Chapter 4. The C Programming Language
Low-level programming is good for the programmer’s soul.
The C programming language was created at Bell Laboratories by Ken Thompson and others between 1969–1973 as part of the early development work on Unix. C has been an integral part of Unix ever since, and Unix is itself written mostly in C (with a few parts written in assembly language where necessary). Linux, Solaris, BSD, and other modern operating systems are also written primarily in C. In this book we will use ANSI C, standardized in the mid-1980s and described in the book The C Programming Language, Second Edition, by Brian Kernighan and Dennis Ritchie (Prentice Hall).
This chapter is not intended to be a comprehensive tutorial on the C programming language; it is merely intended to provide enough detail to enable you to effectively apply the C language later, when you need to create extensions for Python. If you happen to be familiar with the original version of C (sometimes called “K&R”), you may notice that things have changed somewhat, but it shouldn’t be difficult to grasp the new features.
Installing C
The gcc compiler is a popular and widely used C compiler. Unfortunately, it doesn’t work with Windows (at least, not directly). Those working in a Linux or Solaris environment with access to gcc are ready to go with nothing else to install, and if gcc is not installed a short session with a package manager can usually solve the problem. If you will be using a Windows machine, you’ll need to do some extra work, or spend some money, to get a C compiler installed and running.
One solution is to obtain a copy of Microsoft’s Visual Studio, but I would recommend against this. It’s not that Visual Studio is a bad tool—it’s not. It is, however, so heavily integrated with the Microsoft GUI paradigm that just compiling a simple C program can involve a lot of mouse pushing and button clicking. If you’re going to start a major project developing a Windows application, that’s not such a big deal, but we really don’t need to go through all that just to write a simple Python extension. The alternative is to bypass the Visual Studio environment completely.
Although one can use the Microsoft C compiler and linker from the Windows command line, this is not an exercise for the faint of heart. An easier alternative is to install the MinGW (Minimalist GNU for Windows) compiler for Windows. It isn’t hard to install and provides a gcc experience for creating Python extensions. A detailed step-by-step description of how to install and configure MinGW can be found here:
| http://boodebr.org/main/python/build-windows-extensions |
Developing Software in C
C is a purely procedural compiled language. All functionality is encapsulated into functions, and C programs are structured such that they are collections of functions grouped into files (roughly the equivalent of Python’s modules). Each file may also include some global variables and various preprocessor directives. In a C source file global variables can be designated as static, which effectively hides them from functions outside of the current file.
A C source code file is compiled into an object file, which in turn is linked with other object files (either part of the immediate program or perhaps system library object files) to produce a final executable object. I should point out that the terms “object file,” “library object,” and “executable object” have nothing to do with object-oriented programming. These are historical terms from the days of mainframes and refrigerator-size minicomputers.
In the procedural paradigm a program’s functions are the primary focus and are distinct from the data they operate on, whereas in object-oriented programming the data and the methods unique to that data are encapsulated into an object. Figure 4-1 attempts to illustrate this graphically.
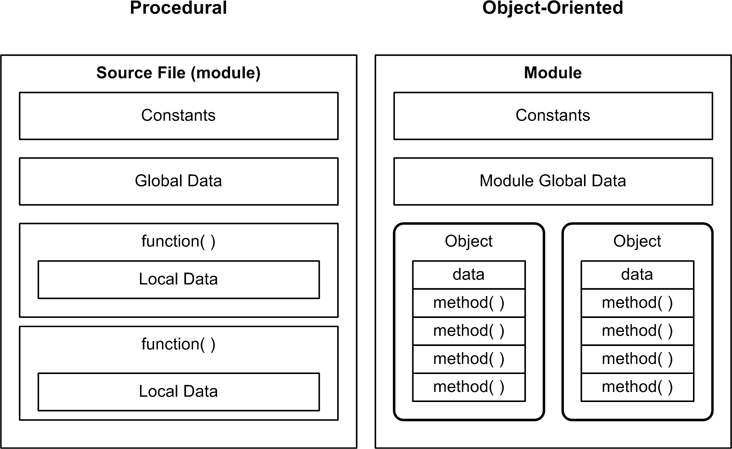
Unlike Python programs, C programs are compiled directly into a binary form (machine language) that is executed by the CPU. There is no conversion into an intermediate bytecode form, and no virtual processor to interpret the bytecode. C is thus considered to be “close to the metal,” and it is commonly used in applications where performance and compactness are primary considerations. Operating systems are a primary example. C and its OO cousin C++ are also typical first choices for creating libraries, which are collections of functions that can be reused in other programs. In fact, C is so close to the underlying hardware that it has sometimes been jokingly referred to as an assembler with fancy clothing, and most C compilers have an option to output the assembly language that corresponds to the original source code.
A Simple C Program
Most tutorials on C start off with the infamous “hello world” program example. I would prefer to start with something a bit more substantial, but still (hopefully) comprehensible. My selection for this is a simple program that generates a plot of a sine wave using nothing more than simple printable characters. If you’ve ever taken a college-level programming class, you may well have encountered something very much like this.
Every standalone C program has a starting point in the form of a
function named main(). Some C programs are not intended to be standalone
modules, but rather are libraries (collections) of functions for other modules to use. In those cases,
there is no main() function; it is
provided by some other part of the application. For a quick peek at a
small C program, consider the following example:
/* sine_print.c
Print a sideways sine wave pattern using ASCII characters
Outputs an 80-byte array of ASCII characters (otherwise
known as a string) 20 times, each time replacing elements
in the array with an asterisk ('*') character to create a
sideways plot of a sine function.
*/
#include <stdio.h> /* for I/O functions */
#include <math.h> /* for the sine function */
#include <string.h> /* for the memset function */
int main()
{
/* local variable declarations */
int i; /* loop index counter */
int offset; /* offset into output string */
char sinstr[80]; /* data array */
/* preload entire data array with spaces */
memset(sinstr,0x20, 80);
sinstr[79] = '\0'; /* append string terminator */
/* print 20 lines to cover one cycle */
for(i = 0; i < 20; i++) {
offset = 39 + (int)(39 * sin(M_PI * (float) i/10));
sinstr[offset] = '*';
printf("%s\n", sinstr);
/* print done, clear the character */
sinstr[offset] = ' ';
}
}If you have installed a C compiler (as described at the start of this chapter) or already had one available, you can compile and run this program. We will assume that it is named sine_print.c. On Linux, one would do the following:
%gcc sine_print.c -o sine_print%chmod 775 sine_print%./sine_print
The output should look like that shown in Figure 4-2.

I chose to start with this example rather than “hello world” because it illustrates several key features of the C language. We’ll go through them quickly here, and then examine them in more detail in later sections.
The first eight lines are a comment block. In C, comment blocks begin with /* and end with */. A comment block may span more than one
line.
Note
Although you may see the //
comment notation in ANSI C programs (I have, many times), it is not
part of the ANSI C standard. // is
valid comment notation for C++ programs, and most modern ANSI C/C++
compilers also honor it. However, its use in pure C programs is not
recommended.
Next, we have three #include statements. These specify external
files to be included in the program, that is, separate files that will
be read in and merged into the existing code before the compiler is
invoked. The #include statement is
not actually part of the C language itself: it is a preprocessor directive. The preprocessor recognizes a
number of reserved words; in fact, preprocessor directives could be
considered a minimal language in their own right. The preprocessor also
removes all comments from the source code before it is passed on to the
compiler.
Next comes the declaration of the function main(). In C, a function’s return type is declared before the
function name, and if it has no return type specification the int type is used by default. As in Python, the
use of arguments is optional, so here we have an empty set of
parentheses.
