Auditing an existing site is one of the most important tasks that SEO professionals encounter. SEO is still a relatively new field,and many of the limitations of search engine crawlers are nonintuitive. In addition, many web developers, unfortunately, are not well versed in SEO. Even more unfortunately, some stubbornly refuse to learn, or, worse still, have learned the wrong things about SEO. This includes those who have developed CMS platforms, so there is a lot of opportunity to find problems when conducting a site audit.
As we will discuss in Chapter 6, your website needs to be a strong foundation for the rest of your SEO efforts to succeed. An SEO site audit is often the first step in executing an SEO strategy.
The following sections identify what you should look for when performing a site audit.
Although this may not be seen as a direct SEO issue, it is a very good place to start. Usability affects many factors, including conversion rate as well as the propensity of people to link to a site.
Make sure the site is friendly to search engine spiders. We discuss this in detail in Making Your Site Accessible to Search Engines and Creating an Optimal Information Architecture (IA).
Here are some quick health checks:
Perform a
site:yourdomain.comsearch in the search engines to check how many of your pages appear to be in the index. Compare this to the number of unique pages you believe you have on your site.Test a search on your brand terms to make sure you are ranking for them (if not, you may be suffering from a penalty).
Check the Google cache to make sure the cached versions of your pages look the same as the live versions of your pages.
Check to ensure major search engine “tools” have been verified for the domain (Google and Bing currently offer site owner validation to “peek” under the hood of how the engines view your site).
Are the right keywords being targeted? Does the site architecture logically flow from the way users search on related keywords? Does more than one page target the same exact keyword (a.k.a. keyword cannibalization)? We will discuss these items in Keyword Targeting.
The first thing you should do is to make sure the non-www versions of your pages (i.e., http://yourdomain.com) 301-redirect to the www versions of your pages (i.e., http://www.yourdomain.com), or vice versa (this is often called the canonical redirect). While you are at it, check that you don’t have https: pages that are duplicates of your http: pages. You should check the rest of the content on the site as well.
The easiest way to do this is to take unique strings from each of the major content pages on the site and search on them in Google. Make sure you enclose the string inside double quotes (e.g., “a phrase from your website that you are using to check for duplicate content”) so that Google will search for that exact string.
If your site is monstrously large and this is too big a task, make sure you check the most important pages, and have a process for reviewing new content before it goes live on the site.
You can also use commands such as inurl: and intitle: (see Table 2-1) to check for duplicate
content. For example, if you have URLs for pages that have distinctive
components to them (e.g., “1968-mustang-blue” or “1097495”), you can
search for these with the inurl:
command and see whether they return more than one page.
Another duplicate content task to perform is to make sure each piece of content is accessible at only one URL. This probably trips up more big commercial sites than any other issue. The issue is that the same content is accessible in multiple ways and on multiple URLs, forcing the search engines (and visitors) to choose which is the canonical version, which to link to, and which to disregard. No one wins when sites fight themselves—make peace, and if you have to deliver the content in different ways, rely on cookies so that you don’t confuse the spiders.
Make sure you have clean, short, descriptive URLs. Descriptive means keyword-rich but not keyword-stuffed. You don’t want parameters appended (have a minimal number if you must have any), and you want them to be simple and easy for users (and spiders) to understand.
Make sure the title tag on each page of the site is unique and descriptive. If you want to include your company brand name in the title, consider putting it at the end of the title tag, not at the beginning, as placement of keywords at the front of a URL brings ranking benefits. Also check to make sure the title tag is fewer than 70 characters long.
Do the main pages of the site have enough content? Do these pages all make use of header tags? A subtler variation of this is making sure the number of pages on the site with little content is not too high compared to the total number of pages on the site.
Check for a meta robots tag
on the pages of the site. If you find one, you may have already
spotted trouble. An unintentional NoIndex or NoFollow tag (we define these in Content Delivery and Search Spider Control) could really
mess up your search ranking plans.
Also make sure every page has a unique meta description. If for some reason that is not possible, consider removing the meta description altogether. Although the meta description tags are generally not a significant factor in ranking, they may well be used in duplicate content calculations, and the search engines frequently use them as the description for your web page in the SERPs; therefore, they affect click-though rate.
Use the Google Webmaster Tools “Test robots.txt” verification tool to check your robots.txt file. Also verify that your Sitemaps file is identifying all of your (canonical) pages.
