Chapter 1. Introduction to Deep Learning
Deep learning has revolutionized the technology industry. Modern machine translation, search engines, and computer assistants are all powered by deep learning. This trend will only continue as deep learning expands its reach into robotics, pharmaceuticals, energy, and all other fields of contemporary technology. It is rapidly becoming essential for the modern software professional to develop a working knowledge of the principles of deep learning.
In this chapter, we will introduce you to the history of deep learning, and to the broader impact deep learning has had on the research and commercial communities. We will next cover some of the most famous applications of deep learning. This will include both prominent machine learning architectures and fundamental deep learning primitives. We will end by giving a brief perspective of where deep learning is heading over the next few years before we dive into TensorFlow in the next few chapters.
Machine Learning Eats Computer Science
Until recently, software engineers went to school to learn a number of basic algorithms (graph search, sorting, database queries, and so on). After school, these engineers would go out into the real world to apply these algorithms to systems. Most of today’s digital economy is built on intricate chains of basic algorithms laboriously glued together by generations of engineers. Most of these systems are not capable of adapting. All configurations and reconfigurations have to be performed by highly trained engineers, rendering systems brittle.
Machine learning promises to change the field of software development by enabling systems to adapt dynamically. Deployed machine learning systems are capable of learning desired behaviors from databases of examples. Furthermore, such systems can be regularly retrained as new data comes in. Very sophisticated software systems, powered by machine learning, are capable of dramatically changing their behavior without major changes to their code (just to their training data). This trend is only likely to accelerate as machine learning tools and deployment become easier and easier.
As the behavior of software-engineered systems changes, the roles of software engineers will change as well. In some ways, this transformation will be analogous to the transformation following the development of programming languages. The first computers were painstakingly programmed. Networks of wires were connected and interconnected. Then punchcards were set up to enable the creation of new programs without hardware changes to computers. Following the punchcard era, the first assembly languages were created. Then higher-level languages like Fortran or Lisp. Succeeding layers of development have created very high-level languages like Python, with intricate ecosystems of precoded algorithms. Much modern computer science even relies on autogenerated code. Modern app developers use tools like Android Studio to autogenerate much of the code they’d like to make. Each successive wave of simplification has broadened the scope of computer science by lowering barriers to entry.
Machine learning promises to lower barriers even further; programmers will soon be able to change the behavior of systems by altering training data, possibly without writing a single line of code. On the user side, systems built on spoken language and natural language understanding such as Alexa and Siri will allow nonprogrammers to perform complex computations. Furthermore, ML powered systems are likely to become more robust against errors. The capacity to retrain models will mean that codebases can shrink and that maintainability will increase. In short, machine learning is likely to completely upend the role of software engineers. Today’s programmers will need to understand how machine learning systems learn, and will need to understand the classes of errors that arise in common machine learning systems. Furthermore, they will need to understand the design patterns that underlie machine learning systems (very different in style and form from classical software design patterns). And, they will need to know enough tensor calculus to understand why a sophisticated deep architecture may be misbehaving during learning. It’s not an understatement to say that understanding machine learning (theory and practice) will become a fundamental skill that every computer scientist and software engineer will need to understand for the coming decade.
In the remainder of this chapter, we will provide a whirlwind tour of the basics of modern deep learning. The remainder of this book will go into much greater depth on all the topics we touch on here.
Deep Learning Primitives
Most deep architectures are built by combining and recombining a limited set of architectural primitives. Such primitives, typically called neural network layers, are the foundational building blocks of deep networks. In the rest of this book, we will provide in-depth introductions to such layers. However, in this section, we will provide a brief overview of the common modules that are found in many deep networks. This section is not meant to provide a thorough introduction to these modules. Rather, we aim to provide a rapid overview of the building blocks of sophisticated deep architectures to whet your appetite. The art of deep learning consists of combining and recombining such modules and we want to show you the alphabet of the language to start you on the path to deep learning expertise.
Fully Connected Layer
A fully connected network transforms a list of inputs into a list of outputs. The transformation is called fully connected since any input value can affect any output value. These layers will have many learnable parameters, even for relatively small inputs, but they have the large advantage of assuming no structure in the inputs. This concept is illustrated in Figure 1-1.
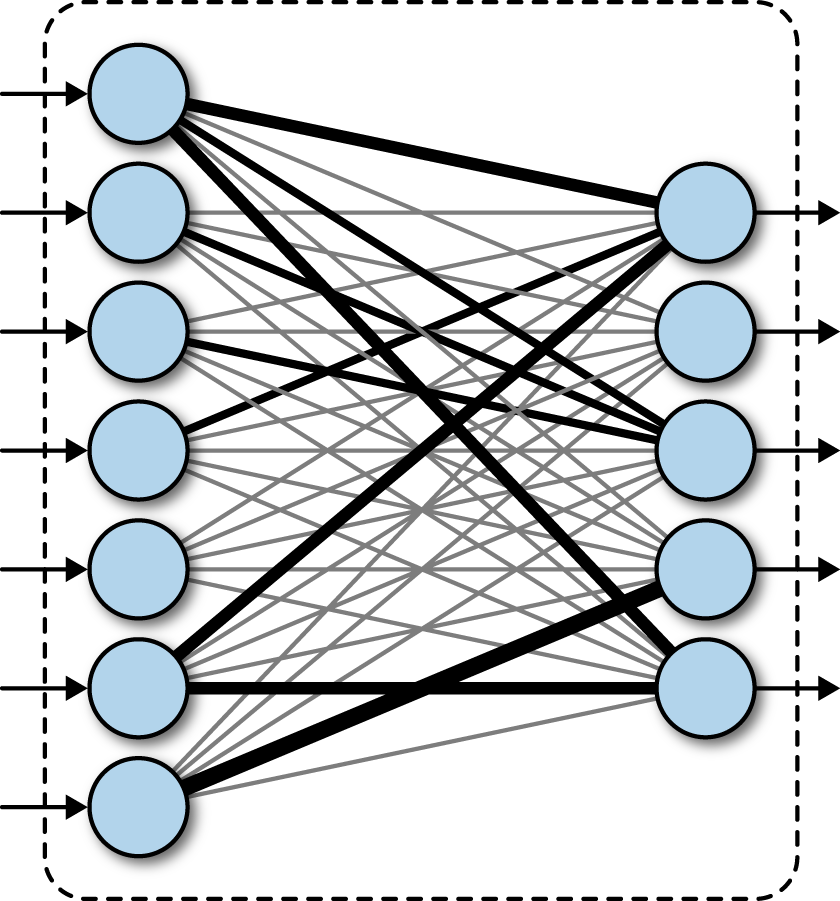
Figure 1-1. A fully connected layer. Inbound arrows represent inputs, while outbound arrows represent outputs. The thickness of interconnecting lines represents the magnitude of learned weights. The fully connected layer transforms inputs into outputs via the learned rule.
