Chapter 1. Motivation
WE LIVE IN HARD TIMES. THE SOCIAL MARKET ECONOMY IS BEING REPLACED BY A GLOBAL MARKET economy, and the marketing guys rule the world. As a consequence, you have to be fast and flexible to survive. It’s a renaissance of Darwinism:
It is not the strongest of the species that survive, nor the most intelligent, but the ones most responsive to change.
The key is flexibility. For all major companies and large distributed systems, information technology (IT) flexibility is paramount. In fact, IT has become a key business value enabler.
At the same time, processes and systems are also becoming more and more complex. We have left the stage where automation was primarily a matter of individual systems, and are fast moving toward a world where all those individual systems will become one distributed system. The challenge is maintainability.
It turns out that the old ways of dealing with the problems of scalability and distribution don’t work anymore. We can no longer harmonize or maintain control. Centralization, the precondition for harmonization and control, does not scale, and we have reached its limits. For this reason, we need a new approach—an approach that accepts heterogeneity and leads to decentralization.
In addition, we have to solve the problem of the business/IT gap. This gap is primarily one of semantics—business people and IT people appear to speak and think in entirely different languages. The new approach must bring business and IT much closer than ever before.
Service-oriented architecture (SOA) is exactly what’s needed. It’s an approach that helps systems remain scalable and flexible while growing, and that also helps bridge the business/IT gap. The approach consists of three major elements:
Services, which on the one hand represent self-contained business functionalities that can be part of one or more processes, and on the other hand, can be implemented by any technology on any platform.
A specific infrastructure, called the enterprise service bus (ESB), that allows us to combine these services in an easy and flexible manner.
Policies and processes that deal with the fact that large distributed systems are heterogeneous, under maintenance, and have different owners.
SOA accepts that the only way to maintain flexibility in large distributed systems is to support heterogeneity, decentralization, and fault tolerance.
Sounds like a dream, doesn’t it?
The problem is that you can’t just buy SOA; you have to understand it and live it. SOA is a paradigm. SOA is a way of thinking. SOA is a value system for architecture and design.
This book will explain the paradigm and value system of SOA, drawing on real experiences. SOA is often explained with brief statements and prototypes, which leads to a problem illustrated by the infamous “hockey stick function” (see Figure 1-1).[1] Up to a certain level of complexity, the amount of effort required is low, and things look fine. But when this level of complexity is exceeded, the amount of effort required suddenly begins to rise faster than the benefit you gain, and finally, things collapse.

Too often, SOA is only partly explained and installed. Just introducing an infrastructure like Web Services might help up to a certain level of complexity, but this is not enough to guarantee scalability. The whole architecture, dealing with services, infrastructure, policies, and processes, must match. Once you understand how to implement SOA, it’s not hard, but it takes time and courage. (OK, so it is hard.) And a lot of effort is required to help people understand (beginning with yourself). If you’re not willing to put in the effort, you will fail.
Before we get into the details, I’d like to provide a foundation for the rest of this book by talking about the context and history of SOA. The following sections will present some of the “tales and mystery” of SOA to help you get familiar with SOA.
Characteristics of Large Distributed Systems
SOA is a concept for large distributed systems. To understand SOA, you have to understand the properties of large distributed systems.
First, large systems must deal with legacies. You can’t introduce SOA by designing everything from scratch. You have to deal with the fact that most of the systems that are in use will remain in use. This also means that establishing SOA is not a project like designing a new system. It involves changing the structure of an existing system, which means you have to deal with old platforms and backward-compatibility issues. In fact, SOA is an approach for the maintenance of large system landscapes.
By nature, all large systems are also heterogeneous. These systems have different purposes, times of implementation, and ages, and you will find that the system landscapes are accretions of different platforms, programming languages, programming paradigms, and even middleware. In the past, there have been many attempts to solve the problems of scalability by harmonization. And, yes, harmonization helps. Withdrawing old platforms or systems that are no longer maintainable is an important improvement. But chances are that your systems will never be fully harmonized. Right before you remove the last piece of heterogeneity, a company merger, or some other change will open Pandora’s box again.
One reason for the heterogeneity is that large systems and their data have an incredibly long lifetime. During this lifetime, new functionality that promotes the business is developed by adding new systems and processes. Removing existing systems and data may seem to have no business value, but such changes are investments in the maintainability of your system. Often, these investments come too late, and become incredibly expensive because the systems are out of control, and all the knowledge about them is gone.
By nature, large systems are complex. For this reason, finding out the right places for and determining the effects of modifications can be tough. As [Spanyi03] states:
There is no such thing as a “quick fix . . . “. Organizations are complex business systems, within which a change in any one component is likely to have an impact on other components.
