened up with the unprecedented growth of the mobile Web. With the launch of the iPhone and iPad and the dominant growth of phones powered by Googleâs Android operating system that followed, both the absolute number of users and the number of devices used to connect to the Web per user grew.
Additionally, browser vendors have almost universally (with Apple being the only holdout) instituted a policy automatically pushing updates. Gone are the days of new browser versions shipping every couple of years alongside a new OS update. This new commitment from the browser vendors has allowed us to add new web platform features at a breakneck pace. It has also led to a spread of browser versions, as different organizations and individuals move to the latest version at their own speed.
So, instead of having a couple of machines dedicated to testing and getting 95% coverage, anyone who really pays attention to this stuff can have a testing lab with 50 or more devices and still struggle to cover the same high proportion of the Web that was possible during Microsoftâs heyday.
If Hollywood were going to do an edgy reboot of the âRip Van Winkleâ story, they might as well use a web developer, because a developer taking a nap under his desk (as I often threaten to do) in 2004 and waking up today would be bewildered by the changes in the landscape. Imagine a cockeyed Owen Wilson asking, âGoogle has a browser?â Thereâd be a lot of that kind of thing.
I mean, Iâve been paying close attention the whole time, and the changes are just nuts to me.
Letâs make some sense of it all.
Where We Are Right Now
I donât think youâd find anyone outside of Redmond who yearns for the days when Internet Explorer was basically the whole Web, though I canât help but think thereâs a little bit of âbe careful what you wish forâ in the current state of affairs. It wasnât quite as exciting and nowhere near as powerful, but it was much easier to wrap your head around the ecosystem in 2003. These days, itâs sometimes hard to wrap your head around individual topics. Because itâs so complicated, this section is going to focus on making general sense of the current ecosystem.
Plainly stated, the number of variables at play in terms of screen resolution, pixel depth, browser capabilities, form factors, and humanâcomputer interface input options are practically infinite. You can start to tally up the possibilities as we go through the details of the various sections. âLetâs see, weâve got 10 major browser versions; 50 different screen resolutions between 340px à 280px and 3840px à 1080px; pixel densities in a spectrum from from 72dpi up past 300dpi.â Add to that the incredible growth of new web-enabled devices and related mobile-driven penetration of previously untapped web markets, like most of Africa, and the idea that you can create any finite set of guidelines and still produce quality web experience for the largest possible audience is pretty much crazy.
On with the show.
Browsers
Every discussion of the state of the web platform begins with the web browser. These days, the browser landscape is robust, with as much competition as weâve ever had (see Figure 1-1). Theyâre split across several browser vendors and muliple version numbers, but there are basically four broad streams in the world of browser development. At the heart of each of these streams is a layout engine. For the uninitiated, the layout engine is the core code in a web browser that defines how markup and styles are rendered.

These streams are as follows:
- Microsoftâs Trident, which powers Internet Explorer
- After twiddling their thumbs for the better part of a decade with Internet Explorer 6 eventually dragging the whole Web down, Microsoft is thankfully back in the business of making good web browsers. Older versions of Internet Explorer (6â8) are still a pox on the Web. IE9 and above are considered âmodern browsers,â which is shorthand for something that most people are happy to code for. Trident also shows up in other Windows-based applications as a ready-made web browsing component; so if you ever find yourself trying to debug some Windows app that also allows you to browse web pages, try to figure out what version of Trident itâs running.
- Browsers based on the WebKit open source project
- This used to be a larger category (more on that in a second), but it still includes Appleâs Safari on the desktop, iOS Safari, older versions of Googleâs Chrome, the Android Browser, and dozens of other niche browsers, including those running on BlackBerry devices, pre-Microsoft Nokia devices, and the Playstation 3 and 4. For many years, WebKit led the standards charge, and it still will play a strong role in standards efforts going forward.
- Browsers based on the Blink open source project
- Forked from WebKit in 2013, Blink is the layout engine behind the latest versions of Chrome and Opera. With both companies having a heavy focus on the standards process, Blink might be the gold standard for cutting-edge web development moving forward.
- Mozillaâs Gecko, which runs under the hood of Firefox
- As an independent voice not tied to a large corporate entity (Mozilla is a nonprofit organization), Gecko is both important for driving standards and as an independent foil to the more corporate stakeholders in the development of the web platform
In addition to the rendering engine, each of these streams has an associated JavaScript engine, which completes the core platform functionality for each when packaged as a web browser. These JavaScript Engines are as follows:
- Chakra
- This is used in Internet Explorer. It is a massive improvement from the engine running in legacy versions of the browser. Interestingly, it compiles scripts on a separate CPU core, parallel to the web browser.
- SquirrelFish Extreme/Nitro
- Itâs the JavaScript engine for WebKit.
- V8
- This is the JavaScript engine used in Google Chrome and Blink-derived versions of Opera. Itâs also at the core of Node.js, and it is a very influential project. V8 was the first JavaScript engine to compile JavaScript to native code before executing it, increasing performance significantly from previous engines.
- SpiderMonkey
- Itâs the JavaScript engine in Firefox. The heir to the original JavaScript engine, it is written by JavaScriptâs creator Brendan Eich.
These four streams are very competitive on both JavaScript and rendering fronts, which is why working with modern browsers is now generally a pretty good experience. And although there are differences between browsers in each stream (both based on when the specific browser version was created and on downstream changes made to the code for specific vendorsâ needs), knowledge of each stream can serve as a shorthand for what to expect with each browser based on the stream.
Of course, all of these streams break down further into specific browsers. Thatâs where things get really complicated. Itâs possible to keep track of the various streams, but itâs much tougher to deal with specific browser versions.
Depending on your geographical focus or vertical, there are probably 6â10 general browser families you might have to pay attention to on a given project, and each of them might contain two or more specific active versions:
- Internet Explorer
- Depending on your market, you might have to test against six versions of Internet Explorer (6â11). After the dormancy of the mid-2000s, IE is basically releasing a new version every year, allowing for a much faster introduction of new features. Microsoft has also joined the automatic update brigade, which is a welcome change after years of a very conservative update policy.