Convolutional Layer
A convolutional network assumes special spatial structure in its input. In particular, it assumes that inputs that are close to each other spatially are semantically related. This assumption makes most sense for images, since pixels close to one another are likely semantically linked. As a result, convolutional layers have found wide use in deep architectures for image processing. This concept is illustrated in Figure 1-2.
Just like fully connected layers transform lists to lists, convolutional layers transform images into images. As a result, convolutional layers can be used to perform complex image transformations, such as applying artistic filters to images in photo apps.
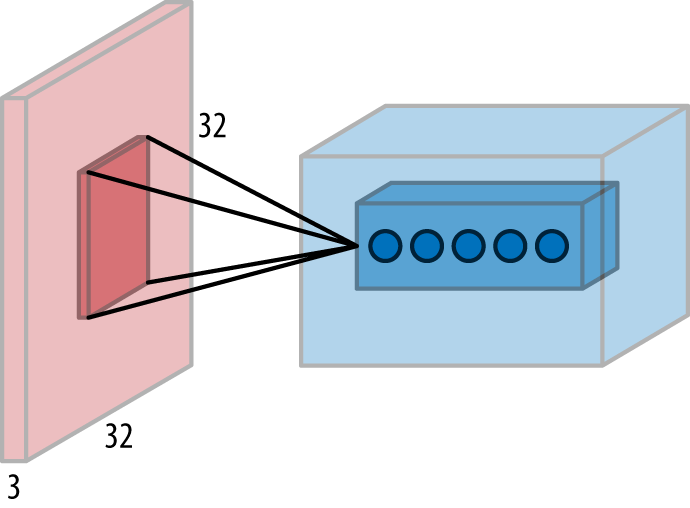
Figure 1-2. A convolutional layer. The red shape on the left represents the input data, while the blue shape on the right represents the output. In this particular case, the input is of shape (32, 32, 3). That is, the input is a 32-pixel-by-32-pixel image with three RGB color channels. The highlighted region in the red input is a “local receptive field,” a group of inputs that are processed together to create the highlighted region in the blue output.
Recurrent Neural Network Layers
Recurrent neural network (RNN) layers are primitives that allow neural networks to learn from sequences of inputs. This layer assumes that the input evolves from step to step following a defined update rule that can be learned from data. This update rule presents a prediction of the next state in the sequence given all the states that have come previously. An RNN is illustrated in Figure 1-3.
An RNN layer can learn this update rule from data. As a result, RNNs are very useful for tasks such as language modeling, where engineers seek to build systems that can predict the next word users will type from history.
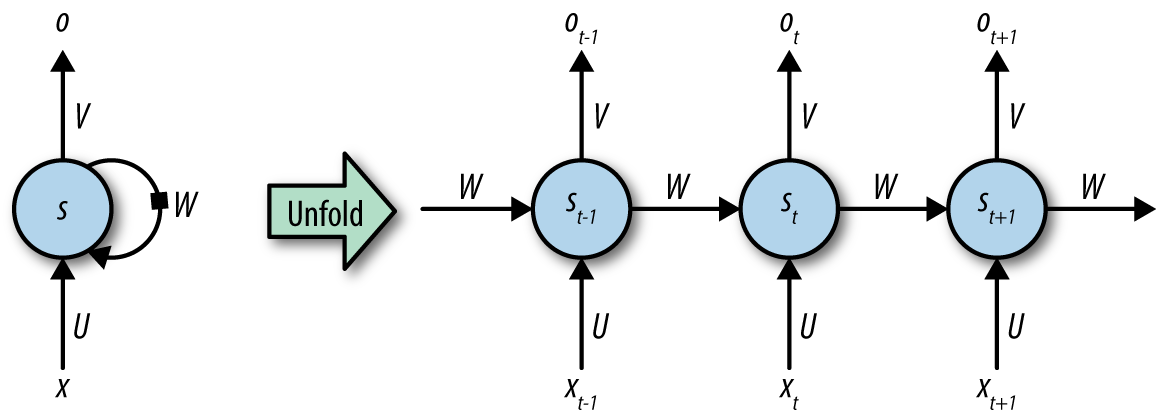
Figure 1-3. A recurrent neural network (RNN). Inputs are fed into the network at the bottom, and outputs extracted at the top. W represents the learned transformation (shared at all timesteps). The network is represented conceptually on the left and is unrolled on the right to demonstrate how inputs from different timesteps are processed.
Long Short-Term Memory Cells
The RNN layers presented in the previous section are capable of learning arbitrary sequence-update rules in theory. In practice, however, such layers are incapable of learning influences from the distant past. Such distant influences are crucial for performing solid language modeling since the meaning of a complex sentence can depend on the relationship between far-away words. The long short-term memory (LSTM) cell is a modification to the RNN layer that allows for signals from deeper in the past to make their way to the present. An LSTM cell is illustrated in Figure 1-4.
