Chapter 6. Topic Modeling
In text mining, we often have collections of documents, such as blog posts or news articles, that we’d like to divide into natural groups so that we can understand them separately. Topic modeling is a method for unsupervised classification of such documents, similar to clustering on numeric data, which finds natural groups of items even when we’re not sure what we’re looking for.
Latent Dirichlet allocation (LDA) is a particularly popular method for fitting a topic model. It treats each document as a mixture of topics, and each topic as a mixture of words. This allows documents to “overlap” each other in terms of content, rather than being separated into discrete groups, in a way that mirrors typical use of natural language.
As Figure 6-1 shows, we can use tidy text principles to approach topic
modeling with the same set of tidy tools we’ve used throughout this
book. In this chapter, we’ll learn to work with LDA objects from the
topicmodels package,
particularly tidying such models so that they can be manipulated with
ggplot2 and dplyr. We’ll also explore an example of clustering chapters
from several books, where we can see that a topic model “learns” to
tell the difference between the four books based on the text content.
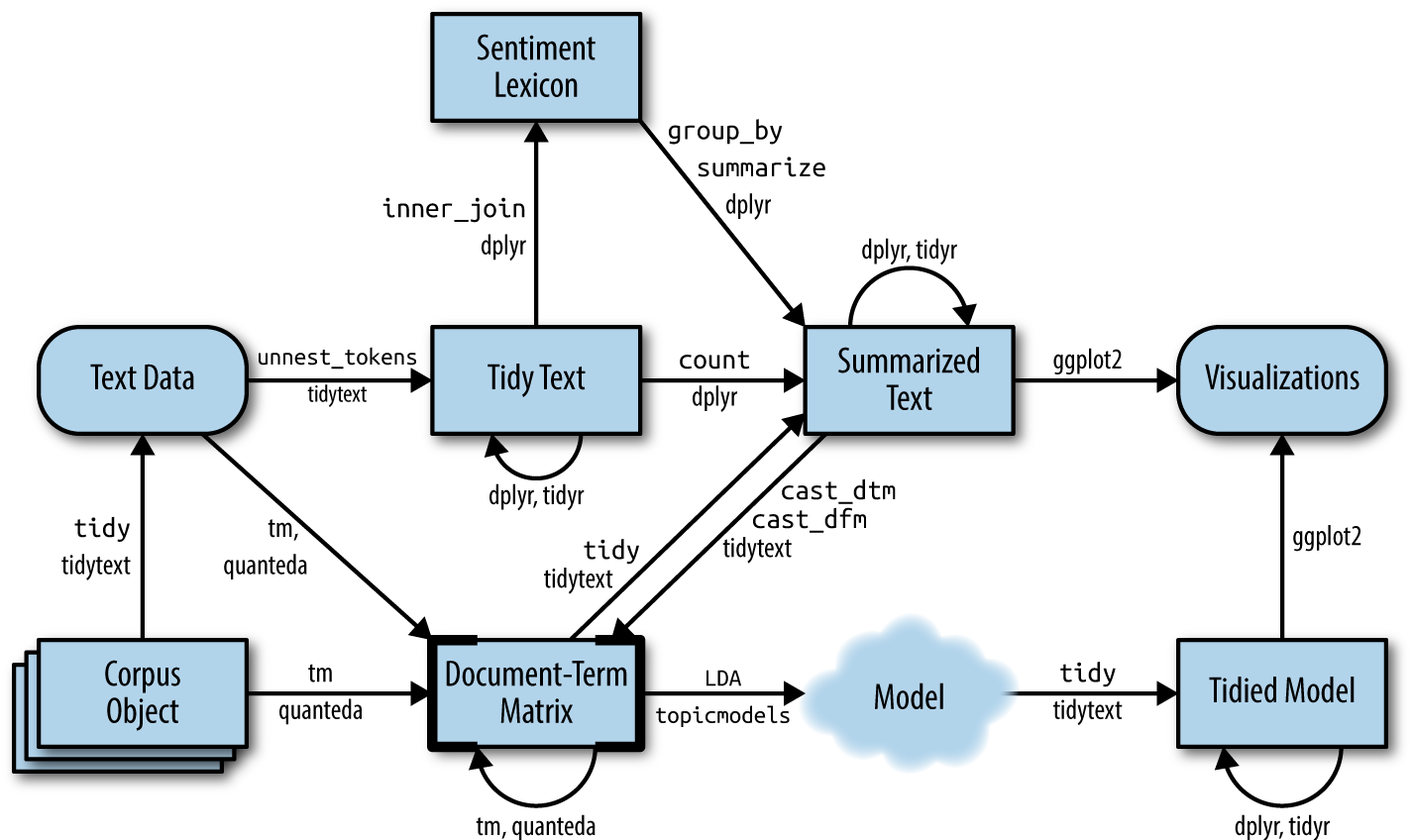
Figure 6-1. A flowchart of a text analysis that incorporates topic modeling. The topicmodels package takes a document-term matrix ...
Get Text Mining with R now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

