112 Solving Operational Business Intelligence with InfoSphere Warehouse Advanced Edition
multidimensional expressions (MDXs) as the query language. However, the data
is not copied or persisted in another storage mechanism, but remains in the DB2
relational database.
Cubing Services thus is what we refer to as a “multidimensional OLAP hot
cache.” That is, InfoSphere Warehouse Cubing Services loads data into a
multidimensional structure in memory.
That partial MOLAP structure can then deliver fast response times for the data
that is in memory cache. If a user of a query tool requests data that is not in the
cache, the Cubing Services engine generates queries to the relational database
to retrieve the data and builds a partial in-memory cube-like structure for only
that data. Although the first request for that data sees a longer response time
while the in-memory structures are being built, subsequent requests for that data
are satisfied from the in-memory structures and experience MOLAP-style
response times while that data is maintained in memory.
Using Cubing Services as the OLAP engine results in a MOLAP-style response
in a large percentage of queries without the need to copy the data into another
storage mechanism. To improve the relational access, there is an optimization
wizard that recommends the appropriate MQTs that can be implemented to
improve the response of aggregated data when it is needed from the relational
database.
4.4.1 Cube model dimensional concepts
Before creating any cube models, it is important o understand the components
that make up such a model, and to understand their association to the fact and
dimensional tables that make up the dimensional model based on a star schema.
Cube models have four main core ingredients, which themselves have a number
of additional elements. These four ingredients are listed here.
Fact: derived from the fact table within the dimensional model, and which
contain:
– Measures: derived from the columns or calculated.
Dimension: derived from the dimension table within the dimensional model,
and which contain:
– Hierarchies: aggregates of data.
– Levels: the granularity of the data with uniquely identifiable attributes.
– Attributes: identifiable entities.
Joins: derived from the relationship between tables:
– Joins between fact and dimension tables, in a star schema.
Chapter 4. Data modeling: End to end 113
– Joins between multiple dimension tables, in a snow flake schema.
Cube: an instance of parts or a complete cube model implemented as a cube
service.
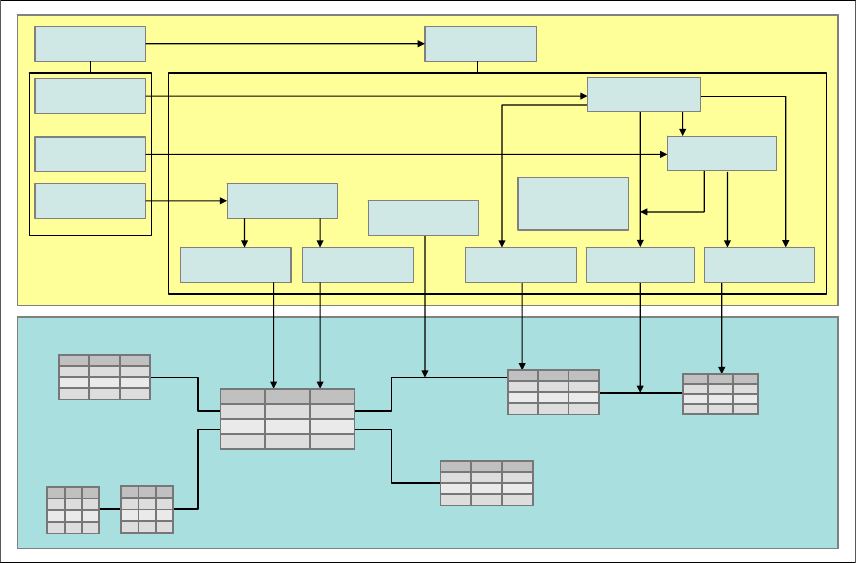
Figure 4-16 illustrates the components of a cube model and their relationship to a
the tables in a warehouse database.
Figure 4-16 Relationship between cube model and tables in a relational database
Fact element
In a dimensional model, the fact table holds the central position within the star
schema, with all the dimensional tables linked to this one table. In a cube model,
the
fact element maintains a similar central position, with the dimensional
elements connected, this time as a defined join. This means, within the definition
of the cube model, you have to define a set of SQL queries that join the fact table
to the individual dimensional tables within the relational database.
A fact object also contains a set of measures or metrics that best describes how
to aggregate data from the fact table, across dimensions. These measures or
metrics can be drawn directly from fact table columns, or derived through
Attribute
Relationship
Cube
Cube Dimension
Cube Hierarchy
Cube Facts
Cube Model
JoinMeasureMeasure
Facts
Cube
Metadata
Fact tables
Dimension tables
Dimension tables
Dimension tables
Relational tables in DB2
AttributeAttribute
Join
Hierarchy
Dimension
Get Solving Operational Business Intelligence with InfoSphere Warehouse Advanced Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