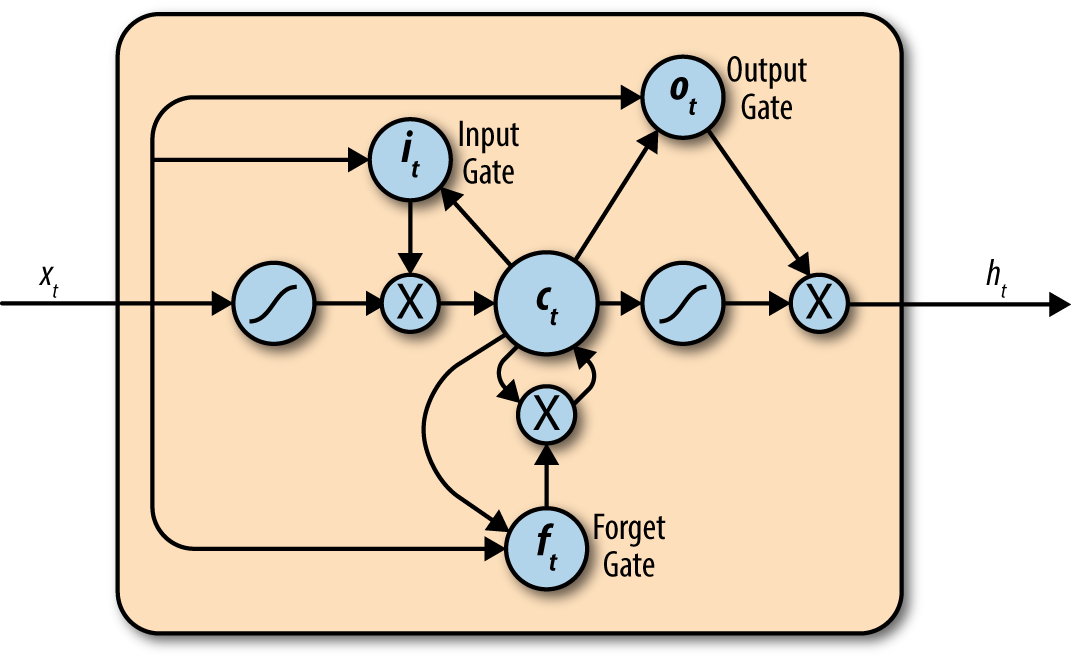
Figure 1-4. A long short-term memory (LSTM) cell. Internally, the LSTM cell has a set of specially designed operations that attain much of the learning power of the vanilla RNN while preserving influences from the past. Note that the illustration depicts one LSTM variant of many.
Deep Learning Architectures
There have been hundreds of different deep learning models that combine the deep learning primitives presented in the previous section. Some of these architectures have been historically important. Others were the first presentations of novel designs that influenced perceptions of what deep learning could do.
In this section, we present a selection of different deep learning architectures that have proven influential for the research community. We want to emphasize that this is an episodic history that makes no attempt to be exhaustive. There are certainly important models in the literature that have not been presented here.
LeNet
The LeNet architecture is arguably the first prominent “deep” convolutional architecture. Introduced in 1988, it was used to perform optical character recoginition (OCR) for documents. Although it performed its task admirably, the computational cost of the LeNet was extreme for the computer hardware available at the time, so the design languished in (relative) obscurity for a few decades after its creation. This architecture is illustrated in Figure 1-5.
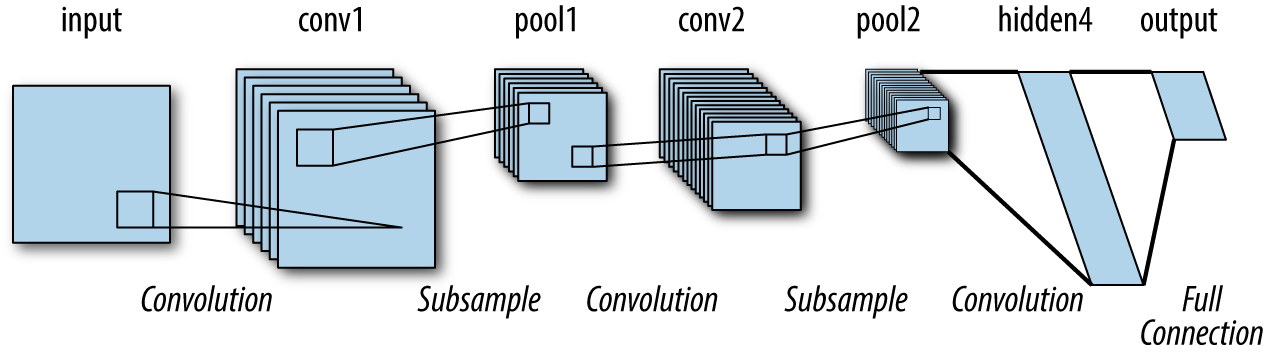
Figure 1-5. The LeNet architecture for image processing. Introduced in 1988, it was arguably the first deep convolutional model for image processing.
AlexNet
The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) was first organized in 2010 as a test of the progress made in visual recognition systems. The organizers made use of Amazon Mechanical Turk, an online platform to connect workers to requesters, to catalog a large collection of images with associated lists of objects present in the image. The use of Mechanical Turk permitted the curation of a collection of data significantly larger than those gathered previously.
The first two years the challenge ran, more traditional machine-learned systems that relied on systems like HOG and SIFT features (hand-tuned visual feature extraction methods) triumphed. In 2012, the AlexNet architecture, based on a modification of LeNet run on powerful graphics processing units (GPUs), entered and dominated the challenge with error rates half that of the nearest competitors. This victory dramatically galvanized the (already nascent) trend toward deep learning architectures in computer vision. The AlexNet architecture is illustrated in Figure 1-6.
