Chapter 4. Events-First Domain-Driven Design
The term Events-First Domain-Driven Design was coined by Russ Miles, and is the name for set of design principles that has emerged in our industry over the last few years and has proven to be very useful in building distributed systems at scale. These principles help us to shift the focus from the nouns (the domain objects) to the verbs (the events) in the domain. A shift of focus gives us a greater starting point for understanding the essence of the domain from a data flow and communications perspective, and puts us on the path toward a scalable event-driven design.
Focus on What Happens: The Events
Here you go, Larry. You see what happens? You see what happens, Larry?!
Walter Sobchak, Big Lebowski
Object-Oriented Programming (OOP) and later Domain-Driven Design (DDD) taught us that we should begin our design sessions focusing on the things—the nouns—in the domain, as a way of finding the Domain Objects, and then work from there. It turns out that this approach has a major flaw: it forces us to focus on structure too early.
Instead, we should turn our attention to the things that happen—the flow of events—in our domain. This forces us to understand how change propagates in the system—things like communication patterns, workflow, figuring out who is talking to whom, who is responsible for what data, and so on. We need to model the business domain from a data dependency and communication perspective.
As Greg Young, who coined Command Query Responsibility Segregation (CQRS), says:
When you start modeling events, it forces you to think about the behavior of the system, as opposed to thinking about structure inside the system.
Modeling events forces you to have a temporal focus on what’s going on in the system. Time becomes a crucial factor of the system.
Modeling events and their causal relationships helps us to get a good grip on time itself, something that is extremely valuable when designing distributed systems.
Events Represent Facts
To condense fact from the vapor of nuance.
Neal Stephenson, Snow Crash
Events represent facts about the domain and should be part of the Ubiquitous Language of the domain. They should be modelled as Domain Events and help us define the Bounded Contexts,1 forming the boundaries for our service.
As Figure 4-1 illustrates, a bounded context is like a bulkhead: it prevents unnecessary complexity from leaking outside the contextual boundary, while allowing you to use a single and coherent domain model and domain language within.
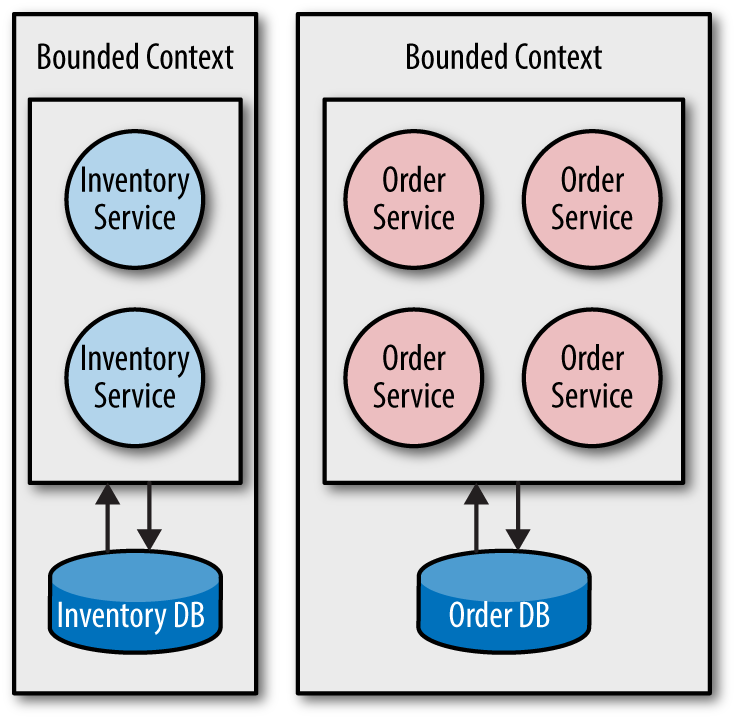
Figure 4-1. Let the bounded context define the service boundary
Commands represent an intent to perform some sort of action. These actions are often side-effecting, meaning they are meant to cause an effect on the receiving side, causing it to change its internal state, start processing a task, or send more commands.