- Firefox
- Most people running Firefox are on the automatic upgrade cycle, so itâs generally OK to simply test against the latest version, although if youâve got an âenterpriseâ market it might be useful to test against the Extended Support Release. Firefox is on a short release cycle, releasing multiple new versions every year.
- Chrome
- Most people running Chrome on the desktop are automatically updated to the latest version. Chrome pioneered the short browser release cycle.
- Safari
- Versions 5â8 can be seen in the wild. Major releases are slower than other browsers, although they do bundle features into minor releases.
- Opera
- Most people running Opera on the desktop are automatically updated to the latest version. Opera is on a rapid release cycle.
- Chrome (mobile)
- There are mobile versions of Chrome available for iOS and Android 4.0+. In a twist that perfectly sums up how complicated the browser universe is, Chrome for Android uses Blink, and Chrome for iOS uses WebKit. Thereâs also a Samsung-based fork of Chrome that accounts for something like 25% of mobile Chrome traffic.
- iOS Safari
- Safari on iOS is updated along with the OS, so you have to look at iOS version numbers to assess what versions are in play. This is iOS 5â8 at its broadest. (iOS 5.1.1 is the highest available for the first-generation iPad.)
- Opera Mini
- If you donât pay attention to the mobile browser space, it might surprise you how popular this browser is on mobile devices. Data is sent through a proxy server and compressed, saving you time and data. There are a lot of versions of this out there. You will see examples from the 4, 5, and 7* versions in the wild.
- Opera Mobile
- This is a blink-based browser for Android.
- Android Browser
- This is the default browser on Android phones. Like iOS Safari, it varies with the Android version and can differ from device to device, because anyone from carriers to device manufacturers has access to the code before it gets into your hand. There could be dozens of different variations out there.
- IE Mobile
- Based on Trident, versions 9 (appearing on Windows Phone 7), 10 (Windows Phone 8), and 11 (Windows Phone 8.1) are in the wild.
- UC Browser
- This is a mobile, proxy browser based on the WebKit rendering engine. Itâs popular in China, India, and other emerging markets.
Thatâs a pretty daunting list. It was only a few years ago that we would point to the Yahoo! Graded Browser Support Table and call it a day. Now you donât want to blink, lest some other entry show up on the back of some new OS or handset.
Before we move on from here, itâs worth getting a general sense of the popularity of each of these browsers and of the browser families. Youâre going to want to make decisions based on your needs, but you canât do that without having plenty of information at your disposal.
Letâs take a look at a couple of snapshots of the browser market as of March 2014. First, letâs look at desktop and tablet browsers with Table 1-1 and the associated bar chart in Figure 1-3. These are good numbers, but are skewed by the fact that StatCounter isnât as strong in some places (e.g., China), as it is in others. That manifests itself most prominently in the absence of IE6 from these charts (itâs bundled into âotherâ), where it should at least gain a mention because itâs still a big browser in China. With that caveat aside, it is useful to take a look at the spread across individual browser versions. The biggest negative on the list is probably IE8 still hanging out at 6.2%. Iâm sure 360 Safe Browser is going to have some of you confused as well. Itâs a Chinese browser with a publicized security focus (that might actually be loaded with spyware) based on Trident.
| Browser | Market share % |
Chrome (all) | 43.66 |
Firefox 5+ | 18.27 |
IE 11.0 | 8.27 |
IE 8.0 | 6.2 |
Safari iPad | 5.19 |
IE 10.0 | 3.83 |
IE 9.0 | 3.5 |
Safari 7.0 | 1.76 |
Android | 1.18 |
Safari 5.1 | 1.05 |
Safari 6.1 | 0.89 |
360 Safe Browser 0 | 0.84 |
Opera 15+ | 0.69 |
Other | 4.66 |
Source: http://gs.statcounter.com/ | |
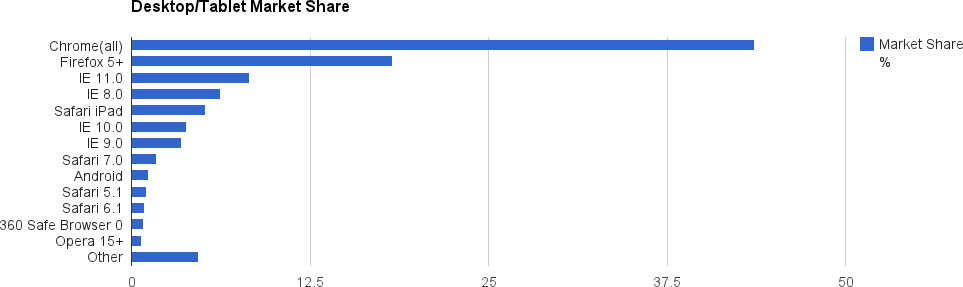
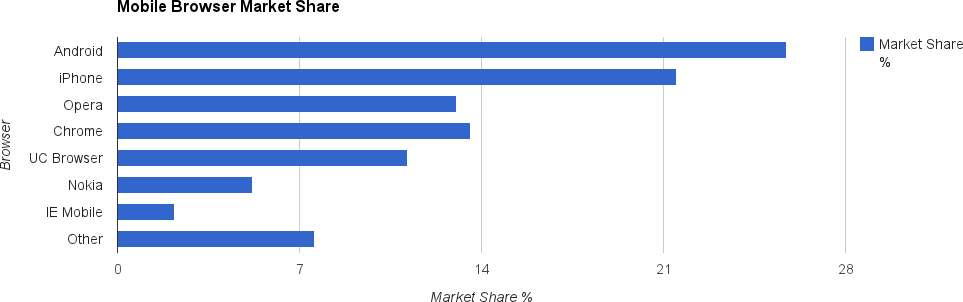
Table 1-2 and the associated bar chart in Figure 1-2 show the mobile market. For many people, the fact that the stock Android browser, Chrome, and Safari on the iPhone donât make up 100% of the market might come as a shock, but itâs true. Unless youâre really paying attention, youâre probably missing 50% of the mobile browser market in your testing. Youâre not alone. I asked on Google Plus how many people had ever tested with Opera mobile, and two people said yes. I asked at a table of speakers at a jQuery conference how many had ever heard of UC Browser, and no one had.