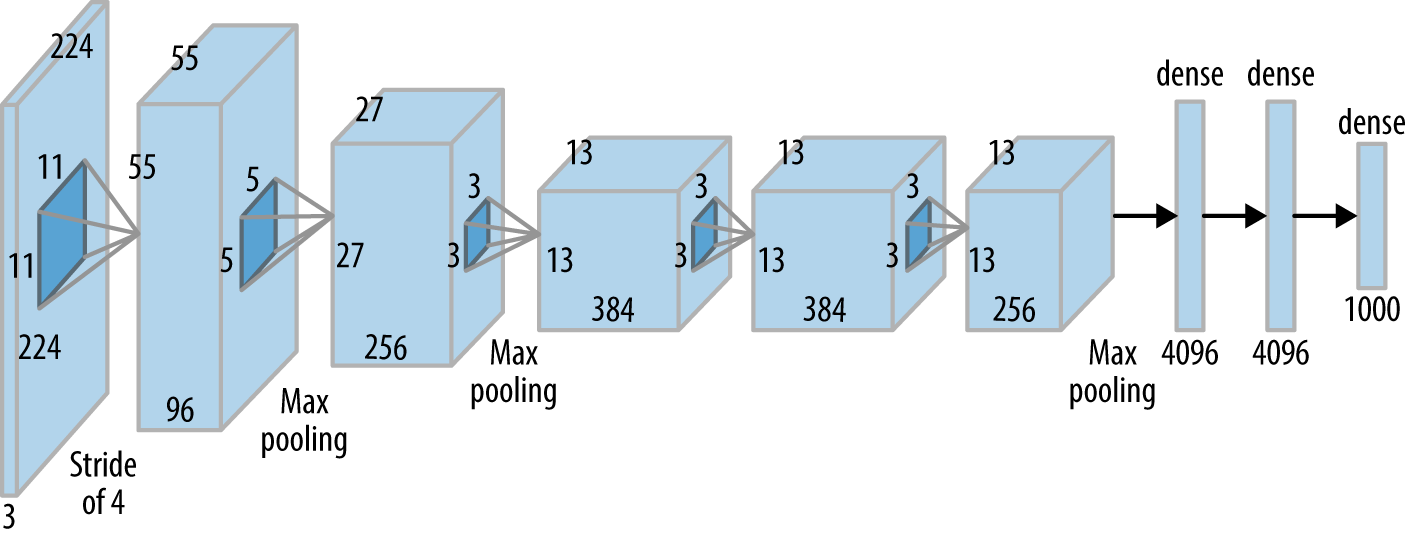
Figure 1-6. The AlexNet architecture for image processing. This architecture was the winning entry in the ILSVRC 2012 challenge and galvanized a resurgence of interest in convolutional architectures.
ResNet
Since 2012, convolutional architectures consistently won the ILSVRC challenge (along with many other computer vision challenges). Each year the contest was held, the winning architecture increased in depth and complexity. The ResNet architecture, winner of the ILSVRC 2015 challenge, was particularly notable; ResNet architectures extended up to 130 layers deep, in contrast to the 8-layer AlexNet architecture.
Very deep networks historically were challenging to learn; when networks grow this deep, they run into the vanishing gradients problem. Signals are attenuated as they progress through the network, leading to diminished learning. This attenuation can be explained mathematically, but the effect is that each additional layer multiplicatively reduces the strength of the signal, leading to caps on the effective depth of networks.
The ResNet introduced an innovation that controlled this attenuation: the bypass connection. These connections allow part of the signal from deeper layers to pass through undiminished, enabling significantly deeper networks to be trained effectively. The ResNet bypass connection is illustrated in Figure 1-7.
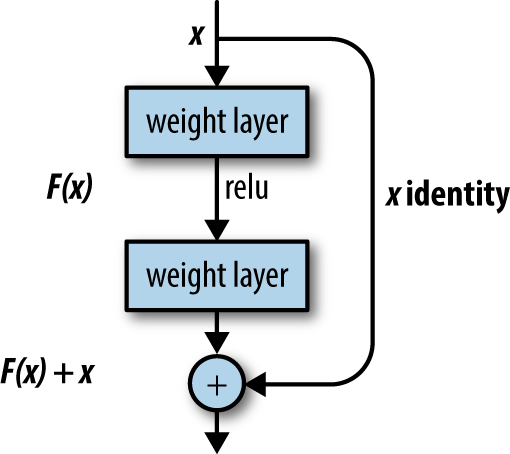
Figure 1-7. The ResNet cell. The identity connection on the righthand side permits an unmodified version of the input to pass through the cell. This modification allows for the effective training of very deep convolutional architectures.
Neural Captioning Model
As practitioners became more comfortable with the use of deep learning primitives, they experimented with mixing and matching primitive modules to create higher-order systems that could perform more complex tasks than basic object detection. Neural captioning systems automatically generate captions for the contents of images. They do so by combining a convolutional network, which extracts information from images, with an LSTM layer that generates a descriptive sentence for the image. The entire system is trained end-to-end. That is, the convolutional network and the LSTM network are trained together to achieve the desired goal of generating descriptive sentences for provided images.
This end-to-end training is one of the key innovations powering modern deep learning systems since it lessens the need for complicated preprocessing of inputs. Image captioning models that don’t use deep learning would have to use complicated image featurization methods such as SIFT, which can’t be trained alongside the caption generator.
A neural captioning model is illustrated in Figure 1-8.
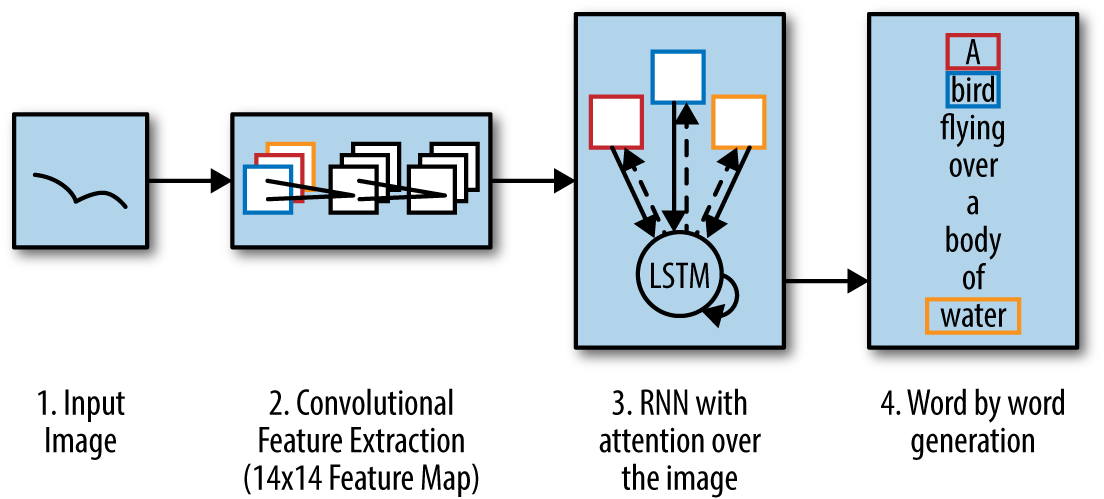
Figure 1-8. A neural captioning architecture. Relevant input features are extracted from the input image using a convolutional network. Then a recurrent network is used to generate a descriptive sentence.