Large distributed systems also have an important additional property: different owners. Different teams, departments, divisions, or companies may maintain the systems, and that means different budgets, schedules, views, and interests must be taken into account. Independent from formal structures, you are usually not in a situation where you have enough power and control to command the overall system design and behavior. Negotiation and collaboration are required, which can be problematic due to political intrigue.
Another key characteristic of large systems is imperfection. Perfectionism is just too expensive. Or, as Winston Churchill once said:
Perfectionism spells P-A-R-A-L-Y-S-I-S.
Working systems usually behave a bit sloppily. They may do 99 percent of their work well, but run into trouble with the remaining 1 percent, which usually results in additional manual effort, the need for problem management, or angry customers. Note that the amount of imperfection differs (vitally important systems usually have a higher ratio of perfection, but even for them, there is always a point at which eliminating a risk is not worth the effort).
Similarly, large systems always have a certain amount of redundancy. While some redundancy might be accidental, there will also be a significant amount of intentional and “managed” redundancy, because in practice, it is just not possible to have all data normalized so that it is stored in only one place. Eliminating redundancy is difficult, and incurs fundamental runtime penalties. In a simple form of redundancy, at least the master of the data is clear (all redundant data is derived from it). In complex scenarios, there are multiple masters, and/or the master is not clearly defined. Maintaining consistency can thus become very complicated in real-world scenarios.
Finally, for large systems, bottlenecks are suicide. That does not mean that they do not exist, but in general, it is a goal to avoid bottlenecks, and to be able to scale. Note that I don’t only mean technical bottlenecks. In large systems, bottlenecks also hinder scalability when they are part of a process or the organizational structure.
The Tale of the Magic Bus
Once upon a time, there was a company that had grown over years and years. Over the course of those years, the system landscape became infected with a disease called “mess.” As a consequence, the people lost control over their system, and whenever they tried to improve it, either the effort required proved too high, or they made things even worse.
The company asked several experts, sages, and wizards for help, and they came up with a lot of ideas introducing new patterns, protocols, and system designs. But as a consequence, things only got worse and worse, so the company became desperate.
One day, a prince called Enterprise Integrate came along, and claimed that he had the solution. He told the CEO of the company, “Your problem is your lack of interoperability. When you have such a mess of systems and protocols, it is a problem that you have to create an individual solution for each kind of connection. Even if you only had 10 different platforms and 5 different protocols, if you wanted to enable each platform to communicate with each other platform, you would need over 100 different solutions. And you have many more than 10 platforms.” The exact way this number was arrived at was not passed on, but some sketches of the processing led to the conclusion that each possible connection of two platforms was combined with the average number of used protocols.
“Look at my drawing,” the prince continued (it’s reproduced here in Figure 1-2). “This is how your problem gets solved. We create a Magic Bus.”
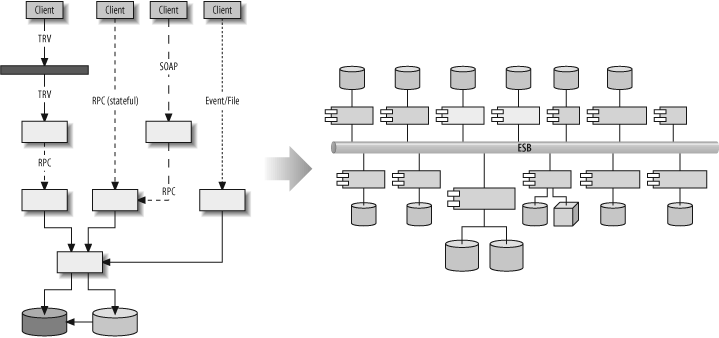
“What’s a Magic Bus?” the CEO asked.
The prince answered, “A Magic Bus is a piece of software that reduces the number of connections and interfaces in your system. While your approach might require up to n × (n−1)/2 connections for n systems (and twice as many interfaces), the Magic Bus requires only one connection and interface for each system. That means that for n systems, the number of interfaces is reduced by a factor of n−1 (a factor of 9 for 10 systems, 29 for 30 systems, and 49 for 50 systems).”
Convinced by these numbers, the CEO agreed to switch to this new technique. The praise for it was so strong that all over the country, the bards started to write songs about the Magic Bus. The most famous was written by a band called The Who, who praised the bus with the following words (see [MagicBus] for the complete lyrics of the song):
Magic Bus - It’s a bus-age wonder
You might expect an “and they lived happily ever after” now, but the tale doesn’t end here. After the company had switched to the Magic Bus, it was indeed very easy to connect systems, and suddenly it became very easy to grow again. So the systems grew and grew and grew...until suddenly, it all broke down.
What happened?
