Chapter 1. Our HTML Roots and Simple Web APIs
“What’s so fascinating and frustrating and great about life is that you’re constantly starting over, all the time, and I love that.”
Billy Crystal
Before jumping right into the process of creating hypermedia client applications, let’s back up a bit and join the quest at the early end of the web application’s history. Many web applications began as websites—as HTML-based pages that were little more than just a list of static documents. In some cases, the initial web app was a pure HTML app. It had tables of data, forms for filtering and adding data, and lots of links to allow the user to transition from one screen to the next (Figure 1-1).
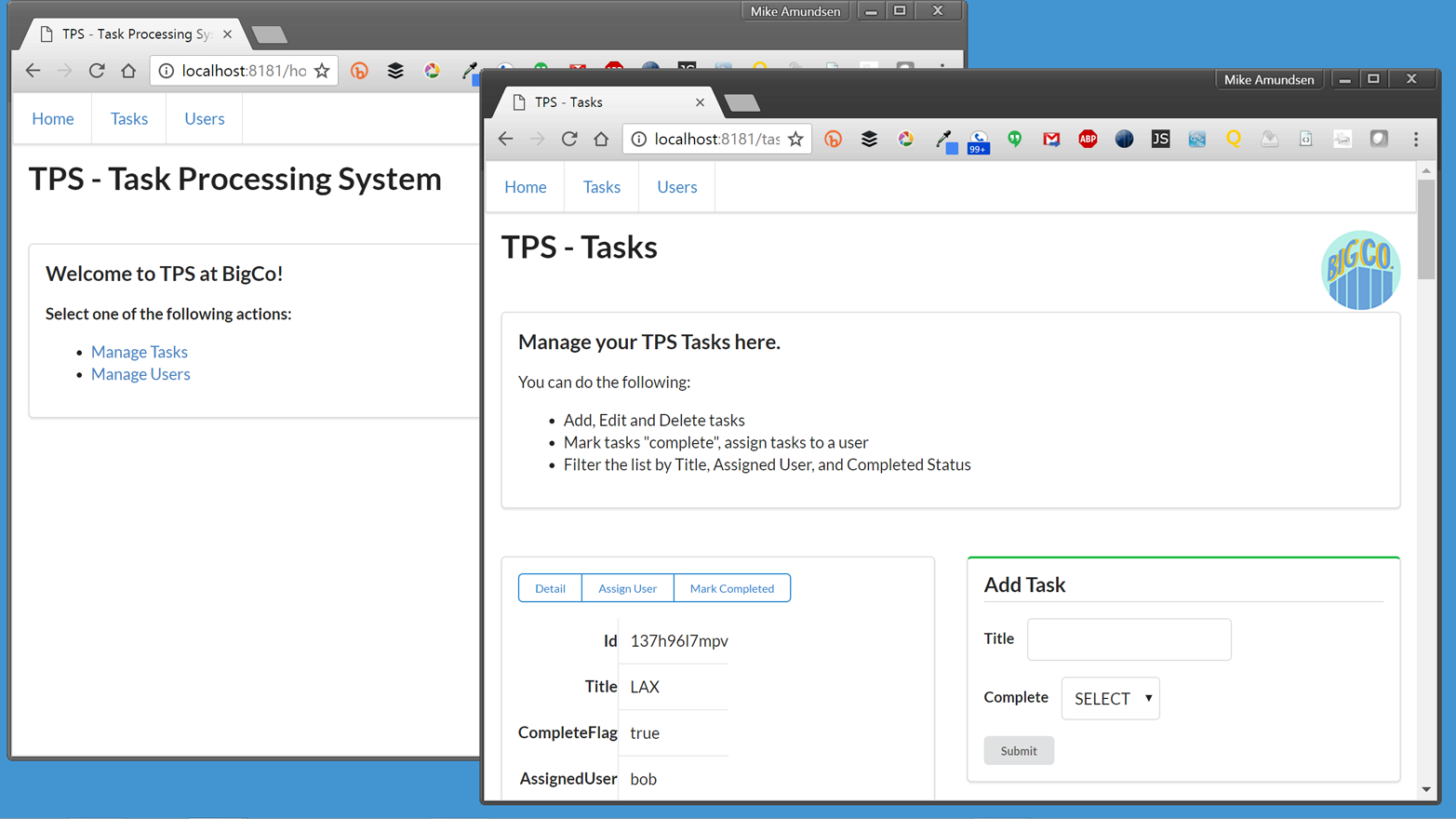
Figure 1-1. BigCo TPS screens
One of the things that make pure HTML applications interesting is that they are written in a very declarative style. They work without the need for imperative programming code within the client application. In fact, even the visual styling of HTML applications is handled declaratively—via Cascading Style Sheets (CSS).
It may seem unusual to attempt to create user experiences using only declarative markup. But it should be noted that many users in the early days of the Web were already familiar with this interaction style from the mainframe world (see Figure 1-2). In many ways, early web applications looked and behaved much like the typical monochrome experiences users had with mainframe, minicomputers, and the early personal computers (see Figure 1-3). And this was seen as a “good thing.”