C uses curly brackets (the { and } characters) to mark the start and end of
blocks of code. A block may contain zero or more statements. C is a
free-format language, and so long as the syntax is correct and there is
at least one whitespace character between names (or tokens, as they are called), the compiler
doesn’t care how much additional whitespace there is. As a result, one
can create perfectly valid programs in C that are almost impossible for
a human reader to decipher. There is even an annual contest to write the
most obfuscated C program. We will endeavor to avoid writing code like
that.
The sine_print program declares three
local variables, i,
offset, and sinstr. The variables i and offset are integers, and sinstr is an array of characters (bytes).
These variables persist only for as long as
sine_print persists, and they are actual memory
locations, not objects as in Python.
Next up is a call to the standard C library function memset(). This sets all the elements of sinstr to space characters. Notice that it has
three parameters. The first is the target memory location, which in this
case is sinstr. The second is the
character value we want to write into memory starting at the location of
the first element of the array sinstr, which is an ASCII space character (its
value is 0x20 in hexadecimal notation, or 32 in decimal). Finally, there
is an integer that specifies how many elements sinstr has (that is, its size—in this case,
80). Notice that although sinstr is an array, we didn’t write it like
one. This is because of the close relationship in C between arrays and
pointers, which we’ll get to shortly. For now, you can safely assume
that using the name of an array variable without an index is equivalent
to specifying the memory address of the zeroth element in the array. So,
in a nutshell, memset() will fill 80
consecutive memory locations with the space character starting at the
address of the zeroth element of the character array sinstr.
Now notice the assignment statement on the following line. In C, a string is always terminated with a so-called string null. This is really nothing more than an 8-bit zero value. As you may recall, Python does not use string terminators, because a Python string object “knows” how big it is when it is instantiated. In C, a string is just another type of array, and without the terminator it is very possible for code to “walk off the end” of the string.
Now that the string array has been initialized, the fun can start.
The for loop modifies sinstr 20 times and prints each modification
to stdout. Within the for loop, the first statement computes where
to place an asterisk using C’s sin()
function from the math library and writes this value to the variable
offset. The index counter i is divided by 10 and used to divide up the
value of pi from the math library. The constant
value 39 in the offset calculation
statement determines where the output will start relative to the start
of the string array.
The variable offset is used as
an index into sinstr to change the
space character at that location to an asterisk. The entire string in
sinstr is then printed, including the
newly inserted asterisk. After the string has been printed, the asterisk
in the string array is replaced by a space and the process is repeated
again.
Finally, the program returns a value of zero and terminates.
Preprocessor Directives
C provides a preprocessor that supports capabilities such as file
inclusion (#include) and named
literals (#define), to name the two
most commonly used functions. The #define preprocessor directive is commonly
referred to as a macro. The preprocessor also provides a basic
conditional test and control capability (#if, #elif, #ifdef, #ifndef, #else, and #endif), and the ability to “undefine” a macro
definition (#undef). Notice that the preprocessor
directives begin with a pound (hash) symbol. These are not comments, as in
Python.
In some C implementations, the preprocessor is a separate program that is invoked as the first step in the compilation sequence, but can also be run by itself if necessary. The preprocessor scans the source file, acting on any directives encountered and stripping out comments. What comes out the other end will usually look quite different from what goes in (sometimes radically so). The output is in a form that the compiler can deal with directly: pure C language tokens, whitespace characters, and nothing more.
For most of what we’ll be doing, we won’t need the more advanced capabilities of the preprocessor. We just need to be able to include files in our code, define some constants, and then let the compiler have at it.
#include
The #include directive,
as its name implies, is used to include the contents of one file into
another. For example, it is often used to include the contents of a
header file, which, as its name implies, is
included at the start of a source file. Header files typically contain
things like function definitions for code in other modules or library
objects, and macro definitions related to those functions. The
#include directive could also be
used to include one source file into another, but this is generally
frowned upon. We will look at header files and how they are used when
we discuss the structure of a C program.
An #include statement must
appear before the contents of the file that it refers to are used, and
it is common practice (and a Very Good Idea) to place these statements
at the start of a source file. In the example program we looked at
earlier (sine_print.c), there are
three #include directives at the
top of the listing:
#include <stdio.h> /* for I/O functions */ #include <math.h> /* for the sine function */ #include <string.h> /* for the memset function */
These tell the preprocessor to include the contents of the files
stdio.h, math.h, and string.h into our program. These are part
of the standard library for C, and all three of these files contain
#define statements, function
declarations, and even more #include statements. They contain everything
necessary to make use of the standard I/O functions (printf(), memset(), and the value of
pi) and the sin() function from the basic math
facilities available in the libraries that come with the C
compiler.
#define
The #define macro directive associates a name (a
string) with a substitution string. Anywhere in the source code where
the macro name occurs, it will be replaced with the substitution
string. #define macro names can
appear anywhere where it would be valid to type in the substitution
string. Consider the following example:
#define UP 1
#define DOWN 0
if (avar < bvar) {
return DOWN;
}
else {
return UP;
}After the source has been through the preprocessor, it will look something like this:
if (avar < bvar) {
return 0;
}
else {
return 1;
}The #define macro is commonly
used to define constants that are used in various places in one or
more source modules. This is much preferable to using literal values
as “naked numbers” typed directly into the source. The primary reason
is that if a program has a constant used in calculations in multiple
places, using one macro in a common included file makes it much easier
to change and is less error-prone than hunting through the code for
each occurrence of the literal value and replacing it. Also, unless
there is a comment specifically stating that some literal value is a
special constant, it might be difficult to tell the difference between
two constants of the same value that are used for completely different
purposes. Changing the wrong literal value could lead to highly
annoying results.
#define is also sometimes
used to define a complex statement or set of statements, and supports
the ability to accept variables. This is really where it gets the
macro moniker. Here’s a simple example:
#define MAX(a, b) ((a) > (b)?(a) : (b))
The ternary conditional (?:) is a shorthand
way of testing the (a) > (b)
expression. If it evaluates to true, the value of (a) is returned; otherwise, (b) is the result. This is a somewhat risky
macro, however, because if a
happened to be of the form ++a
(which we will discuss shortly) it would get evaluated twice—once in
the comparison and once when it is returned as the result—and its
value would be incremented twice. This might not be the desired
result.
If we were to put the two #define statements from this example into
their own file, called updown.h,
it could then be included in any other C source file that needed those
definitions:
/* updown.h */ #define UP 1 #define DOWN 0
And here is how it is used:
#include "updown.h"
if (avar < bvar) {
return DOWN;
}
else {
return UP;
}When updown.h is included
into the program source, the result is the same as if the two #define statements had been written into the
code from the outset.
As a final example before we move on, here is what sine_print.c looks like if #define macros are used instead of simple
literals in the code (I’ve named this version sine_print2.c):
/* sine_print2.c
Print a sideways sine wave pattern using ASCII characters
Outputs an 80-byte array of ASCII characters (otherwise
known as a string) 20 times, each time replacing elements
in the array with an asterisk ('*') character to create a
sideways plot of a sine function.
Incorporates #define macro for constants.