It turned out that with the Magic Bus, nobody could understand the dependencies among the systems any longer. In the past, you could see which systems were connected because each connection was unique, but this was no longer possible. Modifying one system could cause problems in other systems, and it was often a surprise that relationships existed between them at all. In fact, each system depended on each other system. When the risk of modifying anything became too high, the company decided to leave the entire system as it was. But slack means death, so one year later, they were out of business.
Of course, they should have known what was coming. Attentive listeners of The Who’s song will hear at the end a clear hint about the danger of the “dust” raised by unstructured dependencies created by the Magic Bus:
Every day you’ll see the dust As I drive my baby in my Magic Bus
And the competitors lived happily ever after.
What We Can Learn from the Tale of the Magic Bus
These days, we often praise the “bus-age wonder.”[2] Although the idea of an IT bus is pretty old, recently, there has been a renaissance of this concept. It started with the introduction of the enterprise application integration bus (EAI bus), which was later replaced by the enterprise service bus (ESB). This has become so important that there has been a public flame war about who invented the ESB (see [ESB Inventor]).
Buses represent high interoperability. The idea behind them is that instead of creating and maintaining individual communication channels between different systems, each system only has to connect to the bus to be able to connect to all other systems. Of course, this does simplify connectivity, but as the preceding tale revealed, this approach has drawbacks. Connectivity scales to chaos unless structures are imposed. That’s why we replaced global variables with procedures, and business object models with modules and components. And it will happen again when we start to deal with services in an unstructured way.
Thus, your first lesson is that in order for large systems to scale, more than just interoperability is required. You need structures provided by technical and organizational rules and patterns. High interoperability must be accompanied by a well-defined architecture, structures, and processes. If you realize this too late, you may be out of the market.
History of SOA
Surprisingly, it is hard to find out who coined the term SOA. Roy Schulte at Gartner gave me the exact history in a private conversation in 2007:
Alexander Pasik, a former analyst at Gartner, coined the term SOA for a class on middleware that he was teaching in 1994. Pasik was working before XML or Web Services were invented, but the basic SOA principles have not changed.
Pasik was driven to create the term SOA because “client/server” had lost its classical meaning. Many in the industry had begun to use “client/server” to mean distributed computing involving a PC and another computer. A desktop “client” PC typically ran user-facing presentation logic, and most of the business logic. The backend “server” computer ran the database management system, stored the data, and sometimes ran some business logic. In this usage, “client” and “server” generally referred to the hardware. The software on the frontend PC sometimes related to the server software in the original sense of client/server, but that was largely irrelevant. To avoid confusion between the new and old meanings of client/server, Pasik stressed “server orientation” as he encouraged developers to design SOA business applications.
Note
Gartner analysts Roy W. Schulte and Yefim V. Natis published the first reports about SOA in 1996. See [Gartner96] and [Gartner03] for details.
The real momentum for SOA was created by Web Services, which, initially driven by Microsoft, reached a broader public in 2000 (see History of Web Services for details about the history of Web Services). To quote [Gartner03]:
Although Web Services do not necessarily translate to SOA, and not all SOA is based on Web Services, the relationship between the two technology directions is important and they are mutually influential: Web Services momentum will bring SOA to mainstream users, and the best-practice architecture of SOA will help make Web Services initiatives successful.
Soon, other companies and vendors jumped in (including major IT vendors such as IBM, Oracle, HP, SAP, and Sun). There was money to be made by explaining the idea, and by selling new concepts and tools (or rebranded concepts and tools). In addition, the time was right because companies were increasingly seeking to integrate their businesses with other systems, departments, and companies (remember the B2B hype).
Later, analysts began to tout SOA as the key concept for future software. For example, in 2005, Gartner stated in [Gartner05]:
By 2008, SOA will provide the basis for 80 percent of development projects.
Time will show whether this statement is borne out—it may well be a self-fulfilling prophecy.
However, each major movement creates criticism because people hype and misuse the concept as well as the term. Grady Booch, a father of UML and now an IBM fellow, made this comment about SOA in his blog in March 2006 (see [Booch06]):
My take on the whole SOA scene is a bit edgier than most that I’ve seen. Too much of the press about SOA makes it look like it’s the best thing since punched cards. SOA will apparently not only transform your organization and make you more agile and innovative, but your teenagers will start talking to you and you’ll become a better lover. Or a better shot if your name happens to be Dick. Furthermore, if you follow many of these pitches, it appears that you can do so with hardly any pain: just scrape your existing assets, plant services here, there, and younder [sic], wire them together and suddenly you’ll be virtualized, automatized, and servicized.
What rubbish.
Booch is right. The important thing is that SOA is a strategy that requires time and effort. You need some experience to understand what SOA really is about, and where and how it helps. Fortunately, it’s been around long enough that some of us do have significant experience with SOA (beyond simple prototypes and vague notions of integrating dozens of systems with hundreds of services).