A fact represents something that has happened in the past. It’s defined by Merriam-Webster as follows:
Something that truly exists or happens: something that has actual existence, a true piece of information.
Facts are immutable. They can’t be changed or be retracted. We can’t change the past, even if we sometimes wish that we could.
Knowledge is cumulative. This occurs either by receiving new facts, or by deriving new facts from existing facts. Invalidation of existing knowledge is done by adding new facts to the system that refute existing facts. Facts are not deleted, only made irrelevant for current knowledge.
Elementary, My Dear Watson
Just like Sherlock Holmes used to ask his assistant—Dr. Watson—when arriving to a new crime scene, ask yourself: “What are the facts?” Mine the facts.
Try to understand which facts are causally related and which are not. It’s the path toward understanding the domain, and later the system itself.
A centralized approach to model causality of facts is event logging (discussed in detail shortly), whereas a decentralized approach is to rely on vector clocks or CRDTs.
Using Event Storming
When you come out of the storm, you won’t be the same person who walked in.
Haruki Murakami, Kafka on the Shore
A technique called event storming2 can help us to mine the facts, understand how data flows, and its dependencies, all by distilling the essence of the domain through events and commands.
It’s a design process in which you bring all of the stakeholders—the domain experts and the programmers—into a single room, where they brainstorm using Post-it notes, trying to find the domain language for the events and commands, exploring how they are causally related and the reactions they cause.
The process works something like this:
Explore the domain from the perspective of what happens in the system. This will help you find the events and understand how they are causally related.
Explore what triggers the events. They are often created as a consequence of executing the intent to perform a function, represented as a command. Here, among other attributes, we find user interactions, requests from other services, and external systems.
Explore where the commands end up. They are usually received by an aggregate (discussed below) that can choose to execute the side-effect and, if so, create an event representing the new fact introduced in the system.
Now we have solid process for distilling the domain, finding the commands and events, and understanding how data flows through the system. Let’s now turn our attention to the aggregate, where the events end up—our source of truth.
Think in Terms of Consistency Boundaries
One of the biggest challenges in the transition to Service-Oriented Architectures is getting programmers to understand they have no choice but to understand both the “then” of data that has arrived from partner services, via the outside, and the “now” inside of the service itself.
Pat Helland
I’ve found it useful to think and design in terms of consistency boundaries3 for the services:
Resist the urge to begin with thinking about the behavior of a service.
Begin with the data—the facts—and think about how it is coupled and what dependencies it has.
Identify and model the integrity constraints and what needs to be guaranteed, from a domain- and business-specific view. Interviewing domain experts and stakeholders is essential in this process.
Begin with zero guarantees, for the smallest dataset possible. Then, add in the weakest level of guarantee that solves your problem while trying to keep the size of the dataset to a minimum.
Let the Single Responsibility Principle (discussed in “Single Responsibility”) be a guiding principle.
The goal is to try to minimize the dataset that needs to be strongly consistent. After you have defined the essential dataset for the service, then address the behavior and the protocols for exposing data through interacting with other services and systems—defining our unit of consistency.
Aggregates—Units of Consistency
Consistency is the true foundation of trust.
Roy T. Bennett
The consistency boundary defines not only a unit of consistency, but a unit of failure. A unit that always fails atomically is upgraded atomically and relocated atomically.
If you are migrating from an existing monolith with a single database schema, you need to be prepared to apply denormalization techniques and break it up into multiple schemas.
Each unit of consistency should be designed as an aggregate.4 An aggregate consists of one or many entities, with one of them serving as the aggregate root. The only way to reference the aggregate is through the aggregate root, which maintains the integrity and consistency of the aggregate as a whole.
It’s important to always reference other aggregates by identity, using their primary key, and never through direct references to the instance itself. This maintains isolation and helps to minimize memory consumption by avoiding eager loading—allowing aggregates to be rehydrated on demand, as needed. Further, it allows for location transparency, something that we discuss in detail momentarily.