Google Neural Machine Translation
Google’s neural machine translation (Google-NMT) system uses the paradigm of end-to-end training to build a production translation system, which takes sentences from the source language directly to the target language. The Google-NMT system depends on the fundamental building block of the LSTM, which it stacks over a dozen times and trains on an extremely large dataset of translated sentences. The final architecture provided for a breakthrough advance in machine-translation by cutting the gap between human and machine translations by up to 60%. The Google-NMT architecture is illustrated in Figure 1-9.
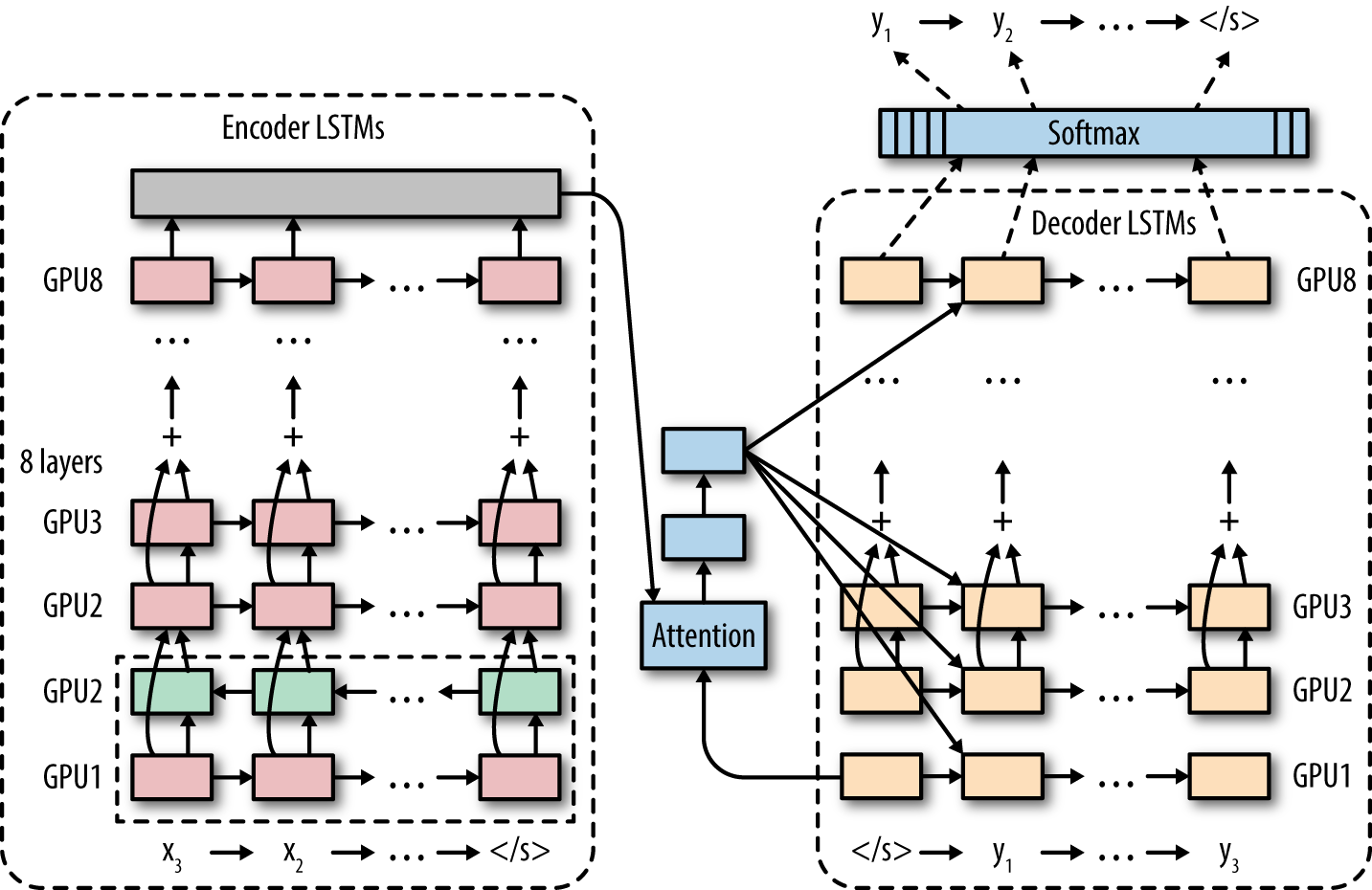
Figure 1-9. The Google neural machine translation system uses a deep recurrent architecture to process the input sentence and a second deep recurrent architecture to generate the translated output sentence.
One-Shot Models
One-shot learning is perhaps the most interesting new idea in machine/deep learning. Most deep learning techniques typically require very large amounts of data to learn meaningful behavior. The AlexNet architecture, for example, made use of the large ILSVRC dataset to learn a visual object detector. However, much work in cognitive science has indicated that humans can learn complex concepts from just a few examples. Take the example of baby learning about giraffes for the first time. A baby shown a single giraffe at the zoo might be capable of learning to recognize all giraffes she sees from then on.
Recent progress in deep learning has started to invent architectures capable of similar learning feats. Given only a few examples of a concept (but given ample sources of side information), such systems can learn to make meaningful predictions with very few datapoints. One recent paper (by an author of this book) used this idea to demonstrate that one-shot architectures can learn even in contexts babies can’t, such as in medical drug discovery. A one-shot architecture for drug discovery is illustrated in Figure 1-10.