*/
#include <stdio.h> /* for I/O functions */
#include <math.h> /* for the sine function */
#include <string.h> /* for the memset function */
#define MAXLINES 20
#define MAXCHARS 80
#define MAXSTR (MAXCHARS-1)
#define MIDPNT ((MAXCHARS/2)-1)
#define SCALEDIV 10
int main()
{
/* local variable declarations */
int i; /* loop index counter */
int offset; /* offset into output string */
char sinstr[MAXCHARS]; /* data array */
/* preload entire data array with spaces */
memset(sinstr, 0x20, MAXCHARS);
sinstr[MAXSTR] = '\0'; /* append string terminator */
/* print MAXLINES lines to cover one cycle */
for(i = 0; i < MAXLINES; i++) {
offset = MIDPNT + (int)(MIDPNT * sin(M_PI * (float) i/SCALEDIV));
sinstr[offset] = '*';
printf("%s\n", sinstr);
/* print done, clear the character */
sinstr[offset] = ' ';
}
}This version makes it much easier to see what happens if one
changes the maximum line length from 80 to, say, 40 characters. The
#define macros for MAXSTR and MIDPNT are computed from the value defined
by MAXCHARS, so all one needs to do
is change MAXCHARS to 40. It should be noted that when the macro
substitutions for MAXSTR and
MIDPNT occur in the code, it will
look like this when the C compiler gets it from the
preprocessor:
sinstr[(80-1)] = '\0';
and:
sinstr[((80/2)-1) + (int)( ((80/2)-1) * sin(3.14159265358979323846 \ * (float) i/10))] = '*';
The M_PI macro is supplied by
the included file math.h, and in
this case is defined as:
3.14159265358979323846
Try changing MAXCHARS to
40 or 20 and then recompile the program to see for
yourself how this works.
Standard Data Types
C has only four fundamental numeric data types. These are listed in Table 4-1.
Type | Description |
| A single byte (8 bits). Signed unless specified as unsigned. |
| An integer, which is typically the size of native integer values on the host system. Commonly found in either 16- or 32-bit sizes. Signed unless specified as unsigned. |
| A single-precision floating-point value, typically expressed in 32 bits (4 bytes). Always signed. |
| A double-precision floating-point value, typically expressed in 64 bits (8 bytes). Always signed. |
In addition, there are four modifiers that can be applied to the
basic types to specify the amount of storage that should be allocated
and the expected range. They are short, long, signed, and unsigned.
Putting it all together yields the type definitions shown in Table 4-2.
Type | Bytes | Range |
| 1 | 0 to 255 |
| 1 | –128 to 127 |
| 1 | –128 to 127 |
| 2 | –32,768 to 32,767 |
| 2 | 0 to 65,535 |
| 4 | 0 to 4,294,967,295 |
| 4 | –2,147,483,648 to 2,147,483,647 |
| 4 | –2,147,483,648 to 2,147,483,647 |
| 4 | 0 to 4,294,967,295 |
| 4 | –2,147,483,648 to 2,147,483,647 |
| 4 | approximately +/– 3.4 E +/–38 |
| 8 | approximately +/– 1.798 E +/–308 |
| 12 | (Note: 12 bytes, not 16) |
Note
These are typical range values. Actual ranges depend on machine architecture and implementation. Refer to your C compiler documentation for details.
There is no string type in C; a string is just an array of type
char with the last element containing
a zero as a terminator value. In C, strings are alterable (or mutable,
to borrow Python’s terminology) arrays just like any other array.
One will often encounter the use of short and long without the int portion of the type name. When specifying
a short or long integer type, the int
is implied, and although the compiler will (or at least, should) accept
the int keyword, it is not necessary.
Also, unless specifically stated otherwise, all integer types are
assumed to be signed.
Lastly, we should mention the void keyword. It’s not a type in the
conventional sense, but rather serves as a placeholder that indicates an
undefined type. It is typically used to indicate that a function returns
nothing (the default expected return type for a function is int), or as a placeholder for a pointer that
can refer to any valid memory location (we’ll discuss pointers
later).
User-Defined Types
C allows the programmer to define an identifier that represents an existing data type or a construct that incorporates existing data types. For example:
typedef signed short int16_t; typedef unsigned short uint16_t; typedef float float32_t; typedef double float64_t;
These are actually found in the header file /usr/include/sys/types.h.
If these are defined, one can write:
int16_t var1, var2;
and it will mean the same thing as:
short var1, var2;
typedef can also be used to
create new type definitions for things like pointers and
structures.
Operators
C provides the usual selection of arithmetic, logical, and comparison operators. It also has some rather unique unary (single-operand) operators such as pre- and post-increment, pre- and post-decrement, logical negation, and unary plus and minus (arithmetic negation).
Some operators appear more than once in the following tables to reflect their status as members of more than one class of operations.
Arithmetic operators
The arithmetic operators (see Table 4-3) in C are much like the arithmetic operators in any other language.
Operator | Description |
| Addition |
| Subtraction |
| Multiplication |
| Division |
| Modulus |
One does need to be careful, however, when performing operations on variables of different types. For example, when two integer types are used, the smaller type is “promoted” to a size equal to that of the larger type. Thus, if a short integer is added to a long, the short is promoted to a long for the operation.
Unary operators
C’s unary operators (shown in Table 4-4) perform a specific action on one, and only one, variable. They will not work on expressions, but they can appear in expressions.
Operator | Description |
| Unary plus |
| Unary minus (arithmetic negation) |
| Pre-increment |
| Post-increment |
| Pre-decrement |
| Post-decrement |
| Logical negation
( |
| Bitwise one’s
complement ( |
| Pointer dereference (see section on pointers) |
| Memory address (see section on pointers) |
These operators might need a few words of explanation. The unary plus and minus operators change the sign of a variable. Consider the following bit of code:
#include <stdio.h>
void main() {
int a, b;
a = 5;
printf("%d\n", a);
b = -a;
printf("%d\n", b);
}When this code is compiled and executed, the following output is generated:
5 -5
The increment and decrement operators increase or decrease the
value of a variable by 1. When this occurs is determined by the
location of the operators. If the ++ or --
operator appears before the variable, the increment or decrement
operation occurs before any subsequent operations using that variable.
If the ++ or -- operator appears after the variable name,
the increment or decrement occurs after the indicated operation. The
following code shows how this works:
#include <stdio.h>
void main()
{
int a = 0;
int b;
b = ++a;
printf("a: %d, b: %d\n", a, b);
a = 0;
b = a++;
printf("a: %d, b: %d\n", a, b);
}The output looks like this:
a: 1, b: 1 a: 1, b: 0
In the first case, the value of a is incremented and then assigned to
b. In the second case, the
assignment occurs before the increment (the increment is a
post-increment), so b gets a’s original starting value, not the
incremented value.
The ! and ~ operators work as one might expect. It is
common to see expressions of the form:
a = !(b > c);
which means that if b is
greater than c, the result will be
false, even though the b > c
part of the expression is true. It is logically negated. The binary
negation (~, one’s complement)
operator inverts the sense of each bit in a variable, so that a
variable with a bitwise value of:
00100010
becomes the complement of the original value:
11011101
We will discuss the * and
& operators when we get to
pointers, so we’ll put those aside for now.
Assignment and augmented assignment operators
The C language provides a number of useful assignment operators. These are shown in Table 4-5.
Operator | Description |
| Basic assignment |
| Addition and assignment |
| Subtraction and assignment |
| Multiplication and assignment |
| Division and assignment |
| Modulus and assignment |
| Assignment by bitwise left shift |
| Assignment by bitwise right shift |
| Assignment by bitwise
|
| Assignment by bitwise
|
| Assignment by bitwise
|
The assignment operator in C works by copying a value into a memory location. If we have two variables and we write:
x = y;
the value contained in the memory location called y will be copied into the memory location
called x. Note that both x and y
must have already been declared before an assignment can take place,
so that the compiler can allocate memory space for the variable ahead
of time.
As in most other modern programming languages, C’s augmented assignment operators work by performing the indicated operation using the values of the variables on either side of the operator and then assigning the result back into the lefthand variable. So, if we have an expression that looks like this:
cnt += 10;
we can expect that the value cnt will have 10 added to it and the sum
will then be assigned back to cnt.
Comparison operators
C’s comparison and relational operators (shown in Table 4-6) only work on
numeric values. They don’t work on strings, structures, or arrays,
although it is possible to compare two characters, as in ("a" < "b"). In this case the result will
be true, since the numeric ASCII value of "a" is less than the numeric value of
"b". C simply treats them as byte
values.