Aggregates that don’t reference one another directly can be repartitioned and moved around in the cluster for almost infinite scalability—as outlined by Pat Helland in his influential paper “Life Beyond Distributed Transactions”.5
Outside the aggregate’s consistency boundary, we have no choice but to rely on eventual consistency. In his book Implementing Domain-Driven Design (Addison-Wesley), Vaughn Vernon suggests a rule of thumb in how to think about responsibility with respect to data consistency. You should ask yourself the question: “Whose job is it to ensure data consistency?” If the answer is that it’s the service executing the business logic, confirm that it can be done within a single aggregate, to ensure strong consistency. If it is someone else’s (user’s, service’s or system’s) responsibility, make it eventually consistent.
Suppose that we need to understand how an order management system works. After a successful event storming session, we might end up with the following (drastically simplified) design:
Commands: CreateOrder, SubmitPayment, ReserveProducts, ShipProducts
Events: OrderCreated, ProductsReserved, PaymentApproved, PaymentDeclined, ProductsShipped
Aggregates: Orders, Payments, Inventory
Figure 4-2 presents the flow of commands between a client and the services/aggregates (an open arrow indicates that the command or event was sent asynchronously).
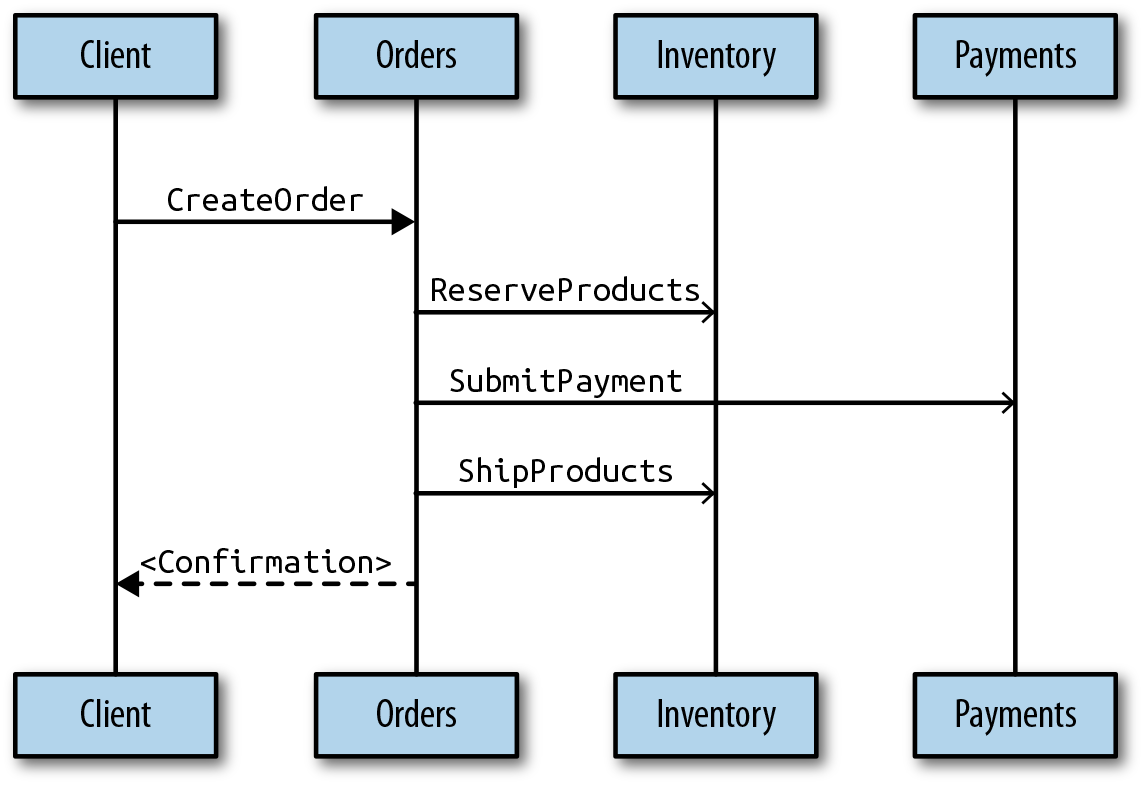
Figure 4-2. The flow of commands in the order management sample use case
If we add the events to the picture, it looks something like the flow of commands shown in Figure 4-3.