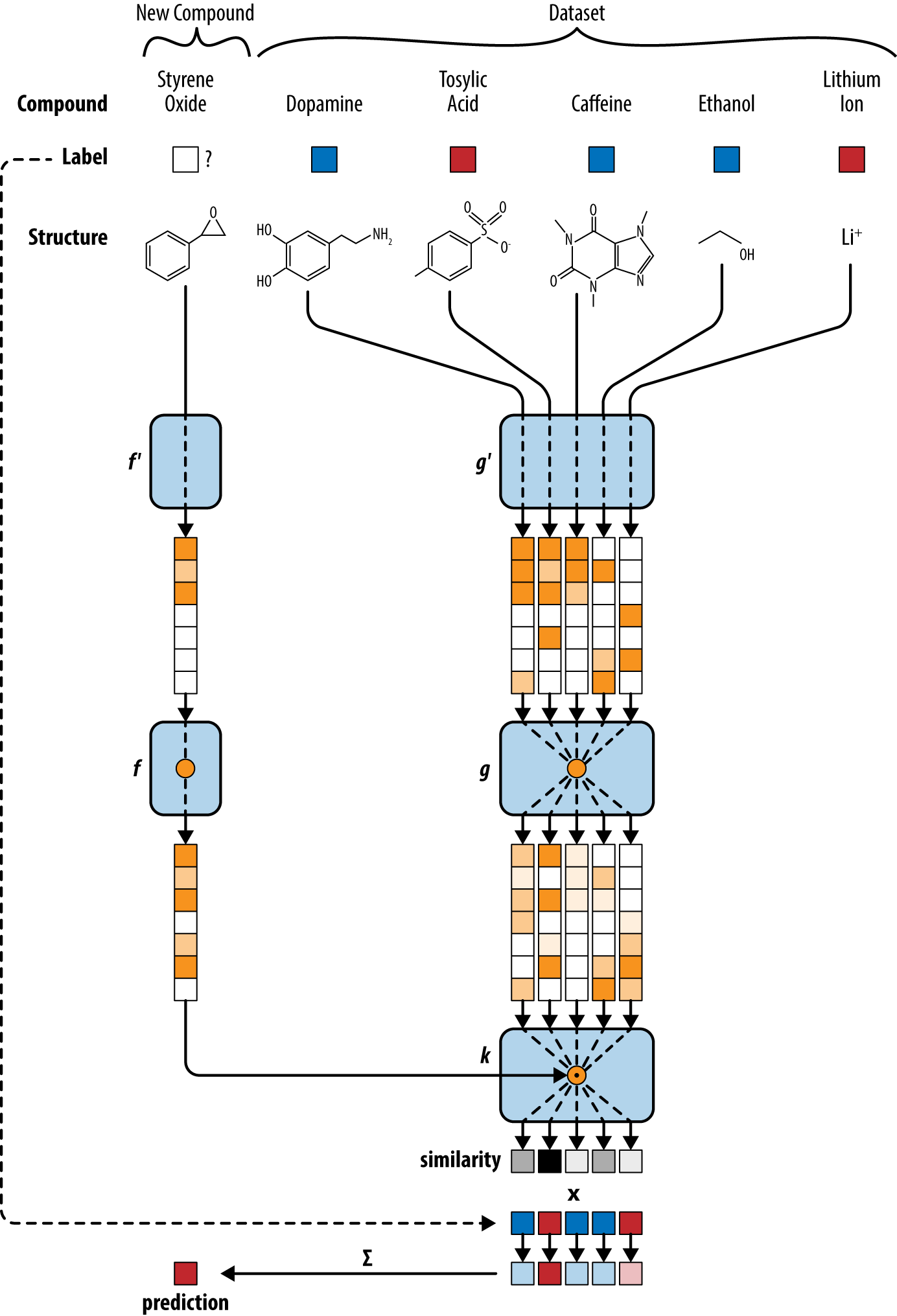
Figure 1-10. The one-shot architecture uses a type of convolutional network to transform each molecule into a vector. The vector for styrene oxide is compared with vectors from the experimental dataset. The label for the most similar datapoint (tosylic acid) is imputed for the query.
AlphaGo
Go is an ancient board game, widely influential in Asia. Computer Go has been a major challenge for computer science since the late 1960s. Techniques that enabled the computer chess system Deep Blue to beat chess grandmaster Garry Kasparov in 1997 don’t scale to Go. Part of the issue is that Go has a much bigger board than chess; Go boards are of size 19 × 19 as opposed to 8 × 8 for chess. Since far more moves are possible per step, the game tree of possible Go moves expands much more quickly, rendering brute force search with contemporary computer hardware insufficient for adequate Go gameplay. Figure 1-11 illustrates a Go board.

Figure 1-11. An illustration of a Go board. Players alternately place white and black pieces on a 19 × 19 grid.
Master level computer Go was finally achieved by AlphaGo from Google DeepMind. AlphaGo proved capable of defeating one of the world’s strongest Go champions, Lee Sedol, in a five-game match. Some of the key ideas from AlphaGo include the use of a deep value network and deep policy network. The value network provides an estimate of the value of a board position. Unlike chess, it’s very difficult to guess whether white or black is winning in Go from the board state. The value network solves this problem by learning to make this prediction from game outcomes. The policy network, on the other hand, helps estimate the best move to take given a current board state. The combination of these two techniques with Monte Carlo Tree search (a classical search method) helped overcome the large branching factor in Go games. The basic AlphaGo architecture is illustrated in Figure 1-12.
