The long-term reward is called a utility. It turns out that if we know the utility of performing an action upon a state, then it is easy to solve RL. For example, to decide which action to take, we simply select the action that produces the highest utility. However, uncovering these utility values is difficult. The utility of performing an action a at a state s is written as a function, Q(s, a), called the utility function. This predicts the expected immediate reward, and rewards following an optimal policy given the state-action input, as shown in Figure 4:
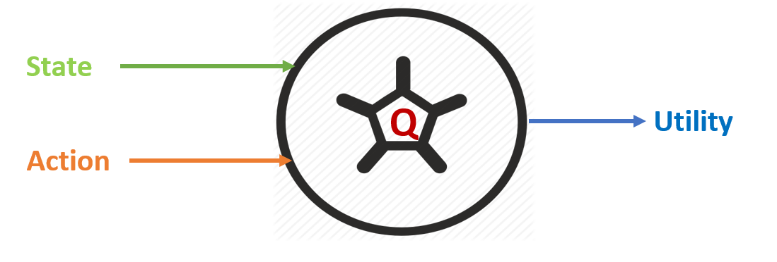
Figure 4: Using a utility function
Most RL algorithms boil down to just three ...