| Browser | Market share % |
Android | 25.74 |
iPhone | 21.5 |
Opera | 13.03 |
Chrome | 13.59 |
UC Browser | 11.17 |
Nokia | 5.21 |
IE Mobile | 2.19 |
Other | 7.57 |
Source: http://gs.statcounter.com/ | |
Itâs important to know whatâs out there, and itâs imperative to test against as many of these browsers as possible, but itâs rarely useful, when youâre sitting down to develop a site, to fixate on the ins and outs of any one particular browser or to target code specifically for certain browsers or browser versions. For starters, itâs an overwhelming list, and if you try to fork your code based on every browser and version, youâll end up playing the worldâs worst game of Whack-a-Mole. Instead, for development, you need to think in terms of features. This concept, feature detection (versus browser detection) has been a common concept in web development for a long time, but now itâs more important than itâs ever been. Weâll talk more about how to leverage feature detection (and when to make an exception and fall back to browser detection) in Chapter 3, but the core concept is not to ask âWhat browser is this?â Itâs to ask âDoes your browser support the feature I want to use?â
That will help you if some new, suddenly popular browser makes an entry into this list, sometime in the future. Which is probably going to happen sooner than you think.
Please Upgrade Your Browser
One ironic way that browser detection bit developers in the past was a rampant practice in the early 2000s. Some of those sites are still around, so they can serve as a snarky reminder to focus on features and not browsers. Because Internet Explorer was so dominant and Netscape 4.*, the only other browser with any market share at all, was so horrible, it was common for people to sniff for Internet Explorer and leave an upgrade message for people running basically anything else. You will still see these warnings on some pages, except these days they are telling you to upgrade the latest Chrome or Firefox to Internet Explorer 6.
The Open Web Platform
Although the Web has always been a wonderfully messy and vibrant place, where sites can go from a sketch on the back of a napkin to a headline-making enterprise with a billion-dollar valuation in the course of a few months, the World Wide Web Consortium (W3C), the organization responsible for the standards that the Web is built upon, often moves more like itâs overseeing transatlantic shipping in the 1800s.
If, in the early 2000s, you were the kind of person who paid attention to their activities, you could wait for years for anything interesting to happen. There was lots of discussion, lots of tweaking of existing specifications, and really not much else. Couple this with Microsoft shuttering Internet Explorer for lack of competition and slow (occasionally contentious) movement at ECMA, the organization responsible for the ECMAScript (the language commonly known as JavaScript) specification, and you can see how things stagnated.
Letâs look at some dates to give you a sense of just how bad it was:
- In December 1997, the W3C published the HTML4.0 specification.
- In early 1998, they published the XML 1.0 Standard.
- In May 1998, the Cascading Style Sheets (CSS) level 2 specification was published.
- The ECMASCript Specification version 3.0 was released in December 1999.
- XHTML 1.0, the specification that redefined HTML as a subset of XML was published as a recommendation in January 2000.
- Internet Explorer 6 was released on August 27, 2001.
- SVG 1.0 became a W3C Recommendation on September 4, 2001.
After that, not much happened.
âThingsâ happened, of course. Meetings were held, road maps were prepared, and progress, of a sort, toward the Web of the future was visible in incremental revisions to standards. This orderly progress, to someone with only a passing interest in these sorts of things, probably seemed like a positive trend.
I sometimes felt like I knew everything about web specifications at the time, although I didnât really. Instead of spending time learning about new things on the horizon, as there werenât any, I used to do deeper dives into the existing specifications. I actually had binders with printouts of the xHTML1.0, HTML4.0, and CSS2 specifications. I could do that because things moved so slowly, those printouts stayed valid for a really long time.
The reality on the Open Web was different than any perception of âorderly progress.â Out in the real world, the Web was busy taking over. Fueled by a heady mixture of popular interest, maniacal hype, gobs of money, and (for many people) an honest belief in the Web as a platform with the power to change the world, the Web was very quickly being pushed and pulled in directions the standards bodies never dreamed of when they were drafting their documentation. Compare the needs of the Web of the mid-1990s, when these standards documents were being written, to the Web of the dot-com era, and youâll see why so many problems fell to the creativity of web developers to solve. People had to be clever to bolt together solutions with the existing, somewhat limited, set of tools that were available.
Still, all the cleverness in the world wasnât enough to get around the main limitations of the standards and the browsers themselves. Something as simple as generating rounded corners for an HTML element was a topic worthy of dozens of articles, blog posts, and probably a patent or two.
Other topics were either practically impossible or took many years to solve. The many creative, technically complicated solutions to serving custom fonts over the Web fell into this category. Leveraging third-party technologies like Flash, Vector Markup Language (VML), and eventually Canvas, libraries like cufón and SIFR brought custom type to the Web through heroic individual effort and at the cost of third-party dependencies (and questionable licensing legality). This meant that even developers who believed in the Open Web Stack had to rely on closed technologies to simply get a corporate typeface onto the Web in a maintainable way.
Something had to give.
Web standards, Flash, and the rebirth of the Open Web Platform
All that really needs to be said about the immediate effectiveness of the late 1990s standards work is that the era that directly followed it was dominated by Adobe Flash as the platform of choice for anything even remotely interesting on the Web. Everything from financial dashboards and video delivery to the slickest marketing work was handled by Adobeâs ubiquitous Flash plug-in. Unfortunately for people who believed that the Web was most effective when it was built on top of open standards, Flash provided a far richer platform for developing serious interactive applications and âcoolâ effects for marketing sites.
It became the de facto standard for deep interaction on the Web.
The core web technologies were basically ignored. The overall perception was that JavaScript was a toy language used for occasional form validation, CSS was poorly understood and even more poorly implemented in web browsers, and HTML was most useful as a dumb container for serving Flash files.