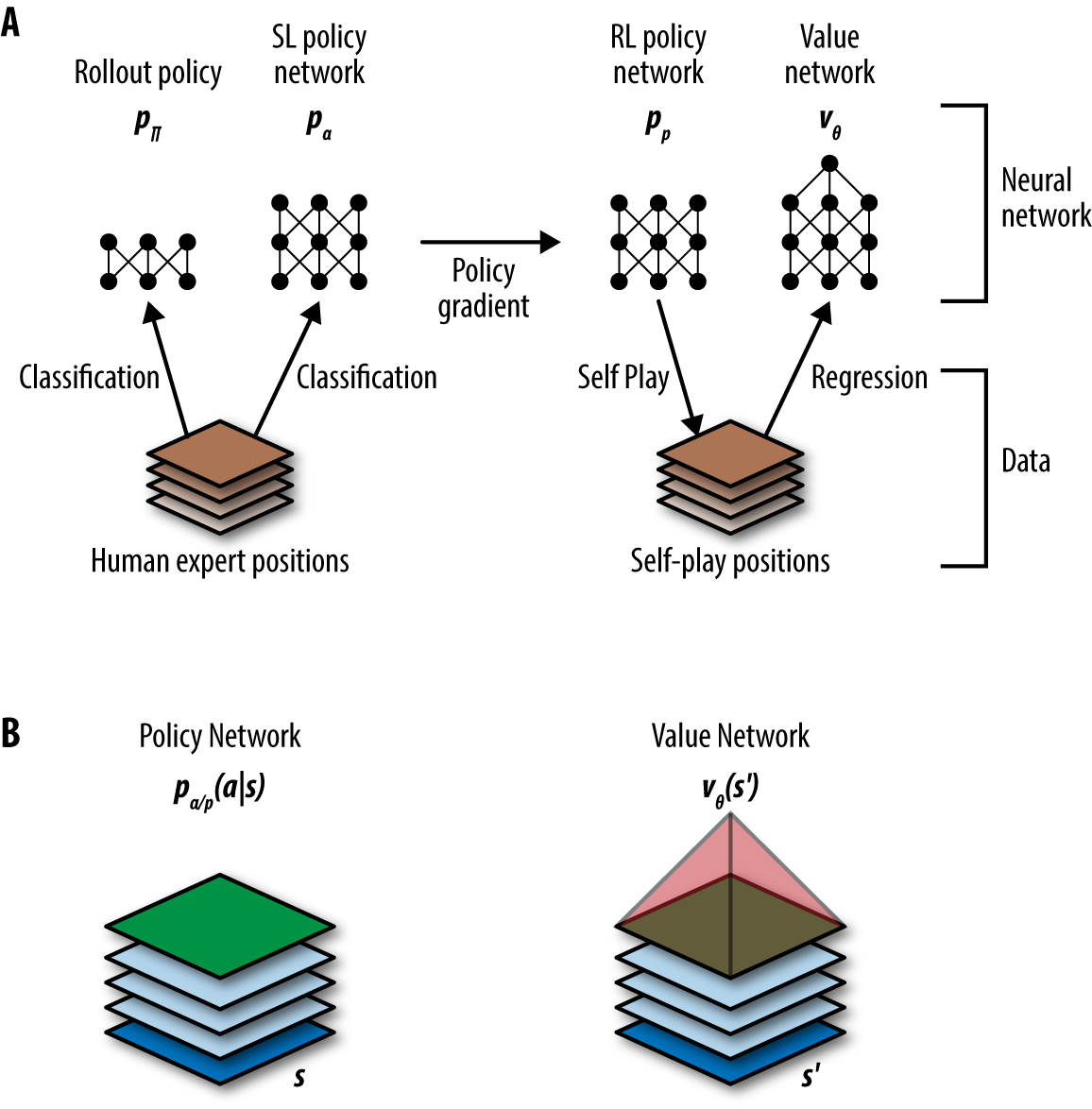
Figure 1-12. A) Depiction of AlphaGo’s architecture. Initially a policy network to select moves is trained on a dataset of expert games. This policy is then refined by self-play. “RL” indicates reinforcement learning and “SL” indicates supervised learning. B) Both the policy and value networks operate on representations of the game board.
Generative Adversarial Networks
Generative adversarial networks (GANs) are a new type of deep network that uses two competing neural networks, the generator and the adversary (also called the discriminator), which duel against each other. The generator tries to draw samples from a training distribution (for example, tries to generate realistic images of birds). The discriminator works on differentiating samples drawn from the generator from true data samples. (Is a particular bird a real image or generator-created?) This “adversarial” training for GANs seems capable of generating image samples of considerably higher fidelity than other techniques and may be useful for training effective discriminators with limited data. A GAN architecture is illustrated in Figure 1-13.
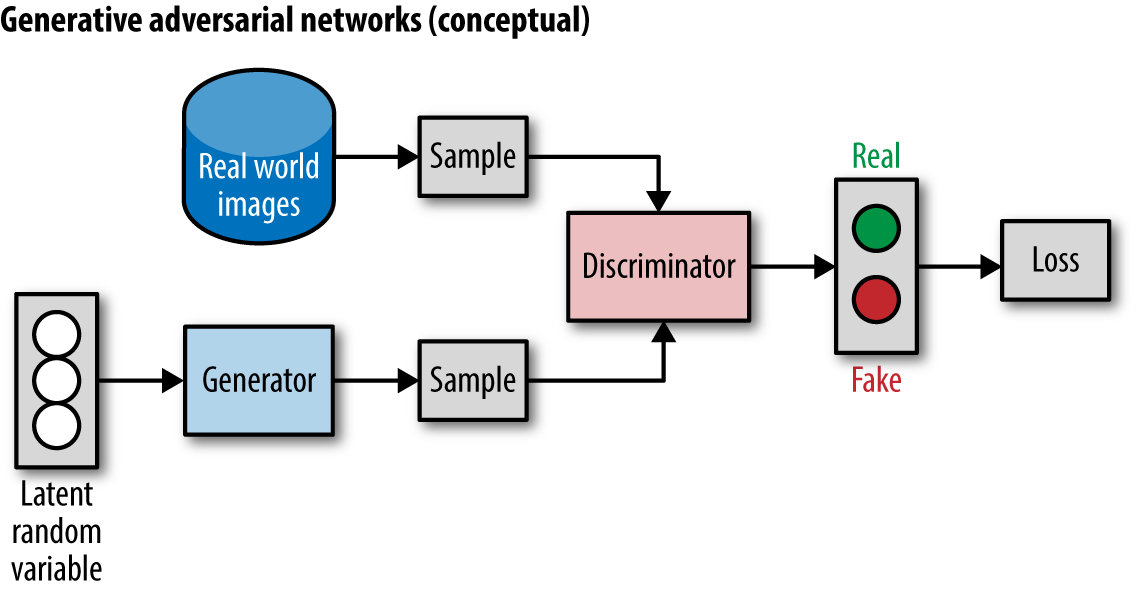
Figure 1-13. A conceptual depiction of a generative adversarial network (GAN).
GANs have proven capable of generating very realistic images, and will likely power the next generation of computer graphics tools. Samples from such systems are now approaching photorealism. However, many theoretical and practical caveats still remain to be worked out with these systems and much research is still needed.
Neural Turing Machines
Most of the deep learning systems presented so far have learned complex functions with limited domains of applicability; for example, object detection, image captioning, machine translation, or Go game-play. But, could we perhaps have deep architectures that learn general algorithmic concepts such as sorting, addition, or multiplication?
