Best Linear Unbiased Predictors
In aov, the effect size for treatment i is defined as ![]() i – μ, where μ is the overall mean. In mixed-effects models, however, correlation between the pseudoreplicates within a group causes what is called shrinkage. The best linear unbiased predictors (BLUPs, denoted by ai) are smaller than the effect sizes (
i – μ, where μ is the overall mean. In mixed-effects models, however, correlation between the pseudoreplicates within a group causes what is called shrinkage. The best linear unbiased predictors (BLUPs, denoted by ai) are smaller than the effect sizes (![]() i – μ), and are given by
i – μ), and are given by
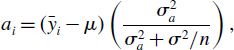
where σ2 is the residual variance and σ2a is the between-group variance which introduces the correlation between the pseudoreplicates within each group. Thus, the parameter estimate ai is ‘shrunk’ compared to the fixed effect size (![]() i – μ). When σ2a is estimated to be large compared with the estimate of σ2/n, then the fixed effects and the BLUP are similar (i.e. when most of the variation is between classes and there is little variation within classes). On the other hand, when σ2a is estimated to be small compared with the estimate of σ2/n, then the fixed effects and the BLUP can be very different (p. 547).
i – μ). When σ2a is estimated to be large compared with the estimate of σ2/n, then the fixed effects and the BLUP are similar (i.e. when most of the variation is between classes and there is little variation within classes). On the other hand, when σ2a is estimated to be small compared with the estimate of σ2/n, then the fixed effects and the BLUP can be very different (p. 547).
Get The R Book now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

