Flattening a deep tree
Some of the included corpora contain parsed sentences, which are often deep trees of nested phrases. Unfortunately, these trees are too deep to use for training a chunker, since IOB tag parsing is not designed for nested chunks. To make these trees usable for chunker training, we must flatten them.
Getting ready
We're going to use the first parsed sentence of the treebank corpus as our example. Here's a diagram showing how deeply nested this tree is:
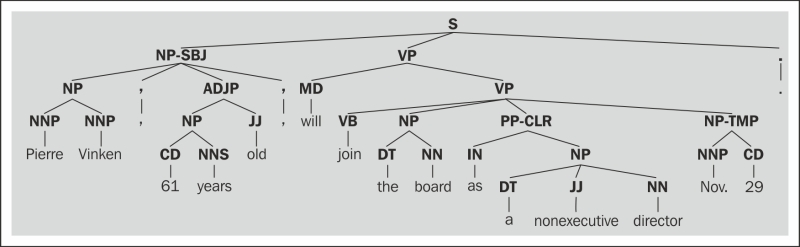
You may notice that the part-of-speech tags are part of the tree structure instead of being included with the word. This will be handled later using the Tree.pos() method, which ...
Get Python 3 Text Processing with NLTK 3 Cookbook now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

