Unsupervised learning – clustering and dimensionality reduction
A lot of existing data is not labeled. It is still possible to learn from data without labels with unsupervised models. A typical task during exploratory data analysis is to find related items or clusters. We can imagine the Iris dataset, but without the labels:
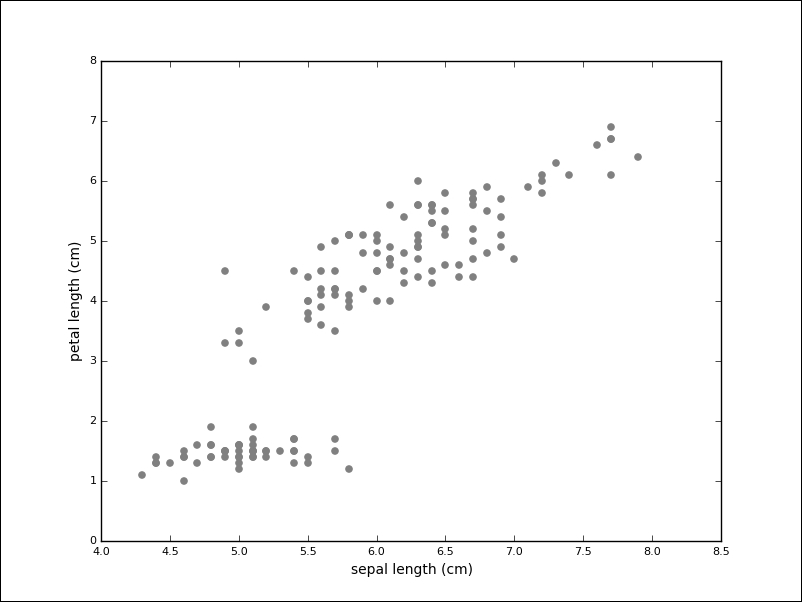
While the task seems much harder without labels, one group of measurements (in the lower-left) seems to stand apart. The goal of clustering algorithms is to identify these groups.
We will use K-Means clustering on the Iris dataset (without the labels). This algorithm expects the number of clusters to be specified in advance, which ...
Get Python: Data Analytics and Visualization now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

