The first operational gate we will implement is 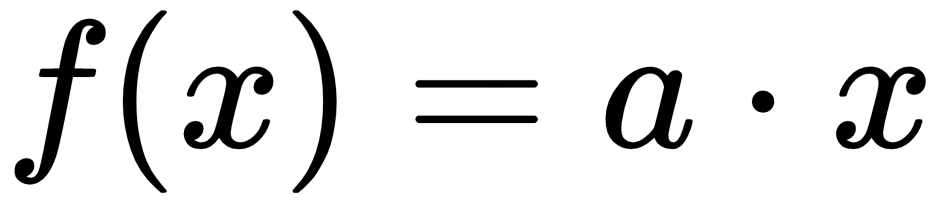 . To optimize this gate, we declare the a input as a variable and the x input as a placeholder. This means that TensorFlow will try to change the a value and not the x value. We will create the loss function as the difference between the output and the target value, which is 50.
. To optimize this gate, we declare the a input as a variable and the x input as a placeholder. This means that TensorFlow will try to change the a value and not the x value. We will create the loss function as the difference between the output and the target value, which is 50.
The second, nested operational gate will be 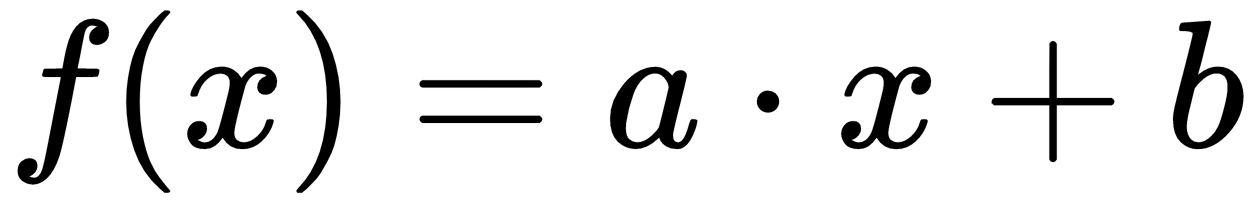 . Again, we will declare a and b as variables and x as a place holder. We optimize the output towards the target value of 50 again. The interesting thing to note ...
. Again, we will declare a and b as variables and x as a place holder. We optimize the output towards the target value of 50 again. The interesting thing to note ...