Throughout this dark period, there were still people championing these technologies and to a very large extent itâs down to them that weâre where we are today. From organizations like the Web Standards Project (WaSP) and the wildly influential mailing list/online magazine A List Apart, and through the work of individuals like Peter Paul Koch and Eric Meyer, the fundamental technologies that drove the Web were being reevaluated, documented, and experimented with at a furious pace. Quietly, invaluable work was being done documenting browser behavior, crafting best practices, and solving implementation issues. Although it wasnât the most fashionable work, there was plenty of activity using open standards in creative ways. That research and code served as the foundation for the revolution that would follow and change the course of the Web.
That revolution had two main drivers. One took place under the eye of the W3C itself, and the other came straight from the front lines.
The first event was the formation of the Web Hypertext Application Technology Working Group (WHATWG). The second was the astounding adoption of Ajax-based web development.
The WHATWG
The WHATWG was born at the W3C Workshop on Web Applications and Compound Documents in June 2004. This W3C meeting was organized around the new (at the time) W3C activity in the web application space and included representatives from all the major browser vendors, as well as other interested parties. There, in the first 10-minute presentation of session 3 on the opening day of the two-day event, representatives from Mozilla and Opera presented a joint paper describing their vision for the future of web application standards. This position paper was authored in response to the slow general pace of innovation at the W3C and the W3Câs focus on XML-based technologies like xHTML over HTML. It presented a set of seven guiding design principles for web application technologies. Because these principles have been followed so closely and have driven so much of whatâs gone into the specifications over the last several years, theyâre repeated in full here. Some were driven by the mistakes of xHTML (âUsers should not be exposed to authoring errorsâ), and others were driven by good sense (âpractical useâ and the desire for an âopen processâ). All have been visible in the process in the intervening years. The specifications are as follows:
Backwards compatibility, clear migration path
Web application technologies should be based on technologies authors are familiar with, including HTML, CSS, DOM, and JavaScript.
Basic Web application features should be implementable using behaviors, scripting, and style sheets in IE6 today so that authors have a clear migration path. Any solution that cannot be used with the current high-market-share user agent without the need for binary plug-ins is highly unlikely to be successful.
Well-defined error handling
Error handling in Web applications must be defined to a level of detail where User Agents do not have to invent their own error handling mechanisms or reverse engineer other User Agentsâ.
Users should not be exposed to authoring errors
Specifications must specify exact error recovery behaviour for each possible error scenario. Error handling should for the most part be defined in terms of graceful error recovery (as in CSS), rather than obvious and catastrophic failure (as in XML).
Practical use
Every feature that goes into the Web Applications specifications must be justified by a practical use case. The reverse is not necessarily true: every use case does not necessarily warrant a new feature.
Use cases should preferably be based on real sites where the authors previously used a poor solution to work around the limitation.
Scripting is here to stay
But should be avoided where more convenient declarative markup can be used.
Scripting should be device and presentation neutral unless scoped in a device-specific way (e.g. unless included in XBL).
Device-specific profiling should be avoided
Authors should be able to depend on the same features being implemented in desktop and mobile versions of the same UA.
Open process
The Web has benefited from being developed in an open environment. Web Applications will be core to the web, and its development should also take place in the open. Mailing lists, archives and draft specifications should continuously be visible to the public.
The paper was voted down with 11 members voting against it and 8 voting for it.
Thankfully, rather than packing up their tent and going home, accepting the decision, they decided to strike out on their own. They bought a domain, opened up a mailing list, and started work on a series of specifications. They started with three:
- Web Forms 2.0
- An incremental improvement of HTML4.01âs forms.
- Web Apps 1.0
- Features for application development in HTML.
- Web Controls 1.0
- A specification describing mechanisms for creating new interactive widgets.
Web Controls has since gone dormant, but the other two, Web Forms and Web Apps, eventually formed the foundation of the new HTML5 specification.
Score one for going it alone.
As was mentioned, theyâve stuck to their principles over the years. Arguably, the most important of these principles is the very open nature of the standards process in the hands of the WHATWG. Before the birth of the WHATWG, the standards process and surrounding discussion took place in a series of very exclusive mailing lists, requiring both W3C membership (which costs thousands or tens of thousands of dollars, depending on the size and type of your organization) and then specific inclusion in the particular Working Group under discussion. There were public discussion mailing lists, but those were far from where the real action was taking place. It was a very small group of people, operating in a vacuum, completely separated from the people working on these pivotal technologies on a day-to-day basis.
Instead of that exclusionary approach, the WHATWG made sure its activities were taking place in the open. If you subscribed to the mailing list and commented, you were suddenly part of the solution. This has led to vibrant, high-volume discussion feeding into the standards process. There are still many people involved who are far removed from the day-to-day business of making websites and applications, but thereâs also a constant stream of input from people who are knee deep in building some of the biggest sites on the planet.
Itâs not perfect, of course. They werenât kidding when they stated âevery use case does not necessarily warrant a new feature.â If you follow the WHATWG mailing list, it seems like not a month goes by without someone proposing a new feature, complete with valid use cases, and failing to get their proposal approved. This can end up being frustrating for all involved, and the mailing list has been known to get heated from time to time. For one example, months of discussion around a standardized mechanism to control the way scripts were loaded and executed went nowhere despite well-reasoned arguments from a number of high-profile sources. The discussion there has since restarted, so maybe this time it will stick. The lengthy, and oftentimes acrimonious, discussion of a solution for responsive images stretched out over a period of four years with a peaceful resolution only showing up recently, so there is hope.
Everyone isnât happy all the time, but the process works. Even with the hiccups and flame wars, things move much more quickly than they did at any period before the WHATWG was founded, and thereâs less confusion about how the decisions are made, even if people donât agree with them.
Ajax
On February 18, 2005, Jesse James Garrett, cofounder and president of design consultancy Adaptive Path, wrote an article entitled âAjax: A New Approach to Web Applications.â In it, he described a new, at the time, trend in apps like Gmail and Google Maps that focused on smooth application-like experiences. He coined the term Ajax to describe it and called the pattern âa fundamental shift in whatâs possible on the Web.â
He was certainly right.
