This crawl only did a single depth crawl. The crawl can be increased with the following change to the code:
crawl_depth = 2process = CrawlerProcess({ 'LOG_LEVEL': 'ERROR', 'DEPTH_LIMIT': crawl_depth})process.crawl(WikipediaSpider)spider = next(iter(process.crawlers)).spiderspider.max_items_per_page = 5spider.max_crawl_depth = crawl_depthprocess.start()
Fundamentally the only change is to increase the depth one level. This then results in the following graph (there is randomization in any spring graph so the actual results have a different layout):
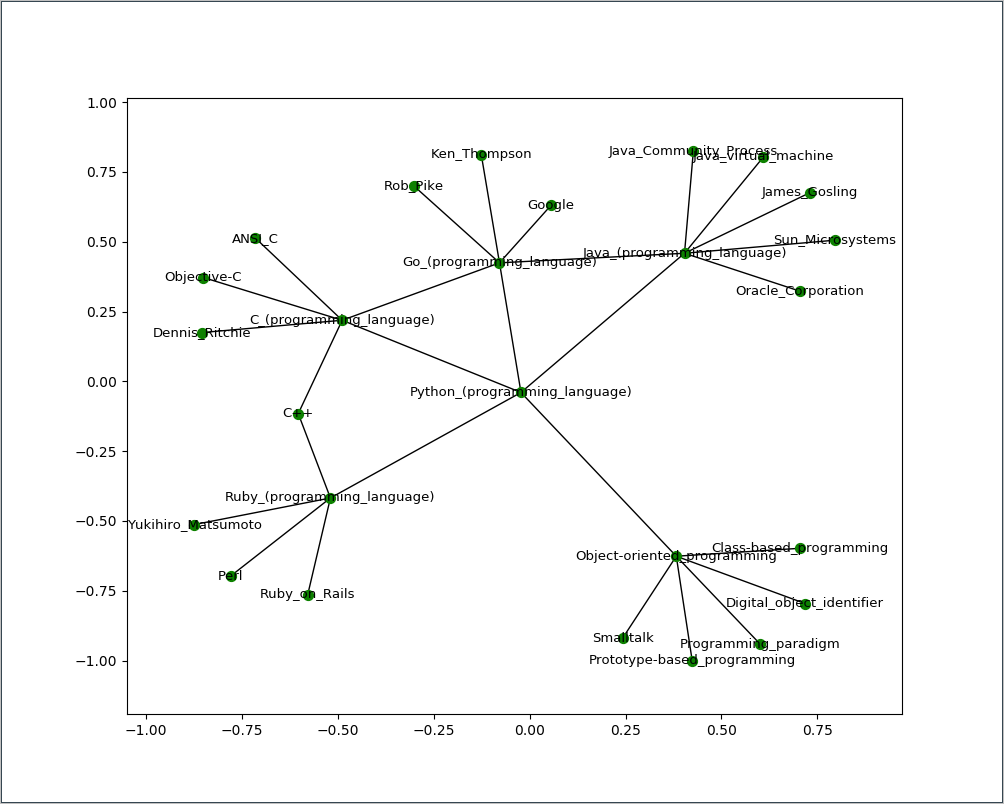
Spider graph of the links
This begins to be interesting as we now start to see ...

