Taking into account the goals of data preparation, Scala was chosen as an easy and interactive way to manipulate data:
val priceDataFileName: String = "bitstampUSD_1-min_data_2012-01-01_to_2017-10-20.csv"val spark = SparkSession .builder() .master("local[*]") .config("spark.sql.warehouse.dir", "E:/Exp/") .appName("Bitcoin Preprocessing") .getOrCreate()val data = spark.read.format("com.databricks.spark.csv").option("header", "true").load(priceDataFileName)data.show(10)>>>
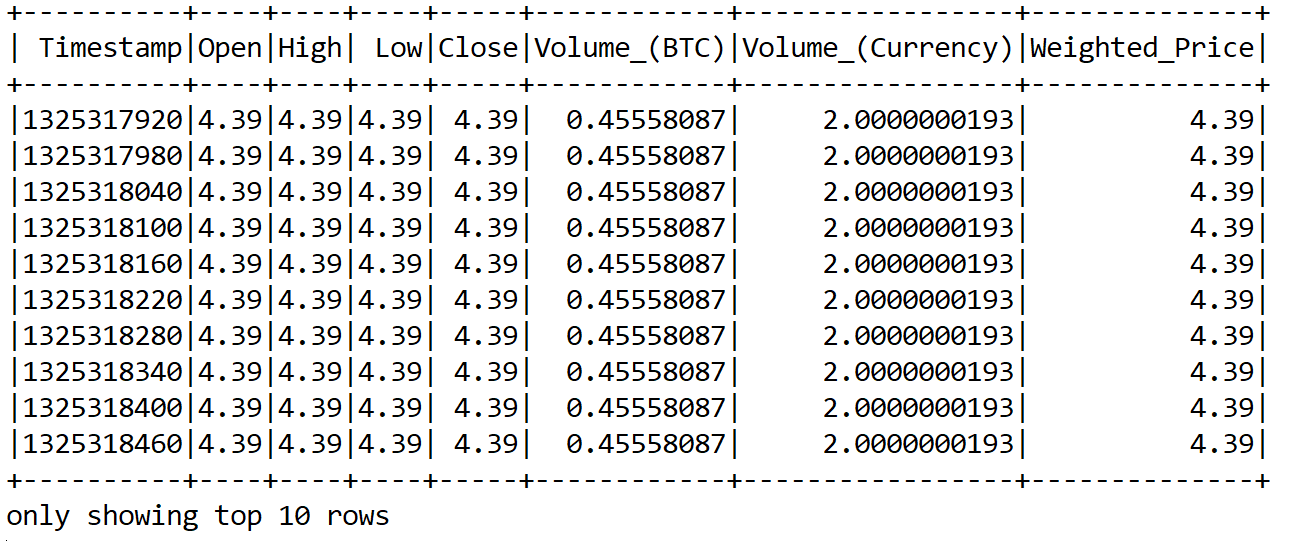
Figure 5: A glimpse of the Bitcoin historical price dataset
println((data.count(), data.columns.size))
>>>
(3045857, 8)
In the preceding code, we load data ...