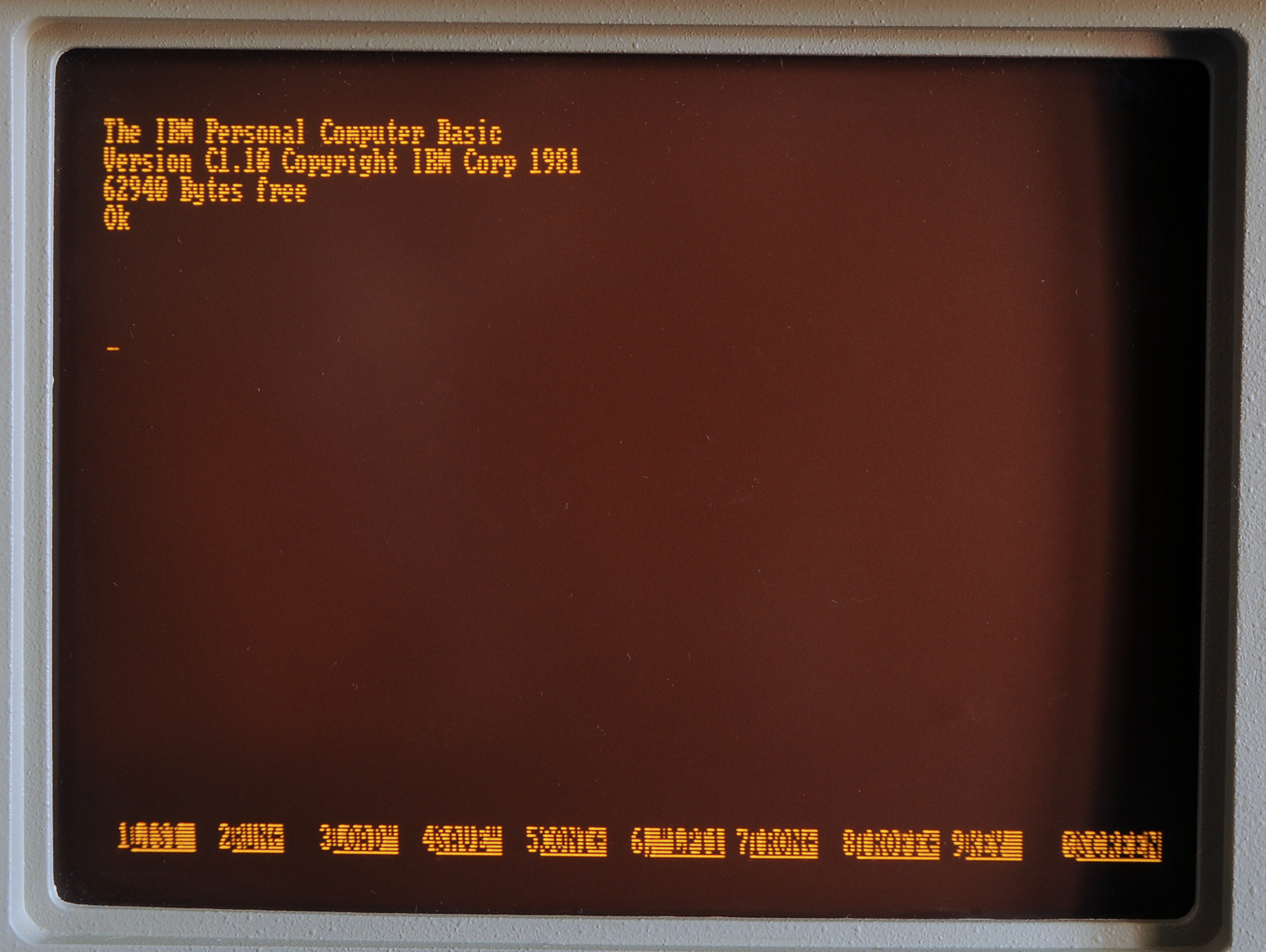
Figure 1-2. IBM Portable Personal Computer
Typically, at some point in the life of successful HTML-based web app, someone gets the idea to convert it into a web API. There are lots of reasons this happens. Some want to “unleash the value” locked inside a single application to make the underlying functionality available to a wider audience. There might be new opportunities in other UI platforms (e.g., mobile devices, rich desktop apps, etc.) that don’t support the HTML+CSS experience. Maybe someone has a new creative idea and wants to try it out. Whatever the reasons, a web API is born.
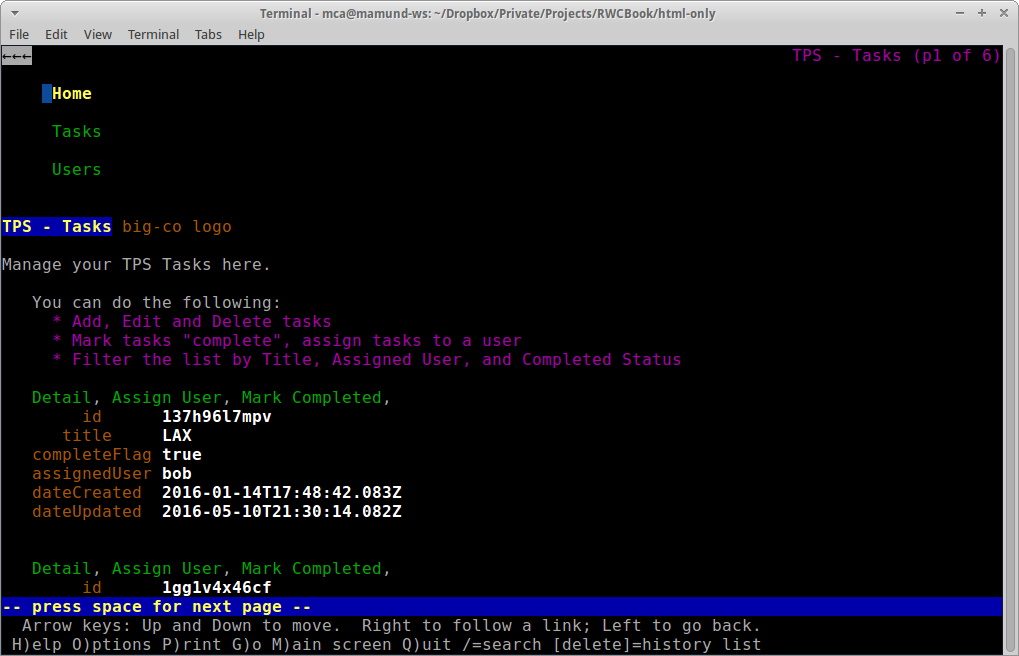
Figure 1-3. Early Lynx HTML browser
Usually, the process is seen as a straightforward effort to expose an API that covers the internal workings of the existing web app but without the baggage of the existing HTML UI. And often the initial work is just that—taking away the UI (HTML) and exposing the data model or object model within the web server code as the web API.
Next, it is assumed, a new team can build a better user interface by consuming the server-side web API directly from a client application. Often the goal is to build a native app for smartphones or an advanced web app using one of the latest client-side frameworks. The first pass at the API is usually pretty easy to understand, and building a set of client apps can go smoothly—especially if both the client- and server-side imperative code are built by the same team or by teams that share the same deep understanding of the original web app.
And that’s the part of the journey we’ll take in this chapter—from HTML to API. That will lay the groundwork for the remainder of the book as we work through the process of building increasingly robust and adaptable client applications powered by the principles and practices of hypermedia.