SOA in Five Slides
The rest of this book will discuss several aspects of SOA in practice. That means we’ll go a bit deeper than the usual “five slides” approach, which presents SOA in such a simple way that everybody wonders what’s so complicated and/or important about it.
Still, to give you an initial idea about the essence of what you will learn, here are my five slides introducing SOA. Bear in mind that these five slides give an oversimplified impression. The devil is in the details. Nevertheless, this overview might look a bit different from the usual advertisement for SOA.
Slide 1: SOA
Service-oriented architecture (SOA) is a paradigm for the realization and maintenance of business processes that span large distributed systems. It is based on three major technical concepts: services, interoperability through an enterprise service bus, and loose coupling.
A service is a piece of self-contained business functionality. The functionality might be simple (storing or retrieving customer data), or complex (a business process for a customer’s order). Because services concentrate on the business value of an interface, they bridge the business/IT gap.
An enterprise service bus (ESB) is the infrastructure that enables high interoperability between distributed systems for services. It makes it easier to distribute business processes over multiple systems using different platforms and technologies.
Loose coupling is the concept of reducing system dependencies. Because business processes are distributed over multiple backends, it is important to minimize the effects of modifications and failures. Otherwise, modifications become too risky, and system failures might break the overall system landscape. Note, however, that there is a price for loose coupling: complexity. Loosely coupled distributed systems are harder to develop, maintain, and debug.
Slide 2: Policies and Processes
Distributed processing is not a technical detail. Distributed processing changes everything in your company. Introducing new functionality is no longer a matter of assigning a specific department a specific task. It is now a combination of multiple tasks for different systems. These systems and the involved teams have to collaborate.
As a consequence, you need clearly defined roles, policies, and processes. The processes include, but are not limited to, defining a service lifecycle and implementing model-driven service development. In addition, you have to set up several processes for distributed software development.
Setting up the appropriate policies and processes usually takes more time than working out the initial technical details. Remember what Fred Brooks said in 1974 (see [Brooks95]):
A programming system product costs 9 times as much as a simple program.
A factor of three is added because it’s a product (with the software being “run, tested, repaired, and extended by anybody”), and another factor of three is added because it’s a system component (effort is introduced by integration and integration tests). The factor increases when many components come into play, which is the case with SOA.
Slide 3: Web Services
Web Services are one possible way of realizing the technical aspects of SOA. (Note, however, that there is more to SOA than its technical aspects!)
But Web Services themselves introduce some problems. First, the standards are not yet mature enough to guarantee interoperability. Second, Web Services inherently are insufficient to achieve the right amount of loose coupling.
As a consequence, you should not expect that using Web Services will solve all your technical problems. You should budget enough resources (time and money) to solve the problems that will remain.
Also, you should not fall into the trap of getting too Web Services-specific. Web Services will not be the final standard for system integration. For this reason, let Web Services come into play only when specific infrastructure aspects matter.
Slide 4: SOA in Practice
Of course, this also applies to SOA. General business cases and concepts might not work as well as expected when factors such as performance and security come into play.
In addition, the fact that SOA is a strategy for existing systems under maintenance leads to issues of stability and backward compatibility.
And, in IT, each system is different. As a consequence, you will have to build your specific SOA—you can’t buy it. To craft it, you’ll need time and an incremental and iterative approach.
Note in addition that whether you introduce SOA is not what’s important. The important thing is that the IT solution you introduce is appropriate for your context and requirements.
Slide 5: SOA Governance and Management Support
Probably the most important aspect of SOA is finding the right approach and amount of governance:
You need a central team that will determine general aspects of your specific SOA. However, the ultimate goal is decentralization (which is key for large systems), so you’ll have to find the right balance between centralization and decentralization.
You need the right people. Large systems are different from small systems, and you need people who have experience with such systems. When concepts don’t scale for practical reasons, inexperienced people will try to fight against those practical reasons instead of understanding that they are inherent properties of large systems. In addition, central service teams often tend to become ivory towers. They must be driven by the requirements of the business teams. In fact, they have to understand themselves as service providers for service infrastructures.
First things first. Don’t start with the management of services. You need management when you have many services. Don’t start with an approach that first designs all services or first provides the infrastructure. It all must grow together, and while it’s growing, you’ll have enough to do with solving the current problems to worry about those that will come later.
Last but not least, you need support from the CEO and CIO. SOA is a strategy that affects the company as a whole. Get them to support the concept, to make appropriate decisions, and to give enough time and money. Note that having a lot of funding in the short term is not the most important thing. You need money for the long run. Cutting SOA budgets when only half of the homework is complete is a recipe for disaster.
Get SOA in Practice now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