Garrettâs post didnât invent the technology pattern, of course. It had actually been growing organically for several years, with the fundamental technologies in place as early as 2000. What the post did do was give focus to the trend with an intelligent, easy-to-understand definition and a very marketable name. With that focus, the pattern went from a vague collection of sites and apps tied together by a common design and interaction feel and technology stack, to being something that you could easily market and discuss. Instead of saying âI want to build a fast app that doesnât rely on multiple page loads like Google Maps using standard web technologies,â you could say âI want this app to use Ajaxâ and people would instantly get what that meant.
The immediate popularity of Ajax meant that a number of very intelligent developers started to take a look at the infrastructure for developing web applications in a cross-browser way. Before Ajax, standards-based development was mostly focused on markup and style, which was valuable when doing content sites, but didnât provide the full solution when approaching the complexities of a browser-based application. After Ajax, standards-based development included a dynamic, interactive component that drew engineers from other programming disciplines in droves. There were a lot of problems to solve, and it seemed like every company in America was looking for someone to solve them. Libraries like Prototype, Dojo, MooTools, and eventually jQuery rose up to fill in the gaps between the various browser implementations. These libraries, becoming more and more robust, eventually began to feed back into the standards process with common patterns being brought out of libraries and into the browser.
Tracking the Open Web Platform today
One of the great challenges of working on the Web today is keeping abreast of the changes in the standards space. This section will give you a quick guide to the current standards development landscape and will offer some hints on how to keep up to date with developments in the standards landscape.
The current standards development landscape generally breaks down as follows:
- HTML and related APIs
- Main development of whatâs referred to as the âliving standardâ happens with the WHATWG. The mailing list archives are also online. This work is an ongoing extension of the work done for HTML5. A so-called âsnapshot specification,â HTML5 is currently a candidate recommendation at the W3C.
- CSS
- CSS development has been broken down into smaller modules. CSS 2.0 was a monolithic specification that covered everything to do with CSS. For CSS3, the decision was made to break down the specification into specific features. This means there are some modules further along in the development process than others. The W3Câs big list of modules is available here.
- ECMAScript
- The ECMAScript mailing list is where all the action happens.
With the parallel tracks of the WHATWG kick-starting the standards process and Ajax making the intersection of HTML, CSS, and JavaScript some of the most important technical real estate in the world, the standards space went into overdrive and browser vendors started tripping over themselves to implement those newly minted standards.
On the surface, this is greatâwe get new toys!
There are a couple of downsides. One is that itâs basically impossible to keep track of everything. For my part, I actively follow the development of the ECMAScript specification and the work of the WHATWG. That means I have to rely on other people to point out the cool work being done in CSS. And, even ignoring CSS, itâs pretty easy to miss a couple of weeks or even a month or two of discussion on the mailing lists. You go away for vacation, and the whole thing might be turned upside down by the time you get back.
Another downside is that people, in the rush to implement new features in the browser or to experiment with them on the Web, sometimes make mistakes. Whether itâs a poorly vetted specification; the well-meaning, but awkward decision to prefix experimental CSS features; the tendency of ânewâ HTML5 features to occasionally go away (like the loss of the hgroup element or the disappearance and subsequent reappearance of the time element); or the decision to implement an alpha feature in a site meant for human consumption, only to see it break in a later version of the target browser; the rush for the new and shiny has had its share of casualties over the past few years.
Navigating this space is important, though. As youâll see in one example in the section on responsive images in Chapter 6, following the standards discussion, learning about potential JavaScript solutions, and implementing standard stable patterns can produce great long-term benefit for your site. Itâs just sometimes tough to figure out when something is really stable, so the closer you can get to the discussions, the better. Not many people have the time needed to be involved in even a single feature discussion as an active participant, forget about the mailing list as a whole, but you really should have time to at least monitor the subject lines, checking in where applicable.
The ECMAScript specification is also being worked out in public. If I only had time to detail all the ins and outs of the ECMAScript-shaped black hole you can see on the standards timeline between the third edition in December 1999 and the release of the fifth edition 10 years later. The fact that they completely skipped over the fourth edition because it ended up being too contentious a process is probably all you really need to know. The good news is, the TC39 committee has patched up its differences, invited a bunch of workaday developers into the standards body, and generally been pretty great for the past few years. Theyâre hard at work finalizing the sixth edition (aka ES6), which promises to be a revolutionary step forward in the development of the language. Work on ES7 and ES8 is also underway. Work on the ES6 specification also happens on a high volume, public mailing list and because of the way that the body is structured itâs much easier for them to invite individual experts onto the committee.
Keep Your Résumé Handy
If you work somewhere that doesnât allow you even enough time to monitor the subject lines on these mailing lists and youâre still relied upon to stay, to quote many a job description, âup to date with the latest technologies,â then it might be time to have a talk with your boss. If there was any time to stay ahead of the curve, itâs right now.
Connection Speeds and Quality
Iâve been interested in web performance since the 1990s. We didnât really have a name for it back then. I just remember reading that the optimal speed of a humanâcomputer interaction is less than 100ms and thinking âon the Web, we canât do anything that fast.â Download speeds alone were bad enough that 100ms was a tough task for even the simplest sites.
Unfortunately, even though download speeds and hardware specs have greatly improved, because developers and designers have consistently pushed the envelope and designed for higher-performance hardware and faster connections than is the current norm, weâre still seeing some of the same issues we did back then. With the addition of sketchy mobile networks into the mix, the question of connection speeds and bandwidth is still a serious issue.
Weâve got a more nuanced look at what makes a fast site these days and have dozens of tools at our disposal to figure out whatâs right or wrong with our pages. Thatâs great. But until we change the way we approach making web pages and design to the reality of our audience and not what we wish their reality to be, performance is never going to be what it should be.