The Task Processing System (TPS) Web App
For quick review, Carol’s team built a web app that delivers HTML (and CSS) from the web server directly to common web browsers. This app works in any brand and version of browser (there are no CSS tricks, all HTML is standard, and there is no JavaScript at all). It also runs quickly and gets the job done by focusing on the key use cases originally defined when the app was first designed and implemented.
As you can see from Figure 1-4, the UI, while not likely to win any awards, is usable, practical, and reliable—all things we wish for in any application.
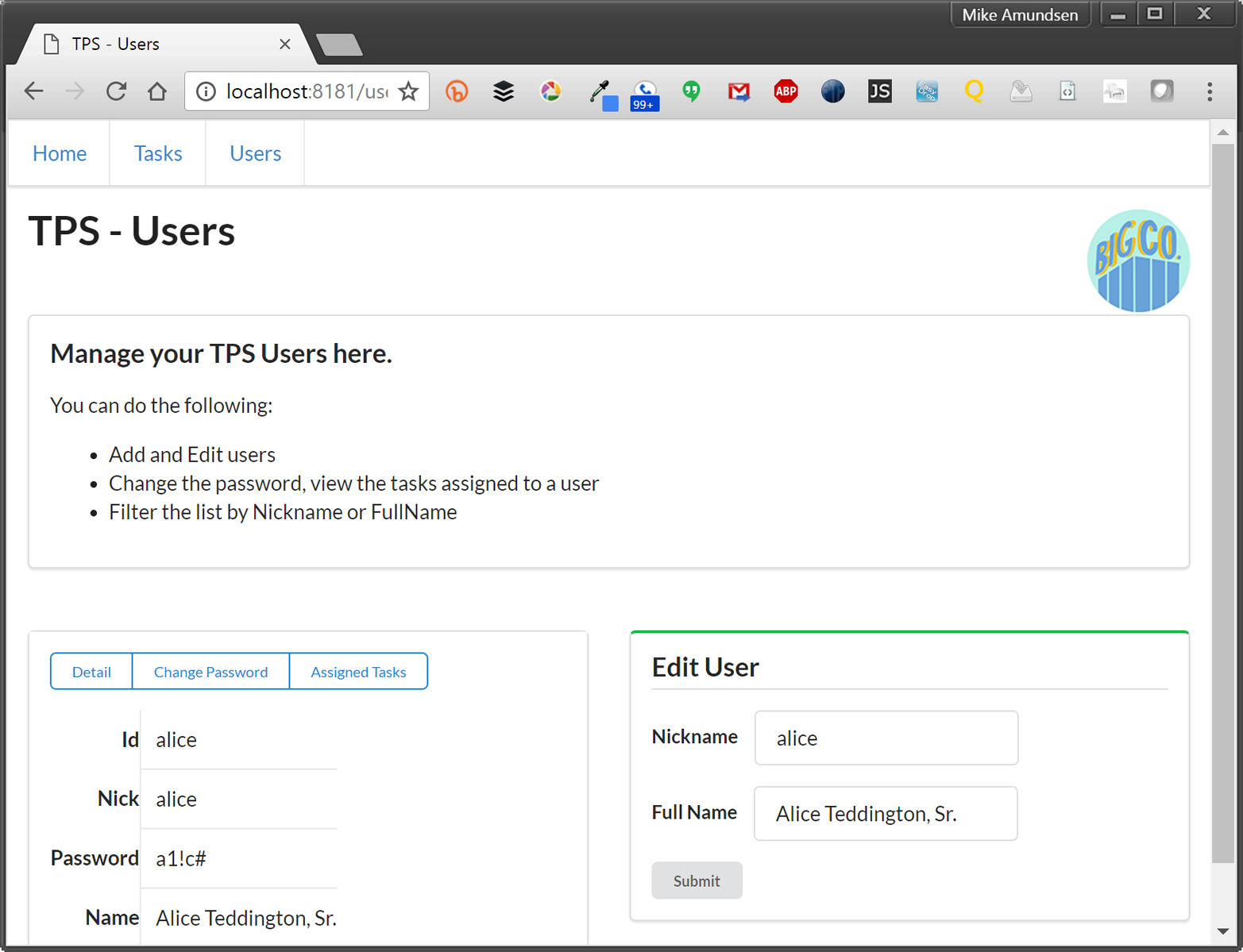
Figure 1-4. TPS user screen
Note
The source code for this version of the TPS can be found in the associated GitHub repo. A running version of the app described in this chapter can be found online.
HTML from the Server
Part of the success of the TPS app is that it is very simple. The web server delivers clean HTML that contains all the links and forms needed to accomplish the required use cases:
<ul><liclass="item"><ahref="https://rwcbook01.herokuapp.com/home/"rel="home">Home</a></li><liclass="item"><ahref="https://rwcbook01.herokuapp.com/task/"rel="collection">Tasks</a></li><liclass="item"><ahref="https://rwcbook01.herokuapp.com/user/"rel="collection">Users</a></li></ul>
For example, in the preceding code listing, you can see the HTML anchor tags (<a>…</a>) that point to related content for the current page. This set of “menu links” appear at the top of each page delivered by the TPS app:
<divid="items"><div><ahref="https://rwcbook01.herokuapp.com/user/alice"rel="item"title="Detail">Detail</a><ahref="https://rwcbook01.herokuapp.com/user/pass/alice"rel="edit"title="Change Password">Change Password</a><ahref="https://rwcbook01.herokuapp.com/task/?assignedUser=alice"rel="collection"title="Assigned Tasks">Assigned Tasks</a></div><table><tr><th>id</th><td>alice</td></tr><tr><th>nick</th><td>alice</td></tr><tr><th>password</th><td>a1!c#</td></tr><tr><th>name</th><td>Alice Teddington, Sr.</td></tr></table></div>
Each user rendered in the list by the server contains a link pointing to a single user item, and that item consists of a pointer (![]() ), a handful of data fields (
), a handful of data fields (![]() ), and some links that point to other actions that can be performed for this user (
), and some links that point to other actions that can be performed for this user (![]() and
and ![]() ). The links allow anyone viewing the page to initiate updates or password changes (assuming they have the rights to perform these actions):
). The links allow anyone viewing the page to initiate updates or password changes (assuming they have the rights to perform these actions):
<!-- add user form --><formmethod="post"action="https://rwcbook01.herokuapp.com/user/"><div>Add User</div><p><label>Nickname</label><inputtype="text"name="nick"value=""required="true"pattern="[a-zA-Z0-9]+"/></p><p><label>Full Name</label><inputtype="text"name="name"value=""required="true"/></p><p><label>Password</label><inputtype="text"name="password"value=""required="true"pattern="[a-zA-Z0-9!@#$%^&*-]+"/></p><inputtype="submit"/></form>
The HTML for adding a user is also very simple (see the preceding HTML). It is a clean HTML <form> with associated <label> and <input> elements. In fact, all the input forms in this web app look about the same. Each <form> used for queries (safe operations) has the method property set to get, and each <form> used for writes (unsafe operations) has the method property set to post. That is the only important difference in the <form> settings for this implementation.
