Chapter 3. A Tour of Spark’s Toolset
In Chapter 2, we introduced Spark’s core concepts, like transformations and actions, in the context of Spark’s Structured APIs. These simple conceptual building blocks are the foundation of Apache Spark’s vast ecosystem of tools and libraries (Figure 3-1). Spark is composed of these primitives—the lower-level APIs and the Structured APIs—and then a series of standard libraries for additional functionality.
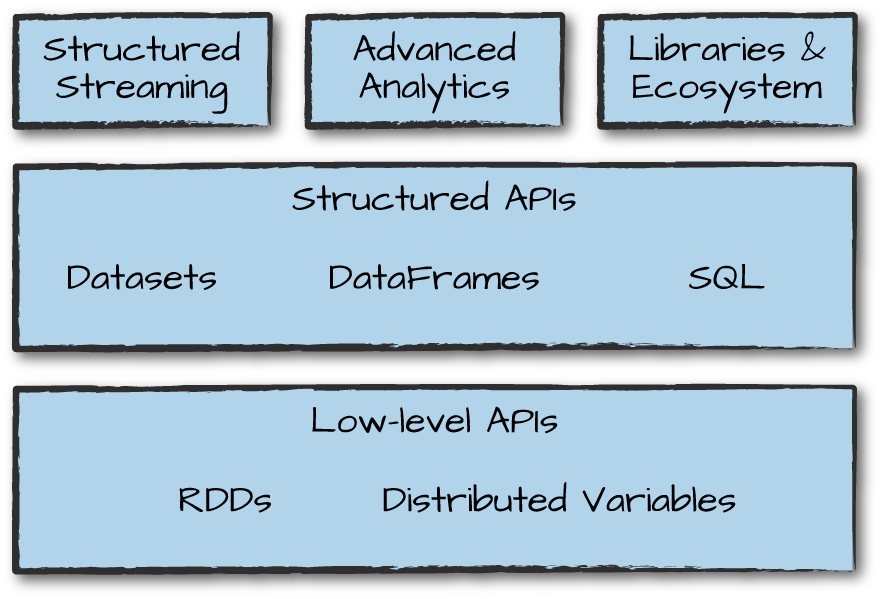
Figure 3-1. Spark’s toolset
Spark’s libraries support a variety of different tasks, from graph analysis and machine learning to streaming and integrations with a host of computing and storage systems. This chapter presents a whirlwind tour of much of what Spark has to offer, including some of the APIs we have not yet covered and a few of the main libraries. For each section, you will find more detailed information in other parts of this book; our purpose here is provide you with an overview of what’s possible.
This chapter covers the following:
-
Running production applications with
spark-submit -
Datasets: type-safe APIs for structured data
-
Structured Streaming
-
Machine learning and advanced analytics
-
Resilient Distributed Datasets (RDD): Spark’s low level APIs
-
SparkR
-
The third-party package ecosystem
After you’ve taken the tour, you’ll be able to jump to the corresponding parts of the book to find answers to your questions ...
Get Spark: The Definitive Guide now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