For one example, the grand master of web performance, Steve Souders, did some research and found that over 60% of the bytes on the Web are in images and that image payloads are only getting larger. Itâs not unheard of for a site to serve more than 10MBâ20MB for a single page. There have been examples, like one notorious one from Oakley, of up to 85MB. It was a rich, visually exciting site. It also took minutes to load even on a broadband connection. People are struggling with ways to cut down image sizes but still satisfy the âbig imageâ trend visible across the Web. Google, being Google, has even proposed a new, lighter-weight image format known as WEBP.
And that question doesnât really factor in the complexities of people browsing the Web over mobile networks. The reported speeds for the major mobile carriers have grown steadily, but the quality of connection on mobile isnât nearly what you can expect from a wired connection or even that of a cafe WiFi. Complete dead spots, holes in 4G coverage, train tunnels, signal concentration (try to get a signal at a heavily attended conference), and who knows what else (solar flares?) all conspire to make your mobile connection flaky. Add to that the demands that connections make on your battery (an HTTP connection means the radio has to make a connection to the local cell tower, that spikes the power usage on the device), other limitations of mobile connections, and the expectations of users with metered bandwidth, and itâs clear that you should be designing with the idea of limiting bandwidth as a primary goal.
This is especially true if you have a global audience. The whole continent of Africa, home to more than one billion people, basically skipped over the desktop altogether and will only ever connect to the Internet using a mobile device on networks of unknown quality.
Balancing performance, battery life, and bandwidth usage is a juggling act that will be touched on throughout this book.
The HumanâComputer Interface
The marriage of the mouse with the graphical user interface launched the personal computer revolution. Being able to manipulate files and perform other tasks with the click of a mouse opened up the power of computers to the point where they took over the world. A second revolution in humanâcomputer interfaces took place with the rise of touchscreen-enabled smartphones and tablets. One of the biggest challenges facing web developers these days arises from the fact that both of these interface paradigms are active on the Web. Trying to sort out what events to support and which design enhancements for touchscreens to enable is a hard problem to solve.
Even before widespread adoption of smartphones and tablets with touchscreen displays, there was complexity involved in properly coding for various humanâcomputer interfaces. In addition to the mouse, providing keyboard-based navigation hooks and shortcuts has been an important, if neglected, part of web development both for power users and as a vital accessibility feature. With the flood of touchscreen devices, the picture became even more complicated. Everything from the size of buttons to the use of hover effects had to be reevaluated.
People initially tried to solve this problem by separating the world into two binary statesâtouch-capable or nontouch-capable. Touch-capable devices would get big buttons and gesture events and nontouch-capable devices would get the old-school web experience.
The thing is, itâs not really a binary choice. From Windows 8 laptops to Chromebooks and even things like the Samsung Galaxy Note with its hover-capable and fine-grained stylus, there are many devices that can have a mouse, or mouse-like implement, in the case of a pen or stylus, and be a touchscreen at the same time.
Personally, there are moments when Iâm doing artwork on my Windows 8 laptop where Iâll have the mouse/touchpad, can touch the screen, and will be drawing with an interactive pen on a drawing tablet. What kind of user am I?
Adding to this already complicated story is the fact that the common detection for touch capability only reports whether or not the browser supports touch events by testing for the ontouchstart in the windows object, not if the device is a touchscreen:
if('ontouchstart'inwindow){console.log("touch events are present in the windowobject");}
So, even if you wanted to treat it as a binary, you canât reliably do so.
We canât forget about the future, either. Itâs coming whether you want it to or not. Devices with âfloating touchâ already exist, which means the hover event might be activated by a finger gradually approaching the surface of the screen on a device with no peripheral mouse or stylus.
And taking the third dimension even further, how common will purely gestural interfaces like the Microsoft Kinect be in the years to come?
Producing robust interfaces that work with a keyboard, mouse, finger, or with a hand waving through the air (like it just doesnât care) is one of the most important challenges you face as a web developer today.
Screen Resolution and Orientation
One of the legacies weâve dealt with as we transitioned from the world of print to the world of the Web was the desire for designers to have pixel-level control over every aspect of their designs when ported to the Web. This was somewhat possible when we had a limited set of screen resolutions to deal with and people designed fixed-width designs. These days, itâs significantly more complicated as more and more designs are based on flexible grids, and the number of display resolutions has grown out of control.
In the early 2000s, the biggest questions we had about screen resolutions were around the transition between 800px à 600px and 1024px à 768px. It seemed momentous at the time, but it took the community years to decide to make the switch en masse. These days? The stats for my blog, HTML + CSS + JavaScript, list 125 separate screen resolutions, ranging from 234px à 280px to such massive displays as 3840px à 1080px and 2880px à 1800px. Nine separate display resolutions each represent more than 5% of the total visits. Long gone are the days where you would open up a Photoshop template with a couple of guidelines set up showing a 960-pixel grid and then fold in different browsers. These days, figuring out which resolutions to target or whether to target resolutions at all is just the first question you need to tackle before launching into a design and development effort. Figuring out whether or not to leverage responsive web design or other techniques to tackle multiple resolutions is also a key decision. Itâs not the last, however. Itâs down to the point where things like the question of doing any preliminary design is on the table for some applications. These days, some people rely instead on quick, iterative design and refinement to create the look and feel for a site. This wonât work for something whose sole purpose is to be a thing of beauty, I imagine, but for a lot of sites, itâs a wonderful option.
Once youâve got that sorted out, youâve then got the difference between landscape and portrait display to deal with. That state can change one or more times per browsing session.
Although Iâm sure people are tempted to start plastering something like âbest viewed in the latest Chrome at 1920 Ã 1080â on their sites in order to get the best possible resolution for their design, itâs only going to get more difficult to predict âstandardâ screen resolutions going forward, so your designs potentially have to take into account a broad range of resolutions.
Pixel Density
With the release of Appleâs Retina-branded displays and the screen quality arms race that followed, the quality of displays on smartphones, tablets, and laptops has undergone a remarkable transformation over the past few years. Where once the highest quality displays were solely the domain of high-end design shops looking for the highest fidelity for their print design work, now incredible quality displays are in millions of pockets and laptops around the world. The bad news is that not every display is created equal, so thereâs a bit of a learning curve when it comes to dealing with these displays gracefully when building visually striking sites and applications.