Use a server header checker such as Live HTTP Headers (http://livehttpheaders.mozdev.org) to check that all the redirects used on the site return a 301 HTTP status code. Check all redirects this way to make sure the right thing is happening. This includes checking that the canonical redirect is properly implemented.
Unfortunately, given the nonintuitive nature of why the 301 redirect is preferred, you should verify that this has been done properly even if you have provided explicit direction to the web developer in advance. Mistakes do get made, and sometimes the CMS or the hosting company makes it difficult to use a 301.
Look for pages that have excessive links. Google advises 100 per page as a maximum, although it is OK to increase that on more important and heavily linked-to pages.
Make sure the site makes good use of anchor text in its internal links. This is a free opportunity to inform users and search engines what the various pages of your site are about. Don’t abuse it, though. For example, if you have a link to your home page in your global navigation (which you should), call it “Home” instead of picking your juiciest keyword. The search engines view that particular practice as spammy, and it does not engender a good user experience. Furthermore, the anchor text of internal links to the home page is not helpful for rankings anyway. Keep using that usability filter through all of these checks!
Note
A brief aside about hoarding PageRank: many people have taken this to an extreme and built sites where they refused to link out to other quality websites, because they feared losing visitors and link juice. Ignore this idea! You should link out to quality websites. It is good for users, and it is likely to bring you ranking benefits (through building trust and relevance based on what sites you link to). Just think of your human users and deliver what they are likely to want. It is remarkable how far this will take you.
The engines may not apply the entirety of a domain’s trust and link juice weight to subdomains. This is largely due to the fact that a subdomain could be under the control of a different party, and therefore in the search engine’s eyes it needs to be separately evaluated. In the great majority of cases, subdomain content can easily go in a subfolder.
If the domain is targeting a specific country, make sure the guidelines for country geotargeting outlined in Best Practices for Multilanguage/Country Targeting in Chapter 6 are being followed. If your concern is primarily about ranking for chicago pizza because you own a pizza parlor in Chicago, IL, make sure your address is on every page of your site. You should also check your results in Google Local to see whether you have a problem there. Additionally, you will want to register with Google Places, which is discussed in detail in Chapter 9.
Check the inbound links to the site. Use a backlinking tool such as Open Site Explorer (http://www.opensiteexplorer.org) or Majestic SEO (http://www.majesticseo.com) to collect data about your links. Look for bad patterns in the anchor text, such as 87% of the links having the critical keyword for the site in them. Unless the critical keyword happens to also be the name of the company, this is a sure sign of trouble. This type of distribution is quite likely the result of link purchasing or other manipulative behavior.
On the flip side, make sure the site’s critical keyword is showing up a fair number of times. A lack of the keyword usage in inbound anchor text is not good either. You need to find a balance.
Also look to see that there are links to pages other than the home page. These are often called deep links and they will help drive the ranking of key sections of your site. You should look at the links themselves, too. Visit the linking pages and see whether the links appear to be paid for. They may be overtly labeled as sponsored, or their placement may be such that they are clearly not natural endorsements. Too many of these are another sure sign of trouble.
Lastly, check how the link profile for the site compares to the link profiles of its major competitors. Make sure that there are enough external links to your site, and that there are enough high-quality links in the mix.
Is the page load time excessive? Too long a load time may slow down crawling and indexing of the site. However, to be a factor, this really does need to be excessive—certainly longer than five seconds, and perhaps even longer than that.
Do all the images have relevant, keyword-rich image alt attribute text and filenames? Search
engines can’t easily tell what is inside an image, and the best way to
provide them with some clues is with the alt attribute and the filename of the image.
These can also reinforce the overall context of the page
itself.
Although W3C validation is not something the search engines require, checking the code itself is a good idea. Poor coding can have some undesirable impacts. You can use a tool such as SEO Browser (http://www.seo-browser.com) to see how the search engines see the page.
Another critical component of an architecture audit is a keyword review. Basically, this involves the following steps.
It is vital to get this done as early as possible in any SEO process. Keywords drive on-page SEO, so you want to know which ones to target. You can read about this in more detail in Chapter 5.
Coming up with a site architecture can be very tricky. At this stage, you need to look at your keyword research and the existing site (to make as few changes as possible). You can think of this in terms of your site map.
You need a hierarchy that leads site visitors to your money pages (i.e., the pages where conversions are most likely to occur). Obviously, a good site hierarchy allows the parents of your money pages to rank for relevant keywords (which are likely to be shorter tail).
