In this recipe, we will motivate the usage of kernels in Support Vector Machines. In the linear SVM section, we solved the soft margin with a specific loss function. A different approach to this method is to solve what is called the dual of the optimization problem. It can be shown that the dual for the linear SVM problem is given by the following formula:
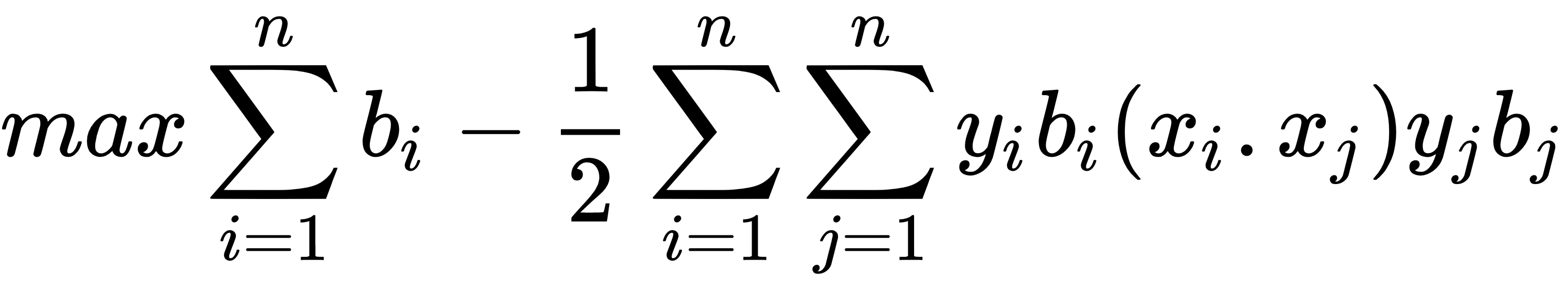
To this, the following applies:
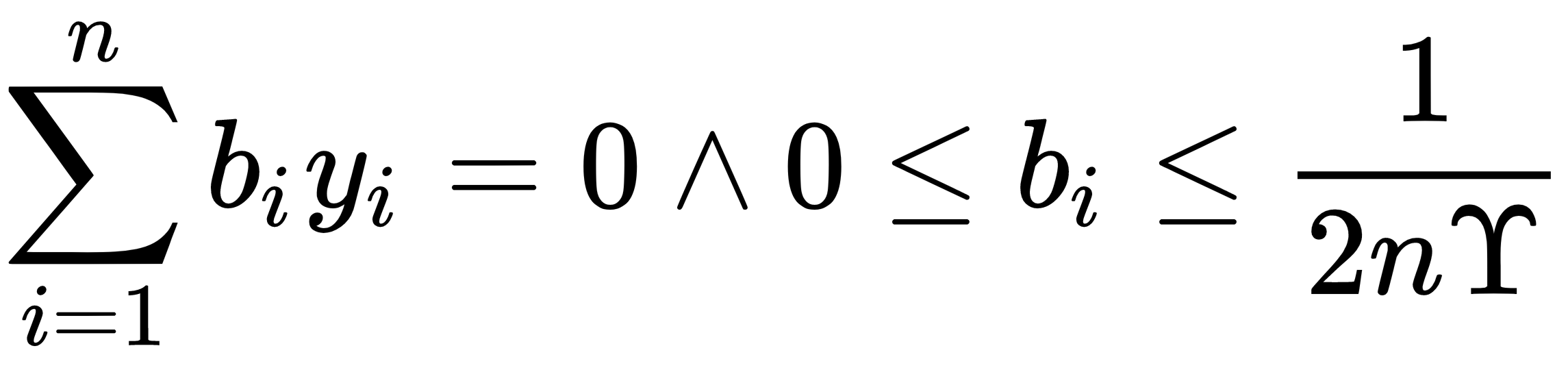
Here, the variable in the model will be the b vector. Ideally, this vector will be quite sparse, only taking on values near 1 and -1 for the ...