For a long time, displays had a pixel density of either 72 or 96dpi (dots per inch). For a long time, this was shorthand for web developers to spot designers who were used to working in print. You would get a file, clearly exported out of Quark XPress (or later, Adobe InDesign) that was just gigantic because it was set to some print resolution. The design would be for a 1024 Ã 768 monitor, and it would be a 4267 Ã 3200 or larger Photoshop document. The first thing you would do would be to shrink the resolution down and hope that the design dimensions fit onto the typical screens of the time.
Then, along came smartphones, and that shorthand went away in a hurry. In fact, both sides of the designer/developer divide have had to relearn the ins and outs of preparing files for the Web.
Why? If youâre near a standard desktop monitor, stick your face as close to it as you would your phone, and (with some exceptions) you should be able to see the individual pixels. With your face right up there, images will look blocky, and most importantly, text will be hard to read as details designed into the typeface will be blurred out for lack of resolution. This is what your smartphone would look like if we didnât have higher-density displays. Driven by the need to create crisp text and images on small screens while simultaneously providing the largest possible screen real estate, device manufacturers have all improved their pixel density. This started with devices that came in around 150dpi, most famously the branded Retina display from Apple. Nowadays, 300+ dpi displays are common.
So, great, right? Whatâs the problem? Letâs quickly take a look at reference pixels and device pixels to illustrate why this new reality has added complexity to our lives.
Device pixels are the smallest units of display on the screen. Theyâre defined by the physical characteristics of the screen, so theyâre the part of this equation thatâs set in stone (or glass.) The reference pixel is a practical measurement built on top of the physical system. Itâs defined to be roughly equivalent to the size of a 96dpi pixel at armâs length, roughly 0.26 mm. High-density displays can have more than one device pixel per 0.26mm, but they will render your page at an effective 96dpi. This is pretty much seamless as CSS borders, backgrounds, type, and the like can be clearly calculated and rendered to match the expected reference pixels. These displays can also take advantage of the higher density to render clearer text as fonts are built to scale and the extra detail that can go into those reference pixels makes text clearer and much closer to the resolution you would see on printed matter.
The one major exception to this flood of benefits is with bitmapped images. Print designers have long had an opposite shorthand to their own little DPI test. Instead of getting files too large for the Web, print designers are used to being sent files prepped for the Web to use in print campaigns. If youâve ever done this, youâll know from their feedback that you canât scale bitmapped images up. If you need to print an image at 300dpi, all the information for the full resolution of the image needs to be there or else it will look like junk. No matter what TV shows like CSI might try to tell you, thereâs really no push button âzoom and enhanceâ that will make a blurry image clear as day.
So, on the Web now, if you need to show a 200px à 200px image on a high-density display, you need to provide more than 200px à 200px worth of data. If you donât, your images will look crummy. The following example illustrates the difference. Consider the following markup. It shows two images side by side. The images are 240 reference pixels square as defined by the height and width attribute on both images. The first image file was exported at 240 pixels square. The second is 668 pixels square. In the source, itâs compressed down to 240 pixels with the height and width attributes:
<!DOCTYPE html><html><head><metacharset="utf-8"></head><body><h1>The Uncertain Web</h1><h2>Chapter 01</h2><imgsrc="react-graffiti-96.jpg"width="240"height="240"/><imgsrc="react-graffiti-267.jpg"width="240"height="240"/></body></html>
In the first screenshot, from a standard density monitor, the two images are rendered identically (Figure 1-4).

The second screenshot, taken on a 267dpi high-density display (the Samsung Galaxy Note 2), shows the differences in quality between the two images (Figure 1-5). The dimensions are the same, in reference pixels, but the higher number of device pixels in the Note 2 requires additional data to render clearly.
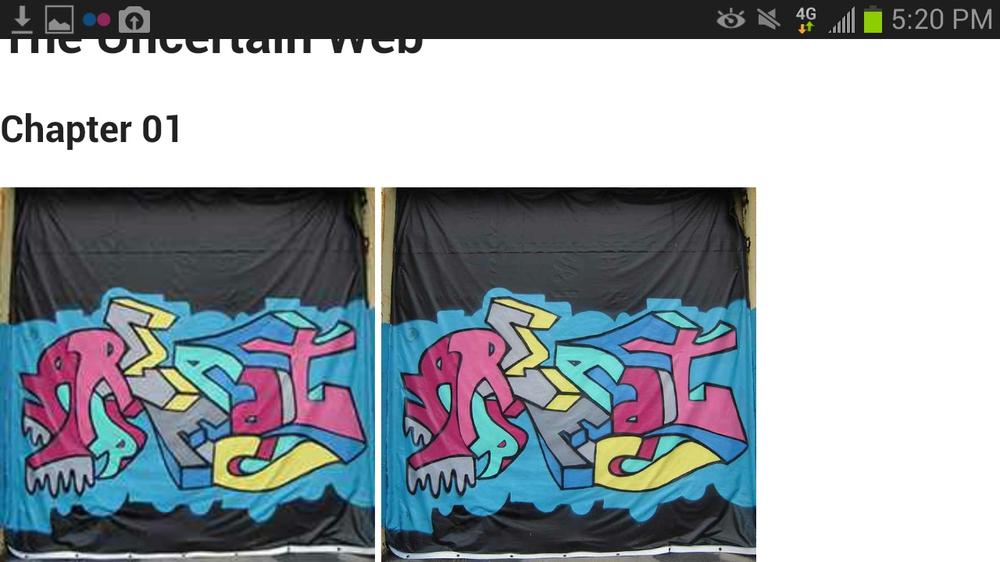
This is a thorny problem. As youâve learned already, there are plenty of web users (billions) on crummy connections. Many web users are also on metered data plans and donât want to spend all their hard-earned money downloading data theyâll never use. Serving those users the smallest possible payload with the best possible quality is key to creating great user experiences. On the opposite end of the spectrum, consumers with high-density displays ponied up the extra money for their fancy devices and want to get the high-end experience theyâve seen in the demos and TV commercials. Theyâll also notice that the negative fuzzy images stick out once youâre used to the photographic crispness of a high-density display.