Most products have an obvious hierarchy they fit into, but when you start talking in terms of anything that naturally has multiple hierarchies, it gets incredibly tricky. The trickiest hierarchies, in our opinion, occur when there is a location involved. In London alone there are London boroughs, metropolitan boroughs, Tube stations, and postcodes. London even has a city (“The City of London”) within it.
In an ideal world, you will end up with a single hierarchy that is natural to your users and gives the closest mapping to your keywords. Whenever there are multiple ways in which people search for the same product, establishing a hierarchy becomes challenging.
Once you have a list of keywords and a good sense of the overall architecture, start mapping the major relevant keywords to URLs (not the other way around). When you do this, it is a very easy job to spot pages that you were considering creating that aren’t targeting a keyword (perhaps you might skip creating these), and, more importantly, keywords that don’t have a page.
It is worth pointing out that between step 2 and step 3 you will remove any wasted pages.
If this stage is causing you problems, revisit step 2. Your site architecture should lead naturally to a mapping that is easy to use and includes your keywords.
Once you are armed with your keyword mapping, the rest of the
site review becomes a lot easier. Now when you are looking at title
tags and headings, you can refer back to your keyword mapping and see
not only see whether the heading is in an <h1> tag, but also whether it includes
the right keywords.
Keyword cannibalization typically starts when a website’s information architecture calls for the targeting of a single term or phrase on multiple pages of the site. This is often done unintentionally, but it can result in several or even dozens of pages that have the same keyword target in the title and header tags. Figure 4-5 shows the problem.
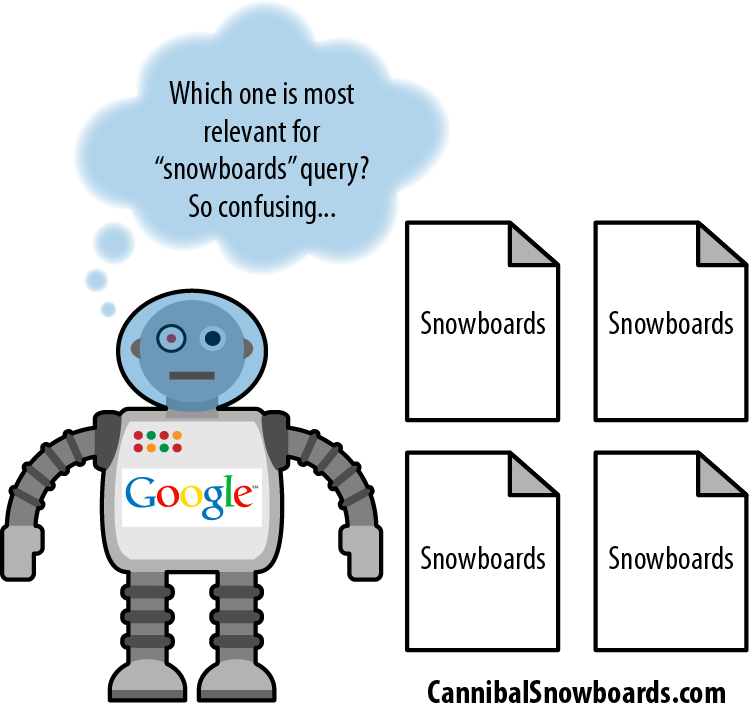
Search engines will spider the pages on your site and see 4 (or 40) different pages, all seemingly relevant to one particular keyword (in the example in Figure 4-5, the keyword is snowboards). For clarity’s sake, Google doesn’t interpret this as meaning that your site as a whole is more relevant to snowboards or should rank higher than the competition. Instead, it forces Google to choose among the many versions of the page and pick the one it feels best fits the query. When this happens, you lose out on a number of rank-boosting features:
- Internal anchor text
Since you’re pointing to so many different pages with the same subject, you can’t concentrate the value of internal anchor text on one target.
- External links
If four sites link to one of your pages on snowboards, three sites link to another of your snowboard pages, and six sites link to yet another snowboard page, you’ve split up your external link value among three pages, rather than consolidating it into one.
- Content quality
After three or four pages of writing about the same primary topic, the value of your content is going to suffer. You want the best possible single page to attract links and referrals, not a dozen bland, repetitive pages.
- Conversion rate
If one page is converting better than the others, it is a waste to have multiple lower-converting versions targeting the same traffic. If you want to do conversion tracking, use a multiple-delivery testing system (either A/B or multivariate).