A Note About HTML and POST
In HTTP, the POST method defines a nonidempotent, unsafe operation (RFC7231). Some of the actions in the TPS web app could be handled by an idempotent, unsafe operation, but HTML (still) does not support PUT or DELETE (the two idempotent, unsafe operations in HTTP). As Roy Fielding has pointed out in a 2009 blog post, it is certainly possible to get everything done on the Web with only GET and POST. But it would be a bit easier if some operations were idempotent since that makes replaying failed requests much easier to deal with. As of this writing, the several attempts to bring PUT and DELETE to HTML have been given a chilly reception.
Along with the typical list, read, add, edit, and remove actions, the TPS web app includes actions like Change Password for users and Assign User for tasks. The following HTML is what drives the Assign User screen (Figure 1-5 shows the screen itself):
<!-- assign user form --><formmethod="post"action="//rwcbook01.herokuapp.com/task/assign/137h96l7mpv"><div>Assign User</div><p><label>ID</label><inputtype="text"name="id"value="137h96l7mpv"readonly="readonly"/></p><p><label>User Nickname</label><selectname="assignedUser"><optionvalue="">SELECT</option><optionvalue="alice">alice</option><optionvalue="bob"selected="selected">bob</option><optionvalue="carol">carol</option><optionvalue="mamund">mamund</option><optionvalue="ted">ted</option></select></p><inputtype="submit"/></form>
Note that this form uses the HTTP POST method. Since HTML only provides GET and POST, all unsafe actions (create, update, remove) are enabled using a POST form. We’ll have to deal with this later when we convert this HTML-only web app into a web API.
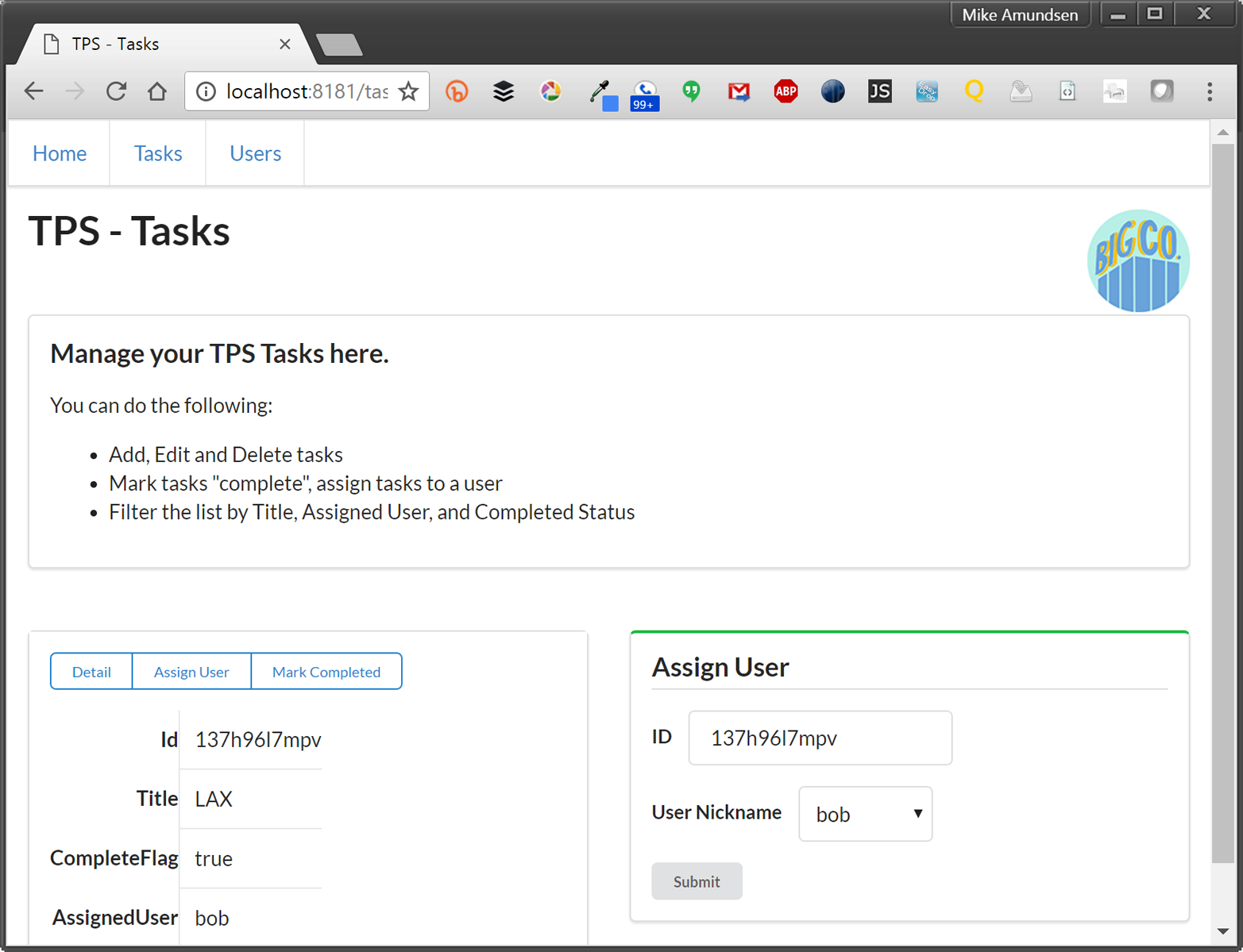
Figure 1-5. Assign user screen
Common Web Browser as the Client
The client side of common web browser applications like this one is pretty uninteresting. First, this app has no client-side JavaScript dependencies. It runs fine without any JavaScript running locally. The app does take advantage of a handful of HTML5 user experience features such as:
-
HTML
patternto perform local input validations -
HTML
requiredto guide the user in filling out important fields -
HTML
readonlyto prevent users from changing importantFORMdata
These, along with the use of a SELECT input control to supply users with valid input options, do a pretty good job of providing client-side interaction—all without relying on custom JavaScript. The CSS styling here is handled by a library called Semantic UI. It supports lots of UI design elements while still supporting reasonable HTML markup. Semantic UI libraries also support JavaScript-driven enhancements that may be used in future updates for this app.
