Here is the loss over the iterations and train and test accuracy. Since the dataset is only 189 observations, the train and test accuracy plots will change owing to the random splitting of the dataset. The first figure is the cross-entropy loss:
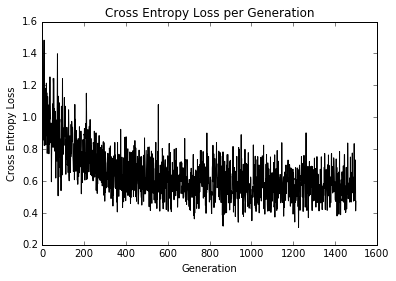
Figure 11: Cross-entropy loss plotted over the course of 1,500 iterations
The second figure shows us the accuracy of the train and test sets:
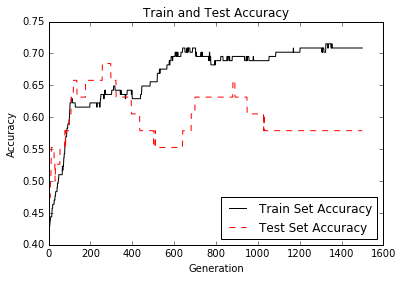
Figure 12: Test and train set accuracy plotted over 1,500 generations