So, what’s the solution? Take a look at Figure 4-6.
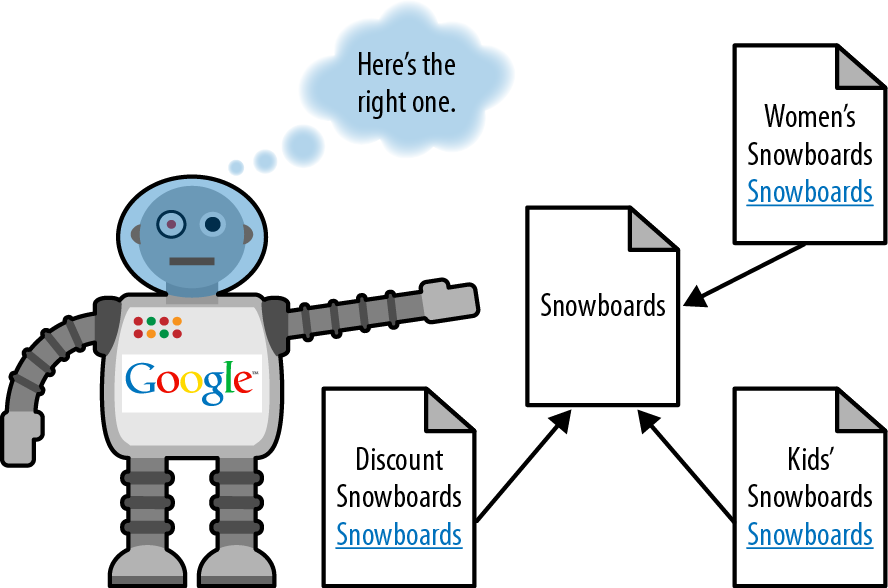
The difference in this example is that instead of every page targeting the single term snowboards, the pages are focused on unique, valuable variations and all of them link back to an original, canonical source for the single term. Google can now easily identify the most relevant page for each of these queries. This isn’t just valuable to the search engines; it also represents a far better user experience and overall information architecture.
What should you do if you’ve already got a case of keyword cannibalization? Employ 301s liberally to eliminate pages competing with each other, or figure out how to differentiate them. Start by identifying all the pages in the architecture with this issue and determine the best page to point them to, and then use a 301 from each of the problem pages to the page you wish to retain. This ensures not only that visitors arrive at the right page, but also that the link equity and relevance built up over time are directing the engines to the most relevant and highest-ranking-potential page for the query.
Enterprise sites range between 10,000 and 10 million pages in size. For many of these types of sites, an inaccurate distribution of internal link juice is a significant problem. Figure 4-7 shows how this can happen.
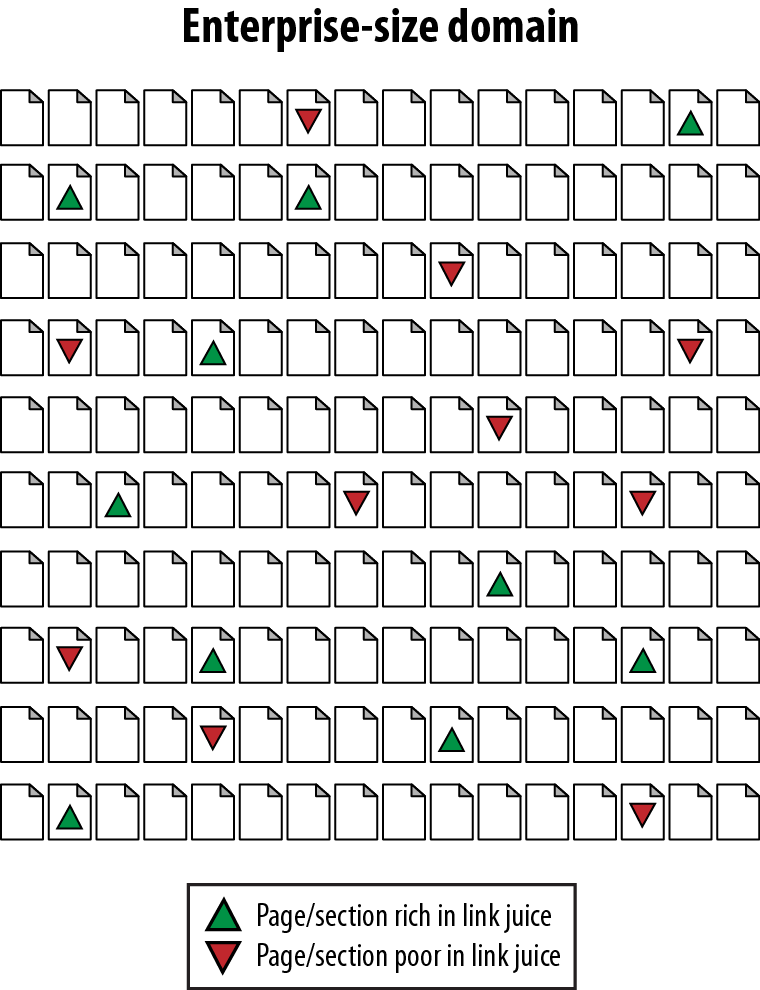
Figure 4-7 is an illustration of the link juice distribution issue. Imagine that each of the tiny pages represents between 5,000 and 100,000 pages in an enterprise site. Some areas, such as blogs, articles, tools, popular news stories, and so on, might be receiving more than their fair share of internal link attention. Other areas—often business-centric and sales-centric content—tend to fall by the wayside. How do you fix this problem? Take a look at Figure 4-8.
