Chapter 1. Overview
Before we get into the inner workings and challenges of serverless computing, or Function as a Service (FaaS), we will first have a look at where it sits in the spectrum of computing paradigms, comparing it with traditional three-tier apps, microservices, and Platform as a Service (PaaS) solutions. We then turn our attention to the concept of serverless computing; that is, dynamically allocated resources for event-driven function execution.
A Spectrum of Computing Paradigms
The basic idea behind serverless computing is to make the unit of computation a function. This effectively provides you with a lightweight and dynamically scalable computing environment with a certain degree of control. What do I mean by this? To start, let’s have a look at the spectrum of computing paradigms and some examples in each area, as depicted in Figure 1-1.

Figure 1-1. A spectrum of compute paradigms
In a monolithic application, the unit of computation is usually a machine (bare-metal or virtual). With microservices we often find containerization, shifting the focus to a more fine-grained but still machine-centric unit of computing. A PaaS offers an environment that includes a collection of APIs and objects (such as job control or storage), essentially eliminating the machine from the picture. The serverless paradigm takes that a step further: the unit of computation is now a single function whose lifecycle you manage, combining many of these functions to build an application.
Looking at some (from an ops perspective), relevant dimensions further sheds light on what the different paradigms bring to the table:
- Agility
-
In the case of a monolith, the time required to roll out new features into production is usually measured in months; serverless environments allow much more rapid deployments.
- Control
-
With the machine-centric paradigms, you have a great level of control over the environment. You can set up the machines to your liking, providing exactly what you need for your workload (think libraries, security patches, and networking setup). On the other hand, PaaS and serverless solutions offer little control: the service provider decides how things are set up. The flip side of control is maintenance: with serverless implementations, you essentially outsource the maintenance efforts to the service provider, while with machine-centric approaches the onus is on you. In addition, since autoscaling of functions is typically supported, you have to do less engineering yourself.
- Cost per unit
-
For many folks, this might be the most attractive aspect of serverless offerings—you only pay for the actual computation. Gone are the days of provisioning for peak load only to experience low resource utilization most of the time. Further, A/B testing is trivial, since you can easily deploy multiple versions of a function without paying the overhead of unused resources.
The Concept of Serverless Computing
With this high-level introduction to serverless computing in the context of the computing paradigms out of the way, we now move on to its core tenents.
At its core, serverless computing is event-driven, as shown in Figure 1-2.
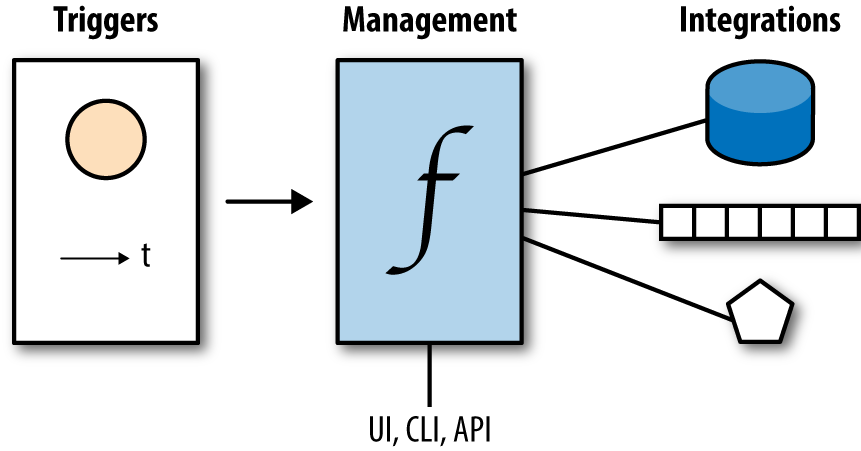
Figure 1-2. The concept of serverless compute
In general, the main components and actors you will find in serverless offerings are:1
- Management interfaces
-
Register, upgrade, and control functions via web UIs, command-line interfaces, or HTTP APIs.
- Triggers
-
Define when a function is invoked, usually through (external) events, and are scheduled to be executed at a specific time.
- Integration points
-
Support control and data transfer from function-external systems such as storage.
So, the serverless paradigm boils down to reacting to events by executing code that has been uploaded and configured beforehand.
Conclusion
In this chapter we have introduced serverless computing as an event-driven function execution paradigm with its three main components: the triggers that define when a function is executed, the management interfaces that register and configure functions, and integration points that interact with external systems (especially storage). Now we’ll take a deeper look at the concrete offerings in this space.
1 I’ve deliberately left routing (mapping, for example, an HTTP API to events) out of the core tenents since different offerings have different approaches for how to achieve this.
Get Serverless Ops now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