Operator | Description |
| Less than |
| Less than or equal to |
| Greater than |
| Greater than or equal to |
| Not equal to |
| Equal to |
Expressions that use comparison operators always return a
logical true or false. In C, false is defined as zero (0), and anything else is considered to be
true (although the value 1 is
typically given this honor). The operands may be single variables or
other expressions, which allows for some rather complex compound
expressions.
Logical operators
C provides three logical operators, shown in Table 4-7.
C’s logical operators act on the truth values of the operands. Thus, a statement such as this:
tval = !x && (y < z);
has a truth table that looks like Table 4-8.
In this case, tval will be
assigned a true value if and only if x is false and the expression (y < z) evaluates to true.
Bitwise operators
The rich set of bitwise operators found in C is a legacy of its long history as a systems-level language, and these operators are ideally suited to applications that are “close to the metal.” Table 4-9 lists C’s bitwise operators. Manipulating the bits in a hardware register is much easier to do in a low- to mid-level language like C than in a high-level language such as Python.
Operator | Description |
| Bitwise left shift |
| Bitwise right shift |
| Bitwise one’s
complement ( |
| Bitwise |
| Bitwise |
| Bitwise |
| Assignment by bitwise left shift |
| Assignment by bitwise right shift |
| Assignment by bitwise
|
| Assignment by bitwise
|
| Assignment by bitwise
|
C extends the concept of augmented assignment by including bitwise operations. The shift-assign operators shift the value of the lefthand operand in a bitwise fashion either left or right by the number of bits specified in the righthand operand, and assign the result to the lefthand operand.
If we have a variable that contains the value 1 and we shift it left by 2, the result will
be the value 4. This is shown
graphically in Figure 4-3.
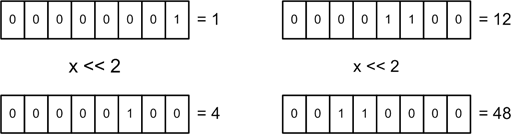
In the first case (on the left), the original value of 1 becomes 4. In the second case, the original value of
12 becomes 48. A left shift is, in effect,
multiplication by powers of 2 wherein the original value is multiplied
by 2n, where
n is the number of bit positions shifted.
Conversely, a right shift is equivalent to division. And, yes, one can
do some speedy math tricks using shifts, but only if it works out that
a power of 2 is suitable for the operation.
The AND, OR, and XOR bitwise operators
map across bit-to-bit between the operands. The AND and OR operators are used fairly heavily in
situations where one must manipulate the individual bits in a hardware
register, such as might be found in an interface circuit of some kind.
The bitwise AND is often used to
isolate a particular bit in an integer value, which may have been read
from a hardware register. The following code snippet shows how the
AND operator can be used (we’ll
assume that the variables have all been properly defined
elsewhere):
regval = ReadReg(regaddr);
if (regval > 0) {
if (regval & 0x08)
SetDevice(devnum, SET_ON);
else
SetDevice(devnum, SET_OFF);
regval &= 0xf7;
WriteReg(regaddr, regval);
}The first step is to obtain the current contents of a hardware
register and write the data into the variable regval. Next, regval is checked to see if any bits are set
(it will be > 0). If so, then the bit at position
23 (0x08) is tested by “masking” all the
other bits. With the AND operator,
if the 23 bit is 1, the result will be
nonzero (it will be 0x08, actually) and the TRUE portion of the second if statement will be executed. Otherwise,
the FALSE portion of the if will be executed. Lastly, the snippet
clears the 23 bit by applying the one’s
complement of 0x08 (which is 0xf7) and writes the value back into the
hardware register. If the bit at the 23
position in regval is already 0, it
will remain 0. This could have the effect of resetting a trigger
condition or perhaps terminating some action in the external physical
world. Figure 4-4 shows how
the snippet operates on the bits in regval.

Operator precedence
To complete our overview of operators in C, we need to consider the subject of operator precedence. Each operator in C has a specific priority, or precedence, in the order of execution when an expression is evaluated. Consider these two expressions:
2 * 4 + 12 2 * (4 + 12)
They may look similar, but they will give very different results. The first expression will yield a value of 20. The second will yield a value of 32. The reason is that the multiplication operator has a higher precedence than the addition operator, so unless the compiler is told otherwise by mean of parentheses grouping, it will perform the multiplication first.
Associativity also affects how an expression will be evaluated. In general terms, associativity defines how evaluation of an expression associates operands with operators, and in which direction, for operators of the same precedence. For example, if we have the following:
3 + 5 + 7 − 2 + 6
the addition and subtraction operators associate left to right. The result is the same as if the expression had been written as:
((((3 + 5) + 7) − 2) + 6)
Now consider this expression:
3 + 2 * 6 + 8 / 4
Multiplication and division also associate left to right, but they are of a higher precedence than addition or subtraction, so this expression could be stated as:
((3 + (2 * 6)) + (8 / 4))
If a different outcome is desired, parentheses can be used to group the operands accordingly.
In general, it is a good idea to use parentheses to make the original intent clear rather than relying on the precedence and associativity rules of a language. The result is more readable and less prone to misinterpretation.
Table 4-10 lists the operators available in C in order of precedence, from highest to lowest, along with the associativity of each.
Operator | Description | Associativity |
| Parentheses Brackets (array subscript) Member selection via object name Member selection via pointer Postfix increment/decrement | Left to right |
| Prefix increment/decrement Unary plus/minus Logical negation/bitwise complement Cast (change type) Dereference Address Determine size in bytes | Right to left |
| Multiplication/division/modulus | Left to right |
| Addition/subtraction | Left to right |
| Bitwise shift left, bitwise shift right | Left to right |
| Relational less than/less than or equal to Relational greater than/greater than or equal to | Left to right |
| Relational is equal to/is not equal to | Left to right |
| Bitwise | Right to left |
| Bitwise exclusive
| Right to left |
| Bitwise inclusive
| Right to left |
| Logical | Left to right |
| Logical | Left to right |
| Ternary conditional | Right to left |
| Assignment Addition/subtraction assignment Multiplication/division assignment Modulus/bitwise Bitwise exclusive/inclusive Bitwise left/right shift assignment | Right to left |
| Left to right |
Expressions
An expression in C makes use of one or more of the available operators to define a computational action. This might be as straightforward as a comparison, or as complex as a multivariable Boolean equation. When used within control statements (which we will examine shortly), an expression is always enclosed in parentheses. Expressions used in an assignment statement may have optional parentheses to help establish the desired order of operations to be performed. Parenthesized expressions always return a value as a side effect, which may or may not be useful.
Statements
A C program is composed of statements. A statement is executable code, such as an assignment, a function call, a control statement, or a combination of these. Statements consist of tokens (variable and function names), expressions, and possibly other statements. C is a logically rich language and allows for a great deal of flexibility in how statements are assembled by the programmer.
Assignment statements copy the value of whatever is on the right side of the assignment operator to the token on the left side. The lefthand token must be a variable (either a single variable, an element in an array, or a member of a structure), whereas the righthand operand may be any valid variable name, a constant, an expression, or a statement that returns a value. One cannot assign a value to a function or a constant, but one can assign the return value of a function or the value of a constant to a variable.
A function call statement transfers program execution to another function. It might be within the same module as the calling function, or it in another module altogether. When the external function finishes and returns, control resumes at the next statement following the call statement. It is common to see a combination of an assignment with a function call, like this:
ret_val = ext_function();
The control statements of a C program control program execution. There are various types of control statements available to perform branching, implement loops, and directly transfer control to another part of the program.
Groups of statements are referred to as statement
blocks, and are delimited using the curly brace characters
({}).
if-else statement
The if statement is used to direct control flow,
or the path of execution, through the code. The test expression will
be evaluated as either true (any nonzero value) or false (a zero). The
basic form of if statement looks
like this:
if (expression) {statement(s)}
If only a single statement is used, the curly braces are optional.