Observations
It turns out that, at least for this web app, the client-side experience is pretty boring to talk about. There just isn’t much here to cover! That’s actually good news. The common web browser is designed to accept HTML markup and—based on the response links and forms—provide a solid user experience without the requirement of writing imperative JavaScript code.
Here are a few other observations:
- Very few “bugs”
-
Because there is no custom JavaScript code for this client, there are almost no bugs. It is possible that the server will emit broken HTML, of course. And a poorly implemented CSS rule can cause the UI to become unusable. But the fewer lines of code involved, the less likelihood a bug will be encountered. And this app has no imperative client code.
- POST-only updates
-
Because the app is limited to HTML-only responses, all data updates such as create, update, and delete, along with the domain-specific actions like
assign-userandchange-password, are handled using HTMLPOSTrequests. This is, strictly speaking, not a bug, but it does run counter to the way most web developers think about actions on the Web. The use of the nonidempotentPOSTaction does introduce a slight complication in edge cases where users are not sure if aPOSTwas successful and will attempt the action a second time. In this case, it is up to the server to prevent double-posting of adds, etc. - Links and forms
-
One of the nice things about using HTML as a response format is that it contains support for a wide range of hypermedia controls: links and forms. The TPS responses include the
<a>…</a>tag to handle simple immutable links,<form method="get">elements to handle safe searches and queries, and<form method="post">controls to handle all the unsafe write operations. Each response contains all the details for passing arguments to the server. The<input>elements even include simple client-side validation rules to validate user inputs before the data is sent to the server. Having all this descriptive information in the server responses makes it easy for the browser to enforce specific input rules without having any custom client-side code.
- Limited user experience
-
Despite the reality of a “bug-free” app and fully functional write operations via
POST, the user experience for this web app is still limited. This might be acceptable within a single team or small company, but if BigCo plans to release this app to a wider public—even to other teams within the company—a more responsive UX would be a good idea.
So, now that we have a baseline web app to start from, let’s take a look at how BigCo’s Bob and Carol can take this app to the next level by creating a server-side web API that can be used to power a standalone web client application.
The Task Services Web API
Often the next logical step in the life of an HTML-based web application is to publish a standalone web API—or application programming interface—that can be used by client applications directly. In the dialogue at the start of this chapter, Bob has taken on the task of leading the server-side team that will design, implement, and publish the Task Processing System API while Carol’s team will build the client applications that consume that API.
Tip
The source code for the JSON-based RPC-CRUD web API version of the TPS can be found in the associated GitHub repo. A running version of the app described in this chapter can be found online.
Let’s first do a quick rundown on the design process for a typical web API server followed by a review of the changes needed to convert our existing TPS HTML-only web app into a proper JSON-based RPC-CRUD web API.
Web API Common Practice
The common practice for creating web APIs is to publish a fixed set of Remote Procedure Call (RPC) endpoints expressed as URLs that allow access to the important functionality of the original application. This common practice also covers the design of those URLs, the serialized objects that are passed between server and client, and a set of guidelines on how to use HTTP methods, status codes, and headers in a consistent manner. For most web developers today, this is the state of the art for HTTP.
HTTP, REST, and Parkinson’s Law
At this point in many discussions, someone mentions the word “REST,” and a fight (literally or actually) may break out between people who want to argue about the proper way to design URLs, which HTTP headers you should not use, why it is acceptable to ignore some HTTP status codes, and so forth. Disputes about the content and meaning of IETF documents specifying the HTTP protocol, and disagreements about the shape of URLs are all subplots to the main adventure: building solid web applications. Arguing about URLs instead of discussing which interactions are needed to solve a use case is missing the point. HTTP is just tech, and REST is just a style (like punk rock or impressionist painting, etc.). Disagreeing on what is true REST or proper HTTP is a classic cases of Parkinson’s Law of Triviality—debating the trivial points while ignoring the important issues.
It turns out that designing and implementing reliable and flexible applications that live on the Web is nontrivial. It takes a clear head, an eye for the future, and a willingness to spend time engaged in systems-level thinking. Instead of focusing on those hard problems, some get caught up in disagreements on the characters in a URL or other silliness. I plan to avoid those pitfalls and just focus on the functionality.
What follows in this section is a retelling of the common practice for HTTP-based web APIs. It is not, as I will illustrate in the ensuing chapters, the only way to implement services on the Web. Once we get beyond this particular design and implementation detail we can move on to explore additional approaches.
Designing the TPS Web API
Essentially, we need to design the web API. Typically this means (1) defining a set of objects that will be manipulated via the API, and (2) applying a fixed set of actions on those objects. The actions are Create, Read, Update, and Delete—the CRUD operations. In the case of the TPS example, the list of published objects and actions would look something like that shown in Table 1-1.
| URL | Method | Returns Object | Accepts Object |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
This looks fairly simple: four endpoints and about ten operations (we’ll handle the missing one in a minute).
As you can see from the table, there are essentially two forms of the object URL: list and item. The list form of the URL contains the object name (Task or User) and supports (1) HTTP GET to return a list of objects, and (2) HTTP POST to create a new object and add it to the list. The item form of the URL contains both the object name (Task or User) and the object’s unique id value. This URL supports (1) HTTP GET to return a single object, (2) HTTP PUT to support updating the single object, and (3) HTTP DELETE to support removing that object from the collection.