So, factoring in screen size, pixel density, and the size of the browser window itself means that there are suddenly a lot of factors to work through when dealing with bitmapped images. Do you serve everyone 2x images, scaling down for everyone, but in the end serving bytes that people on standard density displays arenât going to use? Or do you serve standard size images, sacrificing some blurriness for better performance in all browsers? Or do you bite the bullet and dive into the hornetâs nest of responsive images? Add it up, and itâs clear that trying to navigate the proper density of images is one of the trickiest areas of web development right now.
There are no easy answers on how to deal with it beyond using Scalable Vector Graphics (SVG) and forgoing bitmaps entirely (not always possible) or, drastically, not using images at all (even less possible in most environments.)
Whatâs 2% Anyway?
If youâve been thinking about these numbers and are already considering ways youâll cut corners, knocking browsers or screen resolutions off your testing and support matrix because they only represent 2% or 5% market share, itâs worth taking a minute to think about what those numbers really mean. Based on your needs and requirements, you might be perfectly justified in many different support configurations. Although I strongly believe in supporting the largest possible percentage of web users, I also recognize that reality dictates certain support strategies. For example, working in financial services or health care, two industries that Iâve done a lot of work in, might require that I treat Internet Explorer 8 as a first-class browser. You, on the other hand, might be working on a site that caters to web developers and designers and might not see even 1% of your visits from IE8. So, instead of treating it as a first-class experience, you could provide simplified, alternative content or even devil-may-care support to IE8 users because thatâs not your audience.
Itâs useful to go examine your audience in this way whenever youâre crafting support strategies. You might think youâre comfortable with ignoring a certain browser from your testing plan, but then when you crunch the numbers and truly examine the makeup of your audience, you might realize that youâll probably need to spend some time testing in it or even craft some sort of optimized solution.
For one wildly unpopular example, according to Microsoftâs IE6 Countdown site, IE6 still accounts for 4.2% of the global browser market. However that number stacks up against other stats weâve seen, for the sake of argument, letâs take their metric at face value. And anyway, Microsoft isnât looking to overstate the presence of a browser that, at this point, brings them nothing but negative publicity, so thatâs got to count for something. At first blush, 4% might seem like a small number, but thatâs before you really break down the numbers. For easy math, letâs say there are 2,500,000,000 people out there with access to the Web. That puts that 4% market share at something like 100,000,000. For an easy comparison, thatâs just about the population of the Philippines, which just happens to be the 12th most populous country in the world. Looking at the numbers more closely, the high percentage of those Internet Explorer users in China (22% of the Chinese market) means that most of those usersâ80,000,000 or soâare Chinese. That puts the 100,000,000 IE6 users in a particularly Chinese context. That might mean you donât care because you have zero Chinese audience, but 100,000,000 users still means this is a choice you should make actively and not just with the wave of a hand because IE6 is annoying. If youâre starting a site design and youâre a global company, you have to ask yourself if you can safely ignore those users. Maybe you can, but itâs safer to look at the question with as much information as you can muster instead of blocking your eyes and ears and assuming itâll all be OK. That way, when someone asks why you did or did not prepare for IE6, you can give a reasoned response.
Interestingly, desktop Safari also has around 4% market share. Most developers I know wouldnât dream of ignoring Safari, but at the end of the day itâs still the same 100,000,000 people. Granted, itâs much easier to develop for Safari, and the typical Mac user has enough disposable income that they can buy a Mac, so theyâre a more appealing demographic, but it does make for an interesting perspective.
For an even smaller slice, and one that has a different mind share (as itâs mostly ignored instead of being hated), Opera Mini comes in at around 2% total market share by some measures. Most developers Iâve talked to have never tested with it and donât really know much about it. But its estimated 50,000,000 users are more than the population of California and Illinois combined. Would you ignore Chicago, San Francisco, and Los Angeles without a good reason? Probably not. Granted, Opera Mini has its own demographic quirks, but it shouldnât be completely ignored.
This isnât to say that you are somehow required to actively support any of these browsers. Not everyone has enough resources to design and develop for, test, and fix bugs across every device and browser. That said, it is important to keep some perspective and know what it really means when youâre chewing over some of these numbers. At the end of the day, they may not matter to you, but you canât really make that decision unless you know what decision youâre actually making.
Beyond your own existing analytics, there are several different resources you can look at to figure out the browser market:
- Peter Paul Koch writes intelligently about browser market share on this blog.
- Stat Counter offers statistics based on billions of page views every month.
- The Wikimedia Foundation publishes statistics based on the billions of page views generated by their own network of sites.
- Microsoftâs IE6 Countdown clock is the best source of information about IE6âs continued presence.
Also, with the number of cloud-based testing environments on the market and the fact that most design teams will have a variety of smartphones in the pockets of various members of the team, getting basic coverage isnât that hard if you decide to go for it.
This Is What We Wanted
Freaked out? Paranoid that the ground underneath you will shift at any moment? Good. Because it will. Iâm not the type to predict things like space hotels and cryonic suspension in order to emigrate into the future, but I can tell you there will be new devices, form factors, Open Web Platform features, and humanâcomputer input modes that youâll have to deal with as a web developer for as long as the role exists. And really, this is the way it should be. The only reason everything was allowed to go dormant in the early 2000s was because competition in the space disappeared. Once true competition returned, the natural way of the Open Web, which is to be as crazy as Iâve just described it, returned with a vengeance.
The good news is, all of these devices, form factors, and browsers all share one thing. They work on top of the Open Web Platform: HTML, CSS and JavaScript. If you seize on this shared platform and try to create the best possible experience for the broadest possible range of devices, youâll be able to reach users in every nook and cranny of the globe.
The remainder of this book will look at ways to tap into the Open Web Platform in order to do that.
So letâs look at how to make this happen.
Get The Uncertain Web now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