In a simple if statement,
when (expression) is true, the statement or statements
associated with the if are
executed. Because C is an unstructured language, one could also write
a simple if like this:
if (expression)statement;
or:
if (expression) {statement;statement;}
While there are situations where this might make the intent of the code more readable and concise, it should be used sparingly, if at all.
The else statement allows for
an alternative to handle the condition where (expression) evaluates to false and some alternative
action is necessary:
if (expression1) {statements(s)} else {statements(s)}
If (expression) is true, the first block of statements is
executed; otherwise, the second block of statements is
executed.
Multiple conditional tests may be grouped into a set of
alternative actions by using the else
if statement:
if (expression1) { /* block 1 */statements(s)} else if (expression2) { /* block 2 */statements(s)} else if (expression3) { /* block 3 */statements(s)} else { /* block 4 */statements(s)}
If (expression1) is true, the statements in block 1 are
executed. If expression1 is not true,
(expression2) is evaluated, and if it is true the
statements in block 2 are executed. The same applies to (expression3). If none of the expressions are true, the
statements in block 4 under the final else are executed. Note that the use of the
last else is optional.
switch statement
The switch statement is used to select an
execution path based on the value of an expression. The value of the
expression is compared to a constant and, if it matches, the statement
or statements associated with that branch are executed:
switch (expression) { caseconstant:statement; caseconstant:statement; caseconstant:statement; default:statement; }
The constant may be a char,
an int, a float, or a double, and all case values must be unique.
The optional default statement is
executed if none of the case
statements are matched.
If more than one statement is used with a case statement, the statements do not need
to be grouped into a block using curly braces, although it is
syntactically legal to do so:
switch (expression) { caseconstant:statement;statement; caseconstant: {statement;statement;statement; } }
One tricky—and often misunderstood—behavior of a switch statement is called fall-through.
Consider the following example program, c_switch.c:
/* C switch example */
#include <stdio.h>
int main(void)
{
int c;
while ((c = getchar()) != EOF) {
if (c == '.')
break;
switch(c) {
case '0':
printf("Numeral 0\n");
case '1':
printf("Numeral 1\n");
case '2':
printf("Numeral 2\n");
case '3':
printf("Numeral 3\n");
}
}
}This compiles just fine, and when a period (.) is entered the while loop is exited using a break statement as it should, but the output
looks like this:
0Numeral 0 Numeral 1 Numeral 2 Numeral 31Numeral 1 Numeral 2 Numeral 32Numeral 2 Numeral 33Numeral 3.
What is happening here is that when a case statement matches the variable c, it not only executes its statement, but
then execution “falls through” and all subsequent statements are
executed. This may not be what was intended (although there are some
cases where this behavior might be desirable). In order to prevent
fall-through, the break statement
can be used. Here is the revised version of c_switch.c with break statements:
/* C switch example */
#include <stdio.h>
int main(void)
{
int c;
while ((c = getchar()) != EOF) {
if (c == '.')
break;
switch(c) {
case '0':
printf("Numeral 0\n"); break;
case '1':
printf("Numeral 1\n"); break;
case '2':
printf("Numeral 2\n"); break;
case '3':
printf("Numeral 3\n");
}
}
}The output now looks like what we would expect:
0Numeral 01Numeral 12Numeral 23Numeral 31Numeral 13Numeral 32Numeral 2.
One should always use break
statements in a switch construct
unless there is a very good and compelling reason not to do so. The
default statement is also a good
idea. In some coding style requirements, such as those employed in the
aerospace industry, a default
statement is always required, even if it does nothing. One use for a
switch construct with a default statement is as an input verifier.
Suppose a function expects a specific set of input parameter values,
and anything else is an error that must be trapped and handled. Here’s
a simple example code snippet:
switch(inval) {
case 0:
case 1:
case 2:
case 3:
rc = OK;
break;
default:
rc = BAD_VAL;
}This will set the variable rc
(i.e., the return code) to whatever the macro OK is defined to be if the input value
(inval) is between 0 and 3,
inclusive. If it is anything else, rc is set to BAD_VAL. It is assumed that rc will be checked further down in the code
to handle the invalid input condition. Although one could have written
an equivalent bit of code using an if and comparison operators, like so:
if ((inval >= 0) && (inval <= 3)) {
rc = OK;
else
rc = BAD_VAL;the switch method also
handles noncontiguous sequences of values quite nicely without
resorting to long and complex combinations of logical and comparison
operators.
while loop
The while loop executes a
statement or block of statements so long as a test expression
evaluates to true:
while (expression) {statement(s)}
Because the test expression is evaluated before the body of the loop, it is possible that it may not execute any of its statements at all.
do-while loop
The do-while loop is similar to while, but the loop test expression is not
evaluated until the end of the loop’s statement block:
do {
statement(s)
} while (expression);The statement or statements in the body of a do-while loop will always be executed at
least once, whereas in the while
loop they might not be executed at all if the test expression
evaluates to false.
for loop
The for loop is typically used as a counting loop,
although it is not restricted to using just numeric types:
for (<initialization expression>,<test expression>,<iteration expression>) {statement(s)}
The for statement contains
three distinct components, all of which are optional. When the test
expression is omitted, the logical value is assumed to always be true.
The initialization and iteration expressions are treated as no-ops
when either or both are omitted. The semicolons in the syntax are
sufficient to indicate the omission of one or more of the
expressions.
For example, a for loop can
omit the initialization and test expressions:
int i = 0;
for (; ; i++) {
if (i > 9)
break;
}To emulate an unbounded loop, all of the for loop’s expressions can be
omitted:
int i = 0;
for (;;) {
if (++i > 9)
break;
}“Unbounded” in this case simply means that there is no implicit way for the loop to terminate. If the internal test never becomes true, the loop will execute forever.
C’s for loop is very
flexible, but it is typically found in the role of a counting loop (by
way of contrast, a for statement in
Python is designed to iterate through a range of values or data
objects). The initialization expression establishes the starting value
of a loop counter variable, the test expression controls execution of
the loop (it will execute so long as the test expression is true), and
the iteration expression is invoked each time through the loop
immediately after the test expression is evaluated. The following code
snippet illustrates this:
int i;
for (i = 0; i < 10; i++) {
/* statements go here */
};The loop starts with the value of the counter variable i set to 0. The statements in the body of the loop
are then executed and the counter variable is incremented by 1. It is
then tested and, if the result is true, the loop repeats.
break statement
The break statement is used to terminate, or break
out of, a loop (while, do, or for) or a switch construct. When it is encountered, it
will cause the surrounding loop to terminate. No further statements in
the loop’s statement block will be executed. The c_switch.c example shown earlier
demonstrated the use of break in
both a loop and a switch
context.
continue statement
The continue statement forces execution to
immediately branch back to the top of a loop. It is used only with
while, do, and for loops. No statements following the
continue
statement are executed.
goto statement
The C language provides a statement that is inherently
dangerous, potentially evil, and prone to much abuse and misuse. This
is the goto statement, which, as
you might surmise, causes program execution to abruptly jump to a
labeled location in the code. As Kernighan and Ritchie put it:
“Formally, the goto is never
necessary, and in practice it is almost always easy to write code
without it.” Sage advice. We won’t be using goto in any of the C code in this book.
Arrays and Pointers
Arrays and pointers are closely related in C; both refer to contiguous areas of memory set aside for data storage. Arrays have an inherent structure imposed by the type and the size (number of elements) specified when the array is declared. A pointer also references an area of memory that has structure and size, although how this is achieved differs from an array declaration, as we’ll see shortly. Because of this close relationship, it is possible, for example, to refer to the contents of an array using a pointer. Conversely, an array index might be thought of as a pointer into a specific memory space.