However, there are some exceptions to this simple CRUD approach. Looking at the table, you’ll notice that the TPS User object does not support the DELETE operation. This is a variant to the common CRUD model, but not a big problem. We’d need to document that exception and make sure the API service rejects any DELETE request for User objects.
Also, the TPS web app offers a few specialized operations that allow clients to modify server data. These are:
TaskMarkCompleted-
Allow client apps to mark a single
Taskobject with thecompleteFlag="true" TaskAssignUser-
Allow client apps to assign a
User.nickto a singleTaskobject UserChangePassword-
Allow client apps to change the
passwordvalue ofUserobject
None of the operations just listed falls neatly into the CRUD pattern, which happens quite often when implementing web APIs. This complicates the API design a bit. Typically, these special operations are handled by creating a unique URL (e.g., /task/assign-user or /user/change-pw/) and executing an HTTP POST request with a set of arguments to pass to the server.
Finally, the TPS web API supports a handful of filter operations that need to be handled. They are:
TaskFilterByTitle-
Return a list of
Taskobjects whosetitleproperty contains the passed-in string value TaskFilterByStatus-
Return a list of
Taskobjects whosecompleteFlagproperty is set totrue(or set tofalse) TaskFilterByUser-
Return a list of
Taskobjects whoseassignedUserproperty is set to the passed-inUser.nickvalue UserFilterByNick-
Return a list of
Userobjects whosenickproperty contains the passed-in string value UserFilterByName-
Return a list of
Userobjects whosenameproperty contains the passed-in string value
The common design approach here is to make an HTTP GET request to the object’s list URL (/task/ or /user/) and pass query arguments in the URL directly. For example, to return a list of Task objects that have their completeFlag set to true, you could use the following HTTP request: GET /task/?completeFlag=true.
So, we have the standard CRUD operations (nine in our case), plus the special operations (three), and then the filter options (five). That’s a fixed set of 17 operations to define, document, and implement.
A more complete set of API Design URLs—one that includes the arguments to pass for the write operations (POST and PUT)—would look like the one in Table 1-2.
| Operation | URL | Method | Returns | Inputs |
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
A Note about URL Design
The URLs in the Task System API example are just one of a number of ways to design URLs for a web API. There are several books (Allamaraju, Masse) that devote pages to the proper way to design a URL for human use. In truth, machines don’t care about the shape of the URL—they only care that it follows the standards for valid URLs (RFC3986) and that each URL contains enough information for the service to route the request to the right place for processing. In this book, you’ll find a wide range of URL designs, none of which are meant to be the single right way to design URLs.
Documenting data-passing
By now, you’ve probably noticed that what we have done here is document a set of Remote Procedure Calls (RPCs). We’ve identified the actions using URLs and listed the arguments to pass for each of them. The arguments are listed in the table but it is worth calling them out separately, too. We’ll need to share these with API developers so that they know which data element to pass for each request.
| Agument Name | Operation(s) |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Notice that the last three arguments in the table (oldPass, newPass, and checkPass) do not belong to any TPS objects (e.g., Task or User). They only exist in order to complete the UserChangePassword operation. Usually, RPC-CRUD-style APIs restrict data-passing to arguments that belong to some defined object. But, as we’ve seen already, there are exceptions to this general rule. This is another challenge you’ll encounter when attempting to implement web APIs in the RPC-CRUD style.
Note
Some RPC-CRUD API designs will document an additional set of objects just for passing arguments. I’ll not be covering that here, but it is an option you may encounter when working with other RPC-CRUD APIs.
It is not enough to just document which data arguments are passed with each HTTP request. It is also important to document the format used to pass arguments from the client to the service when passing HTTP bodies. There is no set standard for data-passing with JSON-based APIs, but the typical option is to pass arguments as JSON dictionary objects. For example, the TaskAdd operation in Table 1-2 lists two inputs: title and completeFlag. Using a JSON dictionary to pass this data would look like this:
POST /task/ HTTP/1.1
content-type: application/json
...
{
"title" : "This is my job",
"completeFlag" : "false"
}
Even though the most common way to pass data from client to server on the WWW is using the common HTML FORM media type (application/x-www-form-urlencoded), it is limited to sending simple name–value pairs from client to server. JSON is a bit more flexible than FORM data since it is possible to pass arbitrarily nested trees of data in a single request. However, for this implementation, we’ll use the typical JSON dictionary approach.
That covers the endpoints, arguments, and format details for sending data from client to server. But there is another important interface detail missing here—the format of the responses. We’ll pick that up in the next section.
Serialized JSON objects
Another important element of the RPC-CRUD style of web API practice is to identity the format and shape of the serialized objects passed from server to client and back again. In the case of the TPS web API, Bob has decided to use simple JSON-serialized objects to pass state back and forth. Some implementations will use nested object trees to pass between parties, but BigCo’s serialized objects are rather simple for the moment.
Scanning the Returns column of Table 1-2, you’ll notice there are four different return elements defined:
-
TaskList -
Task -
UserList -
User
These are the return collections/objects that need to be explicitly defined for API developers. Lucky for us, the TPS web API has only two key objects as that will make our definition list rather short.
Tables 1-4 and 1-5 define the properties for the Task and User objects in our TPS web API.
| Property | Type | Status | Default |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Property | Type | Status | Default |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
Note
All fields are defined as "string" types. This is just to simplify the implementation of the TPS API for the book. While some APIs employ schemas or other means of “strong-typing” data passed between client and server, these add another level of complication to the implementation. We’ll talk more about this in Chapter 7. Also, the stored record layout includes dateCreated and dateUpdated fields that are not listed in our design here. These were left out of the tables for clarity.
For our TPS app, we’ll make things easy and define the TaskList and UserList return objects as simply JSON arrays of the Task and User objects respectively. Following are examples of each object:
/* TaskList */{"task":[{"id":"dr8ar791pk","title":"compost","completeFlag":false,"assignedUser":"mamund"}...moretasksappearhere...]}/* UserList */{"user":[{"nick":"lee","name":"Lee Amundsen","password":"p@ss"}...moreuserrecordsappearhere...]}
So we’ve defined the following for our TPS web API:
-
URLs and HTTP methods for each RPC endpoint
-
Arguments and format for passing data to the service
-
JSON objects returned to the clients
There are a few other implementation details that we’ll skip over here (handling errors, HTTP return codes, etc.). These would all appear in a complete documentation set for RPC-CRUD APIs. For now, we’ll make some assumptions and move on to some implementation details for creating the running TPS web API.
