Chapter 1. Why Use Change Data Capture?
Change data capture (CDC) continuously identifies and captures incremental changes to data and data structures (aka schemas) from a source such as a production database. CDC arose two decades ago to help replication software deliver real-time transactions to data warehouses, where the data is then transformed and delivered to analytics applications. Thus, CDC enables efficient, low-latency data transfer to operational and analytics users with low production impact.
Let’s walk through the business motivations for a common use of replication: offloading analytics queries from production applications and servers. At the most basic level, organizations need to do two things with data:
Record what’s happening to the business—sales, expenditures, hiring, and so on.
Analyze what’s happening to assist decisions—which customers to target, which costs to cut, and so forth—by querying records.
The same database typically cannot support both of these requirements for transaction-intensive enterprise applications, because the underlying server has only so much CPU processing power available. It is not acceptable for an analytics query to slow down production workloads such as the processing of online sales transactions. Hence the need to analyze copies of production records on a different platform. The business case for offloading queries is to both record business data and analyze it, without one action interfering with the other.
The first method used for replicating production records (i.e., rows in a database table) to an analytics platform is batch loading, also known as bulk or full loading. This process creates files or tables at the target, defines their “metadata” structures based on the source, and populates them with data copied from the source as well as the necessary metadata definitions.
Batch loads and periodic reloads with the latest data take time and often consume significant processing power on the source system. This means administrators need to run replication loads during “batch windows” of time in which production is paused or will not be heavily affected. Batch windows are increasingly unacceptable in today’s global, 24×7 business environment.
Here are real examples of enterprise struggles with batch loads (in Chapter 4, we examine how organizations are using CDC to eliminate struggles like these and realize new business value):
A Fortune 25 telecommunications firm was unable to extract data from SAP ERP and PeopleSoft fast enough to its data lake. Laborious, multitier loading processes created day-long delays that interfered with financial reporting.
A Fortune 100 food company ran nightly batch jobs that failed to reconcile orders and production line-items on time, slowing plant schedules and preventing accurate sales reports.
One of the world’s largest payment processors was losing margin on every transaction because it was unable to assess customer-creditworthiness in-house in a timely fashion. Instead, it had to pay an outside agency.
A major European insurance company was losing customers due to delays in its retrieval of account information.
Each of these companies eliminated their bottlenecks by replacing batch replication with CDC. They streamlined, accelerated, and increased the scale of their data initiatives while minimizing impact on production operations.
Advantages of CDC
CDC has three fundamental advantages over batch replication:
It enables faster and more accurate decisions based on the most current data; for example, by feeding database transactions to streaming analytics applications.
It minimizes disruptions to production workloads.
It reduces the cost of transferring data over the wide area network (WAN) by sending only incremental changes.
Together these advantages enable IT organizations to meet the real-time, efficiency, scalability, and low-production impact requirements of a modern data architecture. Let’s explore each of these in turn.
Faster and More Accurate Decisions
The most salient advantage of CDC is its ability to support real-time analytics and thereby capitalize on data value that is perishable. It’s not difficult to envision ways in which real-time data updates, sometimes referred to as fast data, can improve the bottom line.
For example, business events create data with perishable business value. When someone buys something in a store, there is a limited time to notify their smartphone of a great deal on a related product in that store. When a customer logs into a vendor’s website, this creates a short-lived opportunity to cross-sell to them, upsell to them, or measure their satisfaction. These events often merit quick analysis and action.
In a 2017 study titled The Half Life of Data, Nucleus Research analyzed more than 50 analytics case studies and plotted the value of data over time for three types of decisions: tactical, operational, and strategic. Although mileage varied by example, the aggregate findings are striking:
Data used for tactical decisions, defined as decisions that prioritize daily tasks and activities, on average lost more than half its value 30 minutes after its creation. Value here is measured by the portion of decisions enabled, meaning that data more than 30 minutes old contributed to 70% fewer operational decisions than fresher data. Marketing, sales, and operations personnel make these types of decisions using custom dashboards or embedded analytics capabilities within customer relationship management (CRM) and/or supply-chain management (SCM) applications.
Operational data on average lost about half its value after eight hours. Examples of operational decisions, usually made over a few weeks, include improvements to customer service, inventory stocking, and overall organizational efficiency, based on data visualization applications or Microsoft Excel.
Data used for strategic decisions has the longest-range implications, but still loses half its value roughly 56 hours after creation (a little less than two and a half days). In the strategic category, data scientists and other specialized analysts often are assessing new market opportunities and significant potential changes to the business, using a variety of advanced statistical tools and methods.
Figure 1-1 plots Nucleus Research’s findings. The Y axis shows the value of data to decision making, and the X axis shows the hours after its creation.