In this section, we’ll look at arrays and pointers and see how they are related. We’ll also see exactly what pointers are and how they are used.
Arrays
An array is an ordered set of data items in
a contiguous region in memory. Arrays are defined with a type when
they are declared, and all the data elements in the array must be of
that type. As we’ve already seen, a string in C is an array of
char (byte) type data items. One
can also have arrays of int,
float, and double values, as well as pointers.
In C, an array is fixed in size. Its size cannot be changed once it is defined (actually, this is not entirely true if one is using pointers, but we’ll get to that in a moment). Each element, or cell, in an array occupies the amount of memory required to hold a variable of the type of the array.
Here is a contrived example that will print each element in a string array on its own line of output:
#include <stdio.h>
int i;
char cval = ' ';
int main(void)
{
char str[16] = "A test string\0";
for (i = 0; cval != '\0'; i++) {
cval = str[i];
if (cval != '\0') printf("%c\n", cval);
}
}Notice that the string in str
has a char zero value at the end.
Without this, the for loop would
run off the end of the array and into some other part of memory. Also
notice that if cval contains the
null character (\0), it is not
printed.
Lastly, there is the array of pointers, which are treated as unsigned integer values of a size corresponding to the native address size of the underlying machine (typically 32 bits).
When an array is accessed using an index, the actual position in the array’s memory space is based on the size of the data type of the array, as shown in Figure 4-5.
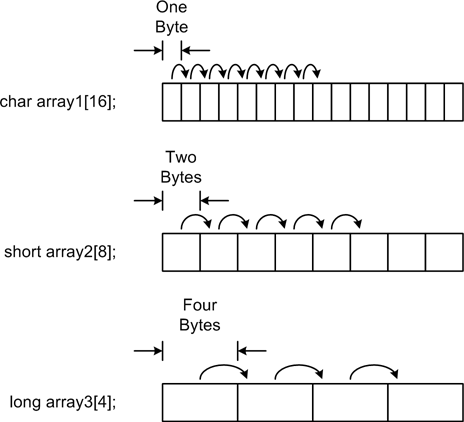
When the index of array1 is
incremented, it advances one byte (char). When the index of array2 is incremented, it advances by two
bytes. For array3, the index
advances by four bytes. Note that in C array indexing is
zero-based.
Pointers
A pointer is a variable that contains a memory address. This address might be that of another variable, or it could point to a contiguous region of memory. It might also be something like the address of a control register in an I/O device of some type. Pointers are a powerful concept, and they make some classes of problems much more tractable than would otherwise be possible. For this reason, C has sometimes been called “the language of pointers.” Understanding what a pointer is and how to use it effectively is key to writing efficient and powerful programs in C. Occasionally one hears criticism leveled at C because of pointers, and while it is true that a stray pointer can cause serious problems, it is also true that if pointers are used carefully and with some discipline, the result is as safe and robust as any code written in a language that lacks the concept of a pointer.
Note
For a real-life example of how pointers in C can be used to manage memory for image data processing on a spacecraft, see Chapter 3 of the book Beautiful Data, edited by Jeff Hammerbacher and Toby Segaran (O’Reilly).
To define a pointer, we use the * unary operator:
int *p;
This statement defines a pointer named p of type int, and it can be used to point to an
integer data location. To assign an address to it, we can use the
& unary operator, like
so:
int x = 5; int y; int *p; p = &x;
The pointer variable now contains the address of the variable
x, and we can access the contents
of x using p:
y = *p;
This will assign the value of x to the variable y. When the * operator is used in this fashion, it is
called dereferencing, or
indirection.
Pointers can be passed as parameters to functions. This allows a C function to manipulate data in some location outside of itself, or return more than just a single value. Here’s a common swap function:
void swap (int *x, int *y)
{
int tmp;
tmp = *y;
*y = *x;
*x = tmp;
}The parameters x and y are pointers provided by a calling
function, like so:
int a = 10 int b = 20; swap(&a, &b);
Note that when swap() is
called, the & address operator
is used to pass the addresses of the two variables a and b.
When swap() returns, a will contain 20 and b
will contain 10.
We stated earlier that arrays and pointers are related, and this
is a good time to explore that relationship a bit further. In C, the
first element in an array is the base address of the array’s memory
space. We can assign the base address of an array to a pointer using
the & operator, like so:
int anarray[10]; int *p; p = &anarray[0];
Since both anarray and
p are defined as int types, these two statements are
equivalent:
anarray[5]; *(p+5);
Both refer to the value stored at index position 5 in the
anarray memory space. With the
pointer form, the address it contains is incremented by five, not the
value it is pointing to. If we had written *p+5, the array element at anarray[0] would have had 5 added to it
instead. One can also assign the base address of an array to a
pointer, like this:
p = anarray
This form implies &anarray[0] and is usually how an array
base address is assigned to a pointer. The &anarray[0] form is not necessary;
unless there is a specific need to reference the address of a
particular array element other than the zeroth element, one would just
use the array name.
Pointers can be used to point to things other than simple variables and arrays. A pointer can refer to a structure (discussed in the next section), or it can point to a function. Pointers in C take a little getting used to if one has never dealt with them before, but it is worth the effort to learn them as they allow for compact and efficient expressions that would otherwise be difficult, or even impossible, to achieve.
Structures
A structure in C is a collection of variables of different types. A structure has a unique name, and structures may include substructures.
Figure 4-6 shows a graphical representation of structure syntax.

Here is a definition for a simple structure that contains three variables that hold the result from a single input measurement of some sort:
struct measdata {
float meas_vpp;
float meas_f;
long curr_time;
};This, by itself, isn’t particularly interesting, but if we had an array of these structures we would have a set of measurements:
struct measdata measurements [100];
Note that the structure definition does not allocate storage space—it is just a definition. In other words, it’s a new programmer-defined type. We can also skip the extra step of declaring a variable of the structure type by appending one or more variable names to the structure definition:
struct measdata {
float meas_vpp;
float meas_f;
long curr_time;
} measurements[100], single_meas;The so-called “dot notation” is used to refer to a structure
member. If we wanted the value of meas_vpp from the
47th measurement, we would use:
vpp_value = measurements[46].meas_vpp;
Here is a more fully realized example that will obtain up to 100 measurements from an input source:
#define MAXMEAS 100
struct measdata measurements [MAXMEAS];
int stop_meas = 0;
int i = 0;
while (!stop_meas) {
measurements[i].meas_vpp = GetMeas(VPP); /* VPP defined elsewhere */
measurements[i].meas_f = GetMeas(FREQ); /* FREQ defined elsewhere */
measurements[i].meas_time = (long) time(); /* use standard library function */
i++;
if (i >= MAXMEAS) {
stop_meas = 1;
}
/* maybe put some code here to check for an external stop condition */
}We can use the typedef keyword
(discussed in the section User-Defined Types) to
create a new structure type:
typedef struct dpoint {
int unit_id;
int channel;
float input_v;
} datapoint;When used with typedef, the
structure name is optional. This form works just as well:
typedef struct {
int unit_id;
int channel;
float input_v;
} datapoint;The new type may then be used to create new variables:
datapoint input_data;
Before moving on, we need to look at pointers to structures and how the contents of a structure are accessed via a pointer. The follow example program shows how one can create an array of pointers to structures, acquire memory for the structure data, and then reference the contents of the structures:
#include <stdio.h>
#include <stdlib.h>
typedef struct {
int unit_id;
int channel;
float input_v;
} datapoint;
int i;
datapoint *dpoint[10];
int main(void)
{
for (i = 0; i < 10; i++) {
dpoint[i] = (datapoint *) malloc(sizeof(datapoint));
dpoint[i]->unit_id = i;
dpoint[i]->channel = i + 1;
dpoint[i]->input_v = i + 4.5;
}
for (i = 0; i < 10; i++) {
printf("%d, %d: %f\n", dpoint[i]->unit_id,
dpoint[i]->channel,
dpoint[i]->input_v);
}
for (i = 9; i > 0; i--) {
free(dpoint[i]);
}
}When we execute this code, the following output is generated:
0, 1: 4.500000 1, 2: 5.500000 2, 3: 6.500000 3, 4: 7.500000 4, 5: 8.500000 5, 6: 9.500000 6, 7: 10.500000 7, 8: 11.500000 8, 9: 12.500000 9, 10: 13.500000
There are some new things here, so now would be a good time to
look at them. First, notice that an array of pointers of type datapoint is created and called dpoint. When a pointer or array of pointers is
defined in this fashion, the pointer values are not yet valid—they point to nothing because no
memory addresses have been assigned.