Implementing the TPS Web API
We need to make some changes to the existing TPS website/app in order to implement our JSON web API. We don’t need to start from scratch (although in some real-life cases that might be the way to go). For our example, we’ll just fork the existing HTML web implementation to create a new standalone codebase that we can alter and turn into a functioning JSON-based RPC-CRUD web API.
Tip
The source code for the JSON-based RPC-CRUD web API version of the TPS can be found in the associated GitHub repo. A running version of the app described in this chapter can be found online.
We have two important things to do here. First, we need to modify the TPS website to get it to stop emitting HTML and start emitting valid JSON responses. That won’t be too tough since the TPS server has some smart tech built in to make representing stored data in various media types relatively easy.
Note
We’ll dig into the tech for representing responses in Chapter 3.
The second job is to add support for all the HTTP requests documented in Table 1-2. The good news is most of those operations are already supported by the TPS website app. We just need to add a few of them (three, actually) and clean up some of the server-side code to make sure we have all the operations working properly.
So, let’s get started.
Defaulting to JSON responses
The TPS website/app emits HTML for all responses. Instead of HTML (text/html), our TPS web API will emit JSON (application/json) for all responses. Another important change we’ll make is to limit the service responses to only send the actual stored Task and User objects and properties. This will follow along with the information documented in Table 1-2 and the details in Tables 1-4 (Task Object Properties) and 1-5 (User Object Properties).
Based on that information, here is an example of the JSON output from a request to the /task/ URL:
{"task":[{"id":"137h96l7mpv","title":"Update TPS Web API","completeFlag":"true","assignedUser":"bob"},{"id":"1gg1v4x46cf","title":"Review Client API","completeFlag":"false","assignedUser":"carol"},{"id":"1hs5sl6bdv1","title":"Carry Water","completeFlag":"false","assignedUser":"mamund"}...moretaskrecordshere]}
Note that there are no links or forms in the JSON responses. This is typical for RPC-CRUD style API responses. The URLs and action details are included in the human-readable documentation for this project (in GitHub) and will be hardcoded into the client application calling this API.
Tip
The human-readable documentation for this RPC-CRUD API can be found in the GitHub repository and we’ll cover the details of creating a JSON-based RPC-CRUD client based on those docs in Chapter 2, JSON Clients.
As you would expect, the responses for calls to the /user/ endpoint look similar to those from the /task/ URL:
{"user":[{"id":"alice","nick":"alice","password":"a1!c#","name":"Alice Teddington, Sr."},{"id":"bob","nick":"bob","password":"b0b","name":"Bob Carrolton"},....moreuserrecordshere]}
So, that covers the service responses. Next, we need to make sure all the actions documented in Table 1-2 are covered in the code.
Updating the TPS web API operations
The TPS HTML web app supported edit and remove operations via the HTML POST method. While this is perfectly fine from an HTML and HTTP point of view, it runs counter to the common practice that has grown up around the JSON-based RPC-CRUD pattern. In CRUD-style APIs, Edit operations are handled by the HTTP PUT method and Remove operations are handled by the HTTP DELETE operations.
To make our TPS web API compliant, we need to add two things:
-
Support for
PUTandDELETEon/task/{id}URLs -
Support for
PUTon the/user/{nick}URLs
Since the TPS service already supports the actions of Update and Remove for Tasks (and Update for Users), the only thing we need to add to the server-side code is support for executing those actions via HTTP PUT and DELETE. A quick look at the code from our TPS server (with the functionality updated) is provided in Example 1-1.
Example 1-1. Modifying TPS Service to support PUT and DELETE for Tasks
...case'POST':if(parts[1]&&parts[1].indexOf('?')===-1){switch(parts[1].toLowerCase()){/* Web API no longer supports update and remove via POSTcase "update": updateTask(req, res, respond, parts[2]); break; case "remove": removeTask(req, res, respond, parts[2]); break; */case"completed":markCompleted(req,res,respond,parts[2]);break;case"assign":assignUser(req,res,respond,parts[2]);break;default:respond(req,res,utils.errorResponse(req,res,'Method Not Allowed',405));}}else{addTask(req,res,respond);}break;/* add support for update via PUT */case'PUT':if(parts[1]&&parts[1].indexOf('?')===-1){updateTask(req,res,respond,parts[1]);}else{respond(req,res,utils.errorResponse(req,res,'Method Not Allowed',405));}break;/* add support for remove via DELETE */case'DELETE':if(parts[1]&&parts[1].indexOf('?')===-1){removeTask(req,res,respond,parts[1]);}else{respond(req,res,utils.errorResponse(req,res,'Method Not Allowed',405));}break;...
Tip
Don’t worry if this isolated code snippet is hard to parse in your head. The complete source code for the JSON-based RPC-CRUD web API version of the TPS can be found in the associated GitHub repo.
As you can see from the preceding code snippet, the HTTP handler for Task data no longer supports the Update and Remove actions via POST (![]() ). They are now accessed via HTTP
). They are now accessed via HTTP PUT (![]() ) and
) and DELETE (![]() ). A similar change was made to support Update for
). A similar change was made to support Update for User data, too.
To be complete, the web API service should also be updated to no longer serve up the assignUser, markCompleted, and changePassword pages. These were provided by the TPS website/app to allow users to enter data via HTML standalone <form> responses. Because our web API doesn’t support <form>, we don’t need these pages anymore.
Here is the TPS web API Task handler with the assignUser and markCompleted <form> pages turned off:
....case'GET':/* Web API no longer serves up assign and completed formsif(flag===false && parts[1]==="assign" && parts[2]) {flag=true;sendAssignPage(req, res, respond, parts[2]);}if(flag===false && parts[1]==="completed" && parts[2]) {flag=true;sendCompletedPage(req, res, respond, parts[2]);}*/if(flag===false&&parts[1]&&parts[1].indexOf('?')===-1){flag=true;sendItemPage(req,res,respond,parts[1]);}if(flag===false){sendListPage(req,res,respond);}break;....