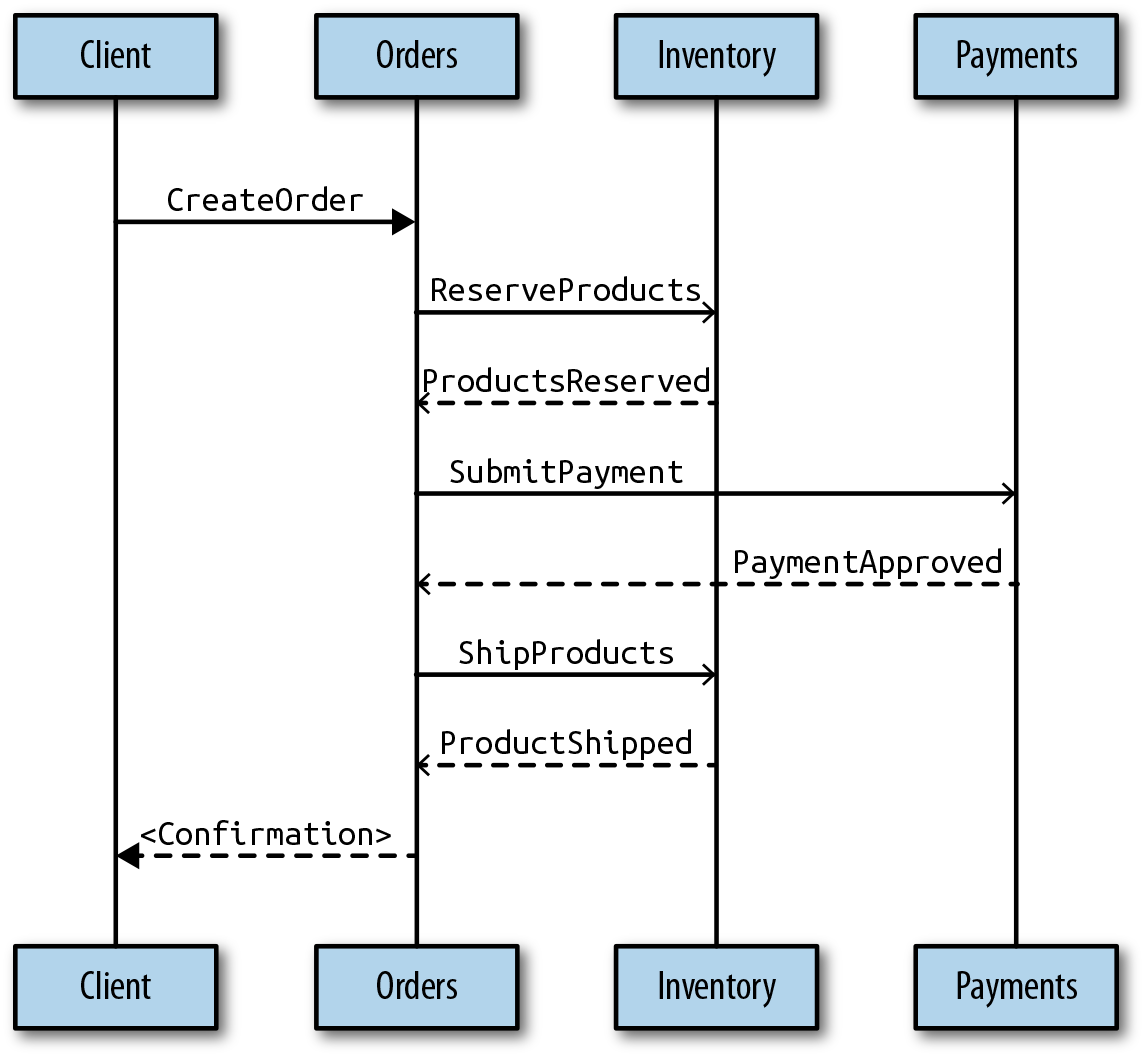
Figure 4-3. The flow of commands and events in the order management sample use case
Please note that this is only the conceptual flow of the events, how they flow between the services. An actual implementation will use subscriptions on the aggregate’s event stream to coordinate workflow between multiple services (something we will discuss in depth later on in this report).
