9
Inferential Statistics
In the last few chapters we have modeled uncertainty using the tools of probability theory. Problems in probability theory may require a fair level of mathematical sophistication, and often students are led to believe that the involved calculations are the real difficulty. However, this is not the correct view; the real issue is that whatever we do in probability theory assumes a lot of knowledge. When dealing with a random variable, we need a function describing its whole probability distribution, like CDF, PMF, or PDF; in the multivariate case, the full joint distribution might be required, which can be a tricky object to specify. More often than not, this knowledge is not available and it must be somehow inferred from available data, if we are lucky enough to have them.
It is quite instructive to compare the definition of expected value in probability theory, assuming a continuous distribution, and sample mean in descriptive statistics:
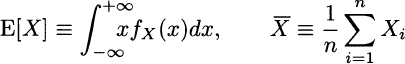
The first expression looks definitely more intimidating than the second one, which is an innocent-looking average. Yet, the real trouble is getting to know the PDF fX(x); calculating the integral is just a technicality. In this chapter we relate these two concepts, as the sample mean can be used to estimate the expected value, when we do not know the underlying probability density. Indeed, the sample mean does not look ...
Get Quantitative Methods: An Introduction for Business Management now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