The solution is simple, at least in principle: have the link-rich pages spread the wealth to their link-bereft brethren. As easy as this may sound, in execution it can be incredibly complex. Inside the architecture of a site with several hundred thousand or a million pages, it can be nearly impossible to identify link-rich and link-poor pages, never mind adding code that helps to distribute link juice equitably.
The answer, sadly, is labor-intensive from a programming standpoint. Enterprise site owners need to develop systems to track inbound links and/or rankings and build bridges (or, to be more consistent with Figure 4-8, spouts) that funnel juice between the link-rich and link-poor.
An alternative is simply to build a very flat site architecture that relies on relevance or semantic analysis. This strategy is more in line with the search engines’ guidelines (though slightly less perfect) and is certainly far less labor-intensive.
Interestingly, the massive increase in weight given to domain authority over the past two to three years appears to be an attempt by the search engines to overrule potentially poor internal link structures (as designing websites for PageRank flow doesn’t always serve users particularly well), and to reward sites that have great authority, trust, and high-quality inbound links.

Thankfully, only a handful of server or web hosting dilemmas affect the practice of search engine optimization. However, when overlooked, they can spiral into massive problems, and so are worthy of review. The following are some server and hosting issues that can negatively impact search engine rankings:
- Server timeouts
If a search engine makes a page request that isn’t served within the bot’s time limit (or that produces a server timeout response), your pages may not make it into the index at all, and will almost certainly rank very poorly (as no indexable text content has been found).
- Slow response times
Although this is not as damaging as server timeouts, it still presents a potential issue. Not only will crawlers be less likely to wait for your pages to load, but surfers and potential linkers may choose to visit and link to other resources because accessing your site is problematic.
- Shared IP addresses
Basic concerns include speed, the potential for having spammy or untrusted neighbors sharing your IP address, and potential concerns about receiving the full benefit of links to your IP address (discussed in more detail at http://www.seroundtable.com/archives/002358.html).
- Blocked IP addresses
As search engines crawl the Web, they frequently find entire blocks of IP addresses filled with nothing but egregious web spam. Rather than blocking each individual site, engines do occasionally take the added measure of blocking an IP address or even an IP range. If you’re concerned, search for your IP address at Bing using the
ip:addressquery.- Bot detection and handling
Some sys admins will go a bit overboard with protection and restrict access to files to any single visitor making more than a certain number of requests in a given time frame. This can be disastrous for search engine traffic, as it will constantly limit the spiders’ crawling ability.
- Bandwidth and transfer limitations
Many servers have set limitations on the amount of traffic that can run through to the site. This can be potentially disastrous when content on your site becomes very popular and your host shuts off access. Not only are potential linkers prevented from seeing (and thus linking to) your work, but search engines are also cut off from spidering.
- Server geography
This isn’t necessarily a problem, but it is good to be aware that search engines do use the location of the web server when determining where a site’s content is relevant from a local search perspective. Since local search is a major part of many sites’ campaigns and it is estimated that close to 40% of all queries have some local search intent, it is very wise to host in the country (it is not necessary to get more granular) where your content is most relevant.
Get The Art of SEO, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