Contain Mutable State—Publish Facts
The assignment statement is the von Neumann bottleneck of programming languages and keeps us thinking in word-at-a-time terms in much the same way the computer’s bottleneck does.
John Backus (Turing Award lecture, 1977)
After this lengthy discussion about events and immutable facts you might be wondering if mutable state deserves a place at the table at all.
It’s a fact that mutable state, often in the form of variables, can be problematic. One problem is that the assignment statement—as discussed by John Backus in his Turing Award lecture—is a destructive operation, overwriting whatever data that was there before, and therefore resetting time, and resetting all history, over and over again.
The essence of the problem is that—as Rich Hickey, the inventor of the Clojure programming language, has discussed frequently—most object-oriented computer languages (like Java, C++, and C#) treat the concepts of value and identity as the same thing. This means that an identity can’t be allowed to evolve without changing the value it currently represents.
Functional languages (such as Scala, Haskell, and OCaml), which rely on pure functions working with immutable data (values), address these problems and give us a solid foundation for reasoning about programs, a model in which we can rely on stable values that can’t change while we are observing them.
So, is all mutable state evil? I don’t think so. It’s a convenience that has its place. But it needs to be contained, meaning mutable states should be used only for local computations, within the safe haven that the service instance represents, completely unobservable by the rest of the world. When you are done with the local processing and are ready to tell the world about your results, you then create an immutable fact representing the result and publish it to the world.
In this model, others can rely on stable values for their reasoning, whereas you can still benefit from the advantages of mutability (simplicity, algorithmic efficiency, etc.).
Manage Protocol Evolution
Be conservative in what you do, be liberal in what you accept from others.
Jon Postel
Individual microservices are only independent and decoupled if they can evolve independently. This requires protocols to be resilient to and permissive of change—including events and commands, persistently stored data, as well as the exchange of ephemeral information.6 The interoperability of different versions is crucial to enable the long-term management of complex service landscapes.
Postel’s Law,7 also known as the Robustness Principle, states that you should “be conservative in what you do, be liberal in what you accept from others,” and is a good guiding principle in API design and evolution for collaborative services.8
Challenges include versioning of the protocol and data—the events and commands—and how to handle upgrades and downgrades of the protocol and data. This is a nontrivial problem that includes the following:
Picking extensible codecs for serialization
Verifying that incoming commands are valid
Maintaining a protocol and data translation layer that might need to upgrade or downgrade events or commands to the current version9
Sometimes even versioning the service itself10
These functions are best performed by an Anti-Corruption Layer, and can be added to the service itself or done in an API Gateway. The Anti-Corruption Layer can help make the bounded context robust in the face of changes made to another bounded context, while allowing them and their protocols to evolve independently.
1 For an in-depth discussion on how to design and use bounded contexts, read Vaughn Vernon’s book Implementing Domain-Driven Design (Addison-Wesley).
2 An in-depth discussion on event storming is beyond the scope for this book, but a good starting point is Alberto Brandolini’s upcoming book Event Storming.
3 Pat Helland’s paper, “Data on the Outside versus Data on the Inside”, talks about guidelines for designing consistency boundaries. It is essential reading for anyone building microservices-based systems.
4 For a good discussion on how to design with aggregates, see Vaughn Vernon’s “Effective Aggregate Design”.
5 You can find a good summary of the design principles for almost-infinite scalability here.
6 For example, session state, credentials for authentication, cached data, and so on.
7 Originally stated by Jon Postel in “RFC 761” on TCP in 1980.
8 It has, among other things, influenced the Tolerant Reader Pattern.
9 For an in-depth discussion about the art of event versioning, I recommend Greg Young’s book Versioning in an Event Sourced System.
10 There is a semantic difference between a service that is truly new, compared to a new version of an existing service.
Get Reactive Microsystems now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