Testing the TPS web API with cURL
Even though we need a fully functioning JSON CRUD client (or test runner) to test all of the TPS web API, we can still do some basic testing using the curl command-line utility. This will confirm that we have set up the TPS web API correctly (per the API design just shown) and allow us to do some simple interactions with the running API service.
The following is a short curl session that shows running all the CRUD operations on the Task endpoint as well as the TaskMarkCompleted special operation:
// create a new task record
curl -X POST -H "content-type:application/json" -d '{"title":"testing"}'
http://localhost:8181/task/
// fetch the newly created task record
curl http://localhost:8181/task/1z4yb9wjwi1
// update the existing task record
curl -X PUT -H "content-type:application/json" -d '{"title":"testing again"}'
http://localhost:8181/task/1z4yb9wjwi1
// mark the record completed
curl -X POST -H "content-type:application/json"
http://localhost:8181/task/completed/1z4yb9wjwi1
// delete the task record
curl -X DELETE -H "content-type:application/json"
http://localhost:8181/task/1z4yb9wjwi1
Warning
To save space and stay within the page layout, some of the command lines are printed on two lines. If you are running these commands yourself, you’ll need to place each command on a single line.
To review, we’ve made all the implementation changes needed to get the TPS web API up and running:
-
Set the API responses to all emit simple JSON (
application/json) arrays -
Added support for
PUT(Update) andDELETE(Remove) forTaskobjects -
Removed support for
POST(Update) andPOST(Remove) forTaskobjects -
Removed support for
GET(assignUser) andGET(markCompleted) FORMS forTaskobjects -
Added support for
PUT(Update) forUserobjects -
Removed support for
POST(Update) forUserobjects -
Removed support for
GET(changePassword) FORMS forUserobjects
As you can see from the list, we actually did more to remove support in the web API than anything else. Remember that we also removed all the links and forms from all the web API responses. The description of what it takes to filter and modify data on the TPS service will now need to be documented in human-readable form and that will need to be coded into the JSON client application. We’ll see how that works in Chapter 2.
Observations
Now that we have a working TPS web API service up and running, it’s worth making a few observations on the experience.
- Plain JSON responses
-
A hallmark of web APIs today is to emit plain JSON responses—no more HTML, just JSON. The advantage is that supporting JSON in JavaScript-based browser clients is easier than dealing with XML or parsing HTML responses. Although we didn’t get to see it in our simple example, JSON responses can carry a large nested graph of data more efficiently than HTML, too.
- API design is all about URLs and CRUD
-
When we were designing our web API, we spent most of the time and effort crafting URLs and deciding which methods and arguments to pass for each request. We also needed to make sure the exposed URLs map the Create-Read-Update-Delete (CRUD) semantics against important JSON objects. There were a few actions that didn’t map well to CRUD (three for our use case) and we had to create special URLs for them.
- No more links and forms
-
Another common feature of web APIs is the lack of links and forms in responses. Common web browsers use the links and forms in HTML responses to render a user interface for humans to scan and activate. This works because the browser already understands links and forms in HTML. Since JSON doesn’t have things like
<a>…</a>and<form method="get">or<form method="post">, the information needed to execute actions from the UI will need to be baked into the API client code. - API servers are rather easy
-
Since most of what we did to make our TPS web app into a web API is remove features, it seems building API servers is relatively easy to do. There are certainly challenges to it—our TPS web API is pretty simple—but for the most part, we have less things to decide when creating these RPC-CRUD style APIs than when we are creating both the data responses and the connections (LINKS) and data-passing instructions (FORMS) from the standard website/app.
- Completing the API is only part of the story
-
We found out that once you have the web API up and running, you still need to test it with some kind of client. We can’t just point a web browser at the API because browsers don’t know about our CRUD and special operations. For now, we used the
curlcommand-line utility to execute HTTP-level requests against the API to make sure it was behaving as expected.
Summary
In this chapter, we started our journey toward hypermedia clients by first stepping back a bit and reviewing a kind of early history of typical web APIs—especially their roots in simple HTML-only websites/apps. We were introduced to BigCo’s Task Processing System (TPS) web app and learned that the HTML5 app worked just fine without any JavaScript code at all.
But we’re interested in API services and API clients. So the first task was to convert this simple HTML-only web app into a pure JSON web API service. And it was not too hard. We adopted the common RPC-CRUD design model by establishing a key URL for each API object (Task and User) and implementing the Create-Read-Update-Delete (CRUD) pattern against these objects and their URLs. We had to create a few other special URLs to support unique operations (using POST), and documented a set of filter routines against the web API’s collection URLs (/task/ and /user/). We then documented the JSON objects that were returned and established that all payloads sent from client to server should be formatted as JSON dictionary objects.
With the design completed, we needed to actually implement the API. We were able to fork the existing website app and spent most of our efforts removing functionality, simplifying the format (we dropped all the links and forms in the JSON responses), and cleaning up the web API code. Finally, we used the curl command-line utility to confirm that our API was functioning as expected.
This gives us a great start on our TPS API service. The next challenge is building a fully functional JSON CRUD client that understands the TPS web API documentation. Since we spent a lot of our time eliminating descriptive information in the web API responses, we’ll need to add that information to the API client instead. We’ll take on that challenge next.
References
-
The monochrome computer screen image is a photo of an IBM Portable PC from Hubert Berberich (HubiB) (Own work) [CC BY-SA 3.0], via Wikimedia Commons.
-
The Lynx browser screenshot is taken from a modern implementation of the Lynx specification. The data displayed is our own TPS web app, too.
-
Roy Fielding’s 2009 blog post “It is okay to use POST” points out that his dissertation never mentions CRUD and that it is fine to use
GETandPOSTfor web apps. -
Two books I recommend when looking for guides in URL design are RESTful Web Services Cookbook by Subbu Allamaraju (O’Reilly, 2010) and REST API Design Rulebook by Mark Masse (O’Reilly, 2011). There are quite a few more, but these are the books I find I use often.
-
Parkinson’s Law of Triviality is sometimes referred to as bikeshedding and was first described by C. Northcote Parkinson in his book Parkinson’s Law and Other Studies in Administration (Houghton Mifflin Company, 1957). When referring to the case of committees working through a busy agenda, Parkinson observed, “The time spent on any item of the agenda will be in inverse proportion to the sum [of money] involved.”
Get RESTful Web Clients now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