In the main() function, the
first for loop handles the chore of
assigning a datapoint-sized chunk of
memory to each of the elements in the array of pointers by calling the
standard library function malloc().
The malloc() function requests a
block of memory of a specified size (in this case, large enough to hold
an instance of a datapoint structure)
from the operating system. The first for loop also assigns values to locations in
that memory allocation that map to the structure defined in the datapoint type.
Since dpoint is of type
datapoint, the memory block provided
by malloc will be treated just like a
datapoint structure. Figure 4-7 shows this
graphically.
To access individual elements in each structure, the so-called arrow notation is used. This notation is used in C to relate pointers to structures with the defined data elements within the structure type.
The second for loop reads out
the data in structures and prints it, while the last for loop works backward through the array of
pointers and frees the memory for each entry.
Functions
In C, all executable statements are contained within functions
(preprocessor directives are not executable parts of the compiled code).
C does not support the use of immediate execution statements such as
those found in Python modules. Also, every executable C program must
have a function named main(). This is
the primary entry point when the program is started. Utility, support,
and library modules that are intended to be compiled and then “linked”
with other modules (more on this in a bit) do not have a main() function.
Function syntax
The basic syntax of a C function looks like this:
[type]name(parameters) {statements... }
The optional [type] qualifier
specifies the return type of the function, and if it is not present
the compiler typically assumes that the function will return an
integer (some compilers, such as gcc, may
generate a warning message about it). The function name is composed of
alphanumeric characters; how they are utilized is largely a stylistic
issue. The function name is followed by zero or more parameters
enclosed in parentheses. Parameters also have type qualifiers, and may
be either values or pointers. On the next line, there is a left curly
brace ({), followed by zero or more
statements, and then a final closing right curly brace (}).
Functions cannot normally be nested in standard ANSI C, although some compilers do allow functions to be nested as a nonstandard extension (hint: don’t do it—you will most likely hate yourself for it later). Each function is treated as a single unique entity with its own local scope.
Function prototypes
A function prototype defines a function to
the C compiler in a format that can be used to resolve forward and
external references. Because C requires that things like variables,
typedefs, and functions be defined before they are
used, it is convenient to place the prototypes for the functions in a
module at the top of the module, or in an external file. This allows
the functions in the module itself to appear in any order. The
alternative is to arrange the functions such that they appear and are
defined before they are called. This might be acceptable for a small
module, but it can quickly become a major headache with a large module
containing many functions.
A function prototype is just the function definition statement
terminated with a semicolon (;). A
C function prototype defines a reference to an as-yet-undefined
function within the current source file, or an external function
within a separate object module. Prototypes are used to create
placeholders in the compiled code that will be filled in later by a
tool called a linker. For example:
void bitstring(char *str, long dval);
The function prototype specifies the function’s return type
(void in this case), its name, and
the number and types of its parameters. The use of parameter names is
optional, which means we could just as easily have written the
following and it would work just fine:
void bitstring(char *, long);
The Standard Library
An ANSI-compliant C compiler comes with a number of header files and library modules that provide support for math operations, string processing, memory management, and I/O operations, among many others. Table 4-11 gives an abbreviated listing of what is available. For more information, refer to the documentation supplied with your particular C compiler.
Filename | Description |
assert.h | Defines the |
ctype.h | Declares functions for
testing and classifying characters, such as |
errno.h | Captures error codes generated by other functions in the standard library. |
float.h | Defines macro constants for use with floating-point math operations. |
limits.h | Defines macro constants that are implementation-specific values for things such as the number of bits in a byte and the minimum and maximum values for integer types. |
locale.h | Defines things like local
currency representation and decimal point formatting. Declares
the |
math.h | Declares mathematical
functions such as |
setjmp.h | Declares the macro
|
signal.h | Provides a means to
generate and handle various system-level signals, such as
|
stdarg.h | Defines the |
stddef.h | Defines several useful types and macros that are used in other standard library headers. |
stdio.h | Provides input and output
functionality, including |
stdlib.h | Contains declarations for
a variety of utility functions, including |
string.h | Defines
string-manipulation functions such as |
time.h | Provides several
functions useful for reading and converting the current time and
date. Some behavior of the functions declared here is defined by
the |
The most commonly used standard library components are math.h, stdio.h, stdlib.h, and string.h. I would advise you to take a look at these components so you can get an idea of what is available.
Building C Programs
A nontrivial C program is usually a collection of files. Some of these may contain source code directly related to the program, while some might be local files containing function prototypes and macro definitions. Still other files may reside in a common library directory. When the program is compiled it is all pulled into the compiler, converted into object files, and then linked into a complete executable program. Figure 4-8 shows the steps involved in compiling C source code into an executable program file.
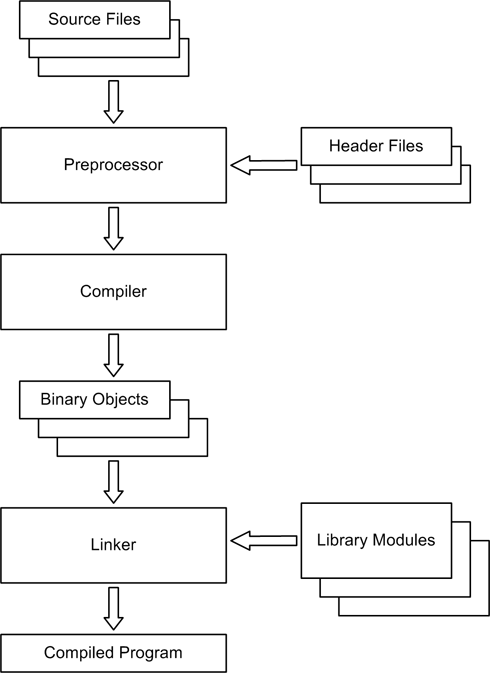
Header files
In C, one will typically see two types of file extensions: .c and .h. The .h extension is used to denote a header file, so called because one typically includes all necessary .h files at the start of a module, before any of the actual code.
Header files are included in their entirety via the #include directive. They typically contain
function prototypes, macro definitions, and typedef statements, and a header file
can—and often does—include other header files. However, it is
considered both bad form and bad practice to place executable function
code in a header file. Since it is rather trivial to build
execution-safe linkable object files in C, there really is no reason
to do this.
Object files
The C compiler does not itself generate executable output. It generates what are referred to as object files, which is an ancient term from the land of mainframes that refers to the notion of a binary object consisting of machine-code instructions. Actually, however, an object file is an intermediate product. In order to execute, it still needs some additional code, and this is provided by the linker.
If an object file references other binary objects outside of itself, the compiler inserts a placeholder and creates a list of these in the object file. The linker then reads this data in order to resolve the external references. Some C compilers (most notably Microsoft C) also automatically incorporate a runtime object to allow a program to access Windows system functionality.
Libraries
Library files are collections of binary objects that may be incorporated into other programs. Binary library files have specific formats, and there really isn’t a universal format. Figure 4-9 shows a generic example of the internal format of a library file.