The Neural Turing machine (NTM) is a first attempt at making a deep learning architecture capable of learning arbitrary algorithms. This architecture adds an external memory bank to an LSTM-like system, to allow the deep architecture to make use of scratch space to compute more sophisticated functions. At the moment, NTM-like architectures are still quite limited, and only capable of learning simple algorithms. Nevertheless, NTM methods remain an active area of research and future advances may transform these early demonstrations into practical learning tools. The NTM architecture is conceptually illustrated in Figure 1-14.
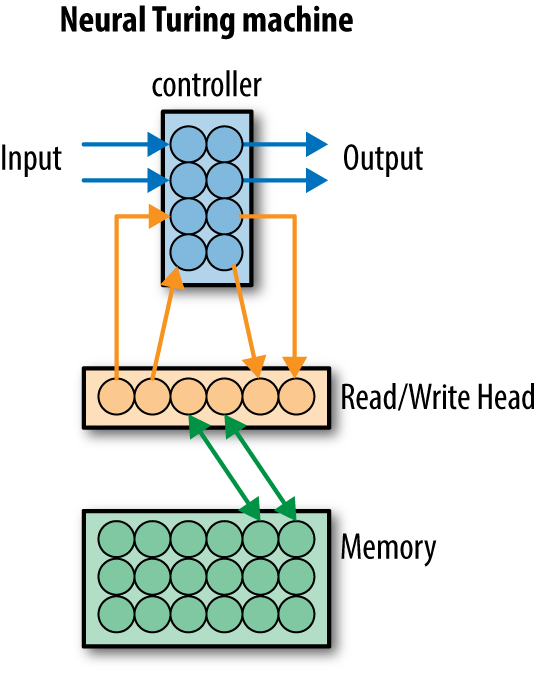
Figure 1-14. A conceptual depiction of a Neural Turing machine. It adds an external memory bank to which the deep architecture reads and writes.
Deep Learning Frameworks
Researchers have been implementing software packages to facilitate the construction of neural network (deep learning) architectures for decades. Until the last few years, these systems were mostly special purpose and only used within an academic group. This lack of standardized, industrial-strength software made it difficult for non-experts to use neural networks extensively.
This situation has changed dramatically over the last few years. Google implemented the DistBelief system in 2012 and made use of it to construct and deploy many simpler deep learning architectures. The advent of DistBelief, and similar packages such as Caffe, Theano, Torch, Keras, MxNet, and so on have widely spurred industry adoption.
TensorFlow draws upon this rich intellectual history, and builds upon some of these packages (Theano in particular) for design principles. TensorFlow (and Theano) in particular use the concept of tensors as the fundamental underlying primitive powering deep learning systems. This focus on tensors distinguishes these packages from systems such as DistBelief or Caffe, which don’t allow the same flexibility for building sophisticated models.
While the rest of this book will focus on TensorFlow, understanding the underlying principles should enable you to take the lessons learned and apply them with little difficulty to alternative deep learning frameworks.
Limitations of TensorFlow
One of the major current weaknesses of TensorFlow is that constructing a new deep learning architecture is relatively slow (on the order of multiple seconds to initialize an architecture). As a result, it’s not convenient in TensorFlow to construct some sophisticated deep architectures that change their structure dynamically. One such architecture is the TreeLSTM, which uses syntactic parse trees of English sentences to perform tasks that require understanding of natural language. Since each sentence has a different parse tree, each sentence requires a slightly different architecture. Figure 1-15 illustrates the TreeLSTM architecture.
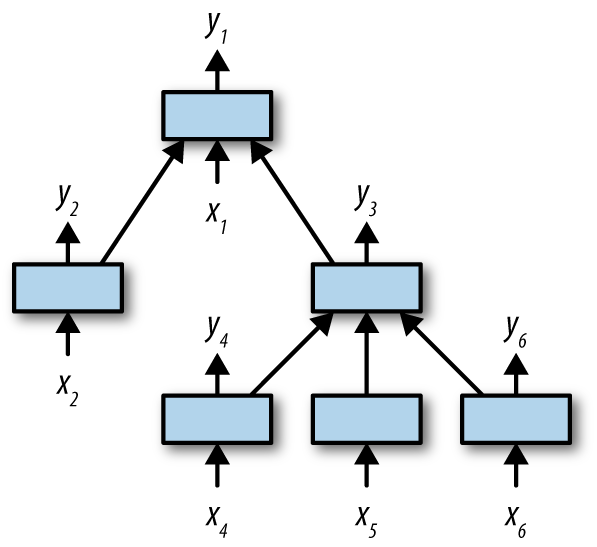
Figure 1-15. A conceptual depiction of a TreeLSTM architecture. The shape of the tree is different for each input datapoint, so a different computational graph must be constructed for each example.
While such models can be implemented in TensorFlow, doing so requires significant ingenuity due to the limitations of the current TensorFlow API. New frameworks such as Chainer, DyNet, and PyTorch promise to remove these barriers by making the construction of new architectures lightweight enough so that models like the TreeLSTM can be constructed easily. Luckily, TensorFlow developers are already working on extensions to the base TensorFlow API (such as TensorFlow Eager) that will enable easier construction of dynamic architectures.
One takeaway is that progress in deep learning frameworks is rapid, and today’s novel system can be tomorrow’s old news. However, the fundamental principles of the underlying tensor calculus date back centuries, and will stand readers in good stead regardless of future changes in programming models. This book will emphasize using TensorFlow as a vehicle for developing an intuitive knowledge of the underlying tensor calculus.
Review
In this chapter, we’ve explained why deep learning is a subject of critical importance for the modern software engineer and taken a whirlwind tour of a number of deep architectures. In the next chapter, we will start exploring TensorFlow, Google’s framework for constructing and training deep architectures. In the chapters after that, we will dive deep into a number of practical examples of deep architectures.
Machine learning (and deep learning in particular), like much of computer science, is a very empirical discipline. It’s only really possible to understand deep learning through significant practical experience. For that reason, we’ve included a number of in-depth case studies throughout the remainder of this book. We encourage you to delve into these examples and to get your hands dirty experimenting with your own ideas using TensorFlow. It’s never enough to understand algorithms only theoretically!
Get TensorFlow for Deep Learning now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

