Part II. Wrangle
In this part of the book, youâll learn about data wrangling, the art of getting your data into R in a useful form for visualization and modeling. Data wrangling is very important: without it you canât work with your own data! There are three main parts to data wrangling:
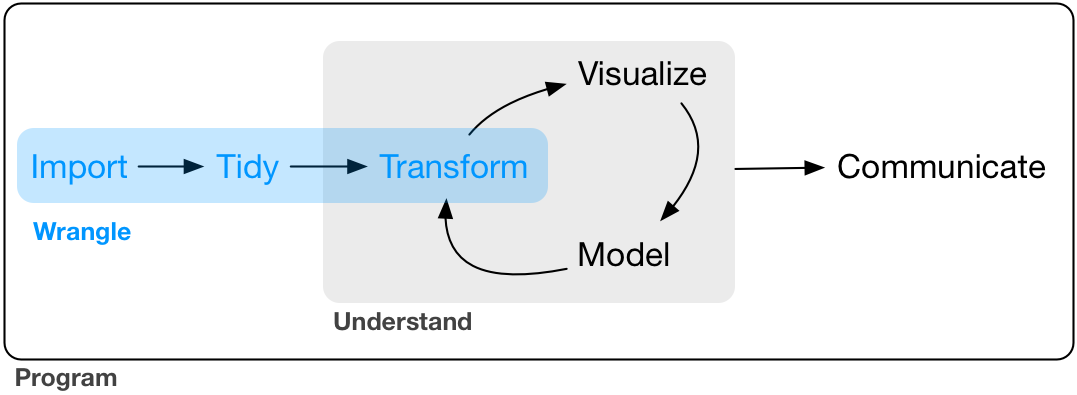
This part of the book proceeds as follows:
-
In Chapter 7, youâll learn about the variant of the data frame that we use in this book: the tibble. Youâll learn what makes them different from regular data frames, and how you can construct them âby hand.â
-
In Chapter 8, youâll learn how to get your data from disk and into R. Weâll focus on plain-text rectangular formats, but will give you pointers to packages that help with other types of data.
-
In Chapter 9, youâll learn about tidy data, a consistent way of storing your data that makes transformation, visualization, and modeling easier. Youâll learn the underlying principles, and how to get your data into a tidy form.
Data wrangling also encompasses data transformation, which youâve already learned a little about. Now weâll focus on new skills for three specific types of data you will frequently encounter in practice:
-
Chapter 10 will give you tools for working with multiple interrelated datasets.
-
Chapter 11 will introduce regular expressions, a powerful tool for manipulating strings.
-
Chapter 12 will show ...
Get R for Data Science now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