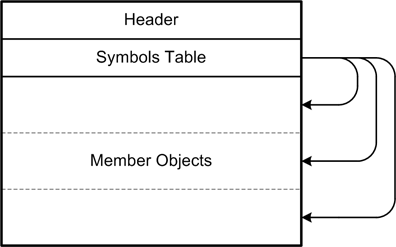
The header identifies the type of library file, which may be either static or dynamic. The symbol table contains a list of the object names in the file along with address offset values that point to each object. Lastly, there are the binary objects themselves.
Linking
The linker is a standalone utility that links program binary objects to external library modules. It uses the external reference placeholders in the program binary object to determine what is needed and where the address reference for the external object should be inserted. Figure 4-10 shows how the linking works.
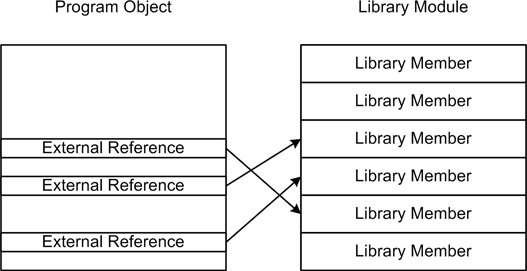
The linker is typically language-independent. So, for example,
one could link a binary object originally created using FORTRAN with
an object created using C, provided that the compilers for both
objects create binary objects that adhere to the same format as that
expected by the linker. Figure 4-11 shows a
generic linked executable with one program binary object, two library
modules, and a runtime object to interface with the underlying
operating system. Not every C implementation uses or requires a
runtime object module, and in some implementations the functionality
to support things like the printf()
function is included automatically, even if it isn’t used in the
program.
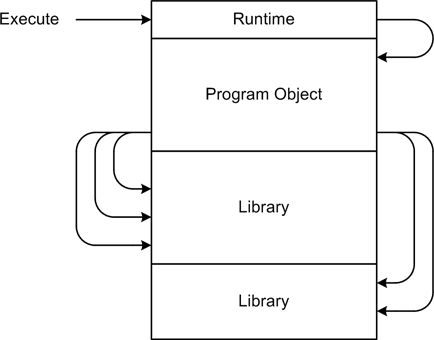
Program execution always begins with the main() function, and this is where the
default runtime code will point the CPU when the program is
loaded.
make
Lastly, we should mention the make utility. make is not part of the C compiler; it is a separate program, although it might be included with a C compiler distribution. make is a tool for maintaining a set of source files based on the use of rules and actions. The rules specify actions to take if a file is missing or has been modified. When used to help manage large C programs with many source and header files, make will invoke either the compiler or the linker (or both) as necessary, to keep all binary objects, libraries, and executable files up-to-date. Almost all versions of make incorporate their own unique “little language” that allows for macro definitions, name substitutions, generic and specific rule forms, and the ability to access other programs in the host system. We won’t delve into make in this book, but I would encourage you to read about make on the Web or in the documentation supplied with your operating system or C compiler.
C Language Wrap-Up
C is a procedural language originally used for system-level programming. It has since evolved into a general-purpose language that occupies a niche just above assembly language and well below high-level languages such as Python, Java, or Lisp. Because of C’s low-level nature, it is well suited to tasks that involve direct interaction with system hardware and the underlying operating system. These capabilities are a double-edged blade, however, and it’s easy to write C code that can do very unpleasant things to the host system. Care and discipline are required to write solid, safe, and reliable C code.
C Development Tools
As with Python, you will need a text editor or IDE of some sort for entering and editing C source code.
Whereas Python handles the chores involved with keeping the various packages and modules up-to-date dynamically at runtime and provides capabilities like introspection as built-in functionality, a C program must be compiled and linked from its component parts as a separate step in the development process.
Also, C does not support the ability to dynamically examine a running program, nor does it output messages stating what modules are being loaded (unless the programmer explicitly writes this functionality into the code). The end product for a C program is a binary executable object, so debugging requires a specialized tool that is capable of reading the various headers and symbol tables found in binary objects and matching these to the original source code. If you want visibility into the compiled code, it must be compiled with debugging enabled. This generates a larger object file because it includes various symbol tables and other data for a debugger to use.
For a list of some of the editors that are available, see Chapter 3. As for IDE tools, the Eclipse IDE offers a plug-in for C as well as one for Python, and of course Microsoft’s Visual Studio supports C and C++ right out of the box.
For C on Linux- and Unix-like systems, the classic GNU debugger, gdb, is supplied with most gcc distributions. If your system has gcc, the odds are very good that gdb is also present. On a Windows platform with either Cygwin or MinGW installed, gdb should also be available. Microsoft’s Visual Studio has an excellent symbolic debugger with a GUI interface. For Linux platforms, the DDD debugger is an excellent tool that provides a GUI “wrapper” for the gdb debugger used with gcc. It also supports several other C debuggers on Unix systems.
Summary
C is a fascinating language, so low-level that it removes almost all of the constraints on the programmer by opening up the internals of the computer system to examination and manipulation. At the same time, it fits comfortably in the role of a mid-level procedural language. We have only touched on some of the capabilities of the language, but we’ve still managed to cover quite a bit. With what you’ve seen here, you should be able to write your own extensions to the Python language to give it new functionality and new interfaces into the real world.
Suggested Reading
C is now almost 40 years old, and mountains of books, papers, essays, and presentations have accumulated over the years. The following is just a minute sample of what is available:
- C Programming Language, 2nd ed. Brian W. Kernighan and Dennis M. Ritchie, Prentice Hall, 1988.
Written and reviewed by the people at Bell Labs who invented C, this is considered to be the original definitive reference for the C language. It has been updated since it was first published and now incorporates the ANSI standard version of the language. Short, to the point, and easy to follow, this little book made an indelible impact on a generation (or two) of C programmers and software engineers. A must-have for anyone working with C.
- The Standard C Library. P. J. Plauger, Prentice Hall, 1991.
A detailed and handy resource the covers the standard C library components. This is definitely a reference work, and it’s a good thing to have on the bookshelf.
- Practical C Programming, 3rd ed. Steve Oualline, O’Reilly Media, 1997.
A straightforward, no-nonsense approach to the C language in particular, and software engineering best practices in general. Examples help to illustrate the types of pitfalls commonly encountered in C programming, and there are numerous insights into the whys and wherefores of writing code in C.
As one might expect, the Internet is brimming with websites devoted to the C language. Entering the search phrase “C programming language” into Google returns something on the order of 15 million results. Here are a few highlights:
- http://cm.bell-labs.com/cm/cs/who/dmr/chist.html
An interesting account of the early history and development of the C language by Dennis Ritchie that outlines some of the thinking that went into the language as it came into existence in the early 1970s.
- http://cprogramminglanguage.net
Contains lots of brief but useful introductory material neatly organized like chapters in a book.
- http://www.gnu.org/s/libc/manual/html_node/index.html
Online documentation for the libraries supplied with the GNU gcc compiler suite. Also includes a very useful “concept index” that groups related subjects by specific topic.
- http://en.wikipedia.org/wiki/C_(programming_language)
Wikipedia has a large entry on the C language, along with many links to other sources of information.
- http://www.acm.uiuc.edu/webmonkeys/book/c_guide/
The student chapter of the ACM at UIUC (University of Illinois at Urbana/Champaign, home of the NCSA) has an online version of The C Library Reference Guide by Eric Huss available, with a comprehensive up-front index into the various pages.
- http://citeseerx.ist.psu.edu
An incredibly useful site chock-full of research papers and technical publications. Although almost none of the documents are at the tutorial level, there is still a lot of fascinating and useful material to be found here.
Get Real World Instrumentation with Python now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