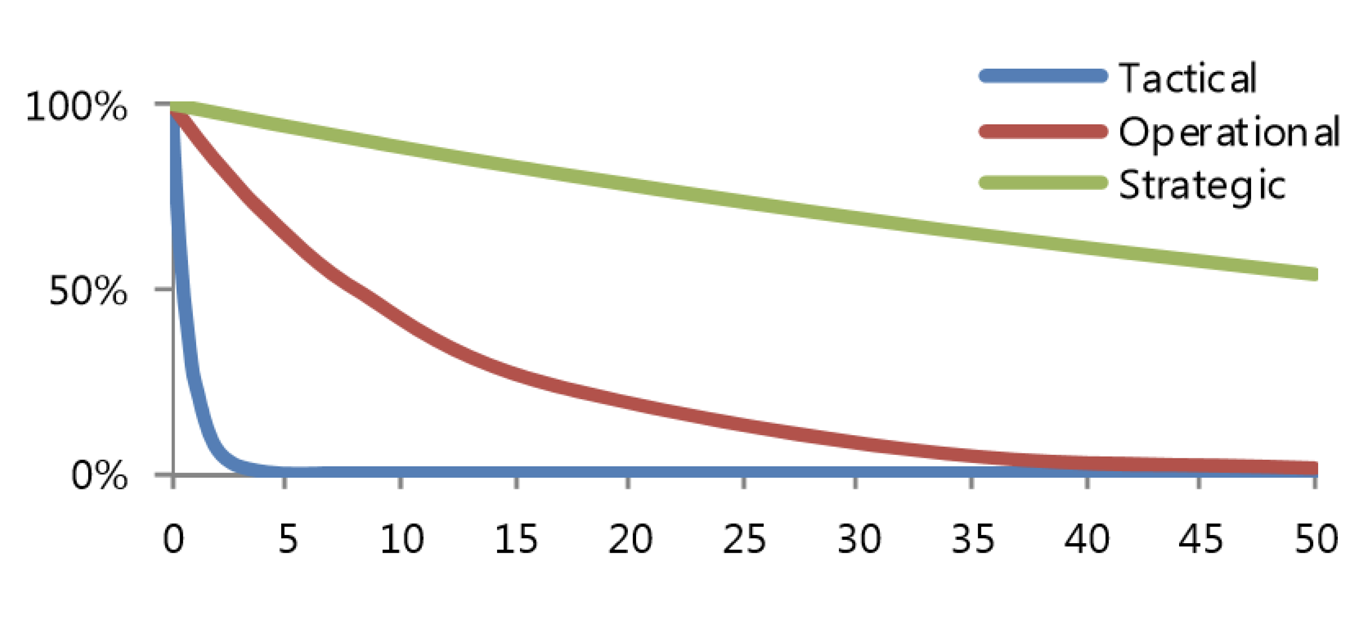
Figure 1-1. The sharply decreasing value of data over time
(source: The Half Life of Data, Nucleus Research, January 2017)
Examples bring research findings like this to life. Consider the case of a leading European payments processor, which we’ll call U Pay. It handles millions of mobile, online and in-store transactions daily for hundreds of thousands of merchants in more than 100 countries. Part of U Pay’s value to merchants is that it credit-checks each transaction as it happens. But loading data in batch to the underlying data lake with Sqoop, an open source ingestion scripting tool for Hadoop, created damaging bottlenecks. The company could not integrate both the transactions from its production SQL Server and Oracle systems and credit agency communications fast enough to meet merchant demands.
U Pay decided to replace Sqoop with CDC, and everything changed. The company was able to transact its business much more rapidly and bring the credit checks in house. U Pay created a new automated decision engine that assesses the risk on every transaction on a near-real-time basis by analyzing its own extensive customer information. By eliminating the third-party agency, U Pay increased margins and improved service-level agreements (SLAs) for merchants.
Indeed, CDC is fueling more and more software-driven decisions. Machine learning algorithms, an example of artificial intelligence (AI), teach themselves as they process continuously changing data. Machine learning practitioners need to test and score multiple, evolving models against one another to generate the best results, which often requires frequent sampling and adjustment of the underlying datasets. This can be part of larger cognitive systems that also apply deep learning, natural-language processing (NLP), and other advanced capabilities to understand text, audio, video, and other alternative data formats.
Minimizing Disruptions to Production
By sending incremental source updates to analytics targets, CDC can keep targets continuously current without batch loads that disrupt production operations. This is critical because it makes replication more feasible for a variety of use cases. Your analytics team might be willing to wait for the next nightly batch load to run its queries (although that’s increasingly less common). But even then, companies cannot stop their 24×7 production databases for a batch job. Kill the batch window with CDC and you keep production running full-time. You also can scale more easily and efficiently carry out high-volume data transfers to analytics targets.
Reducing WAN Transfer Cost
Cloud data transfers have in many cases become costly and time-consuming bottlenecks for the simple reason that data growth has outpaced the bandwidth and economics of internet transmission lines. Loading and repeatedly reloading data from on-premises systems to the cloud can be prohibitively slow and costly.
“It takes more than two days to move a terabyte of data across a relatively speedy T3 line (20 GB/hour),” according to Wayne Eckerson and Stephen Smith in their Qlik-commissioned report “Seven Considerations When Building a Data Warehouse Environment in the Cloud” (April 2017). They elaborate:
And that assumes no service interruptions, which might require a full or partial restart…Before loading data, administrators need to compare estimated data volumes against network bandwidth to ascertain the time required to transfer data to the cloud. In most cases, it will make sense to use a replication tool with built-in change data capture (CDC) to transfer only deltas to source systems. This reduces the impact on network traffic and minimizes outages or delays.
In summary, CDC helps modernize data environments by enabling faster and more accurate decisions, minimizing disruptions to production, and reducing cloud migration costs. An increasing number of organizations are turning to CDC, both as a foundation of replication platforms such as Qlik Replicate (formerly Attunity Replicate) and as a feature of broader extract, transform, and load (ETL) offerings such as Microsoft SQL Server Integration Services (SSIS). It uses CDC to meet the modern data architectural requirements of real-time data transfer, efficiency, scalability, and zero-production impact. In Chapter 2, we explore the mechanics of how that happens.
Get Streaming Change Data Capture now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

