365
13.2
Codierung und Decodierung
Wie lautet der Name des Buchstabens mit der Unicode-Nummer 12345?
13.2.2 Vertiefung: Zeichenketten durch Bytefolgen darstellen
Wenn Sie eine Zeichenkette in einer Textdatei speichern, wird die Zeichenkette zunächst in
einen Bytestring überführt. Das ist eine Folge von Oktetten (Acht-Bit-Einheiten), die jeweils
Zahlen zwischen 0 und 255 repräsentieren. Dabei wird eine Codierung verwendet, eine
Abbildung, die jedem platonischen Zeichen ein oder mehrere Bytes zuordnet. Tabelle 13.6
gibt einen Überblick über die wichtigsten Standardcodierungen.
Zeichenketten, d.h. Objekte der Python-Klasse
str, besitzen die Methode encode(). Sie lie-
fert zu dem String einen Bytestring (Objekt der Klasse
bytes). Wenn man die Methode ohne
Argument aufruft, wird die voreingestellte Codierung/Decodierung (Codec) verwendet.
Der Bytestring, so wie er auf dem Bildschirm dargestellt wird, beginnt hinter dem Hoch-
komma mit zwei Escape-Sequenzen. Sie repräsentieren Buchstaben mit den Hexadezimal-
nummern C3 und 84. Das ist die Bildschirmdarstellung. Eigentlich besteht aber ein
Bytestring einfach nur aus Oktetten, d.h. Zahlen zwischen 0 und 255. Probieren Sie es aus:
>>> unicodedata.name(chr(12345))
'HANGZHOU NUMERAL TWENTY'
Codierung Erklärung
ascii American Standard Code for Information Interchange, 7-Bit-Zei-
chencode (Nummern von 0 bis 127) zur Darstellung der Zeichen des
englischen Alphabets
latin-1
iso-88559-1
Latin Alphabet No. 1, 8-Bit-Zeichencode für Zeichen aus europäi-
schen Sprachen. Die ersten 128 Zeichen entsprechen dem ASCII-
Code.
utf-8 Unicode Transformation Format, verbreitetste Codierung für Uni-
code-Zeichen, verwendet 8 Bit (ein Oktett bzw. ein Byte) für ASCII-
Zeichen und zwei bis vier Oktette für die übrigen Unicode-Zeichen.
Tabelle 13.6: Einige Standardcodierungen für Zeichen
>>> wort = "Ärger"
>>> wort_bytes = wort.encode()
>>> wort_bytes
b'\xc3\x84rger'
>>> for c in wort_bytes:
print(c, end=" ")
195 132 114 103 101 114
Kapitel 13
Verarbeitung von Zeichenketten
366
Beachten Sie, dass das Wort Ärger, das aus fünf Buchstaben besteht, als Bytestring aus sechs
Zahlen dargestellt wird. Der Buchstabe
Ä wurde nämlich durch zwei Oktette (195 und 132)
codiert.
Die Codierung, die bei Ihrem Python-Interpreter voreingestellt ist, heißt utf-8 (Unicode
Transformation Format, 8 Bit). Sie ist die am meisten verwendete Codierung für Unicode-
Zeichen. utf-8 verwendet für die ASCII-Zeichen (Nummer 0 bis 127) jeweils ein Oktett
(8 Bit) und für die übrigen Zeichen eine Folge aus zwei bis vier Oktetten. ASCII-Zeichen
sind Ziffern, Satzzeichen, einige Sonderzeichen und die Buchstaben, die im englischen
Alphabet vorkommen. Das Ä gehört nicht dazu und wird deshalb durch zwei Oktette darge-
stellt. Weil für die besonders häufig vorkommenden ASCII-Zeichen jeweils nur ein Byte
benötigt wird, ist utf-8 besonders platzsparend.
Bytestrings besitzen die Methode
decode() zum Decodieren. Sie gibt ein String-Objekt
zurück, also eine Folge von Schriftzeichen. Wenn Sie keine Codierung/Decodierung (Codec)
als Argument angeben, wird wieder utf-8 verwendet:
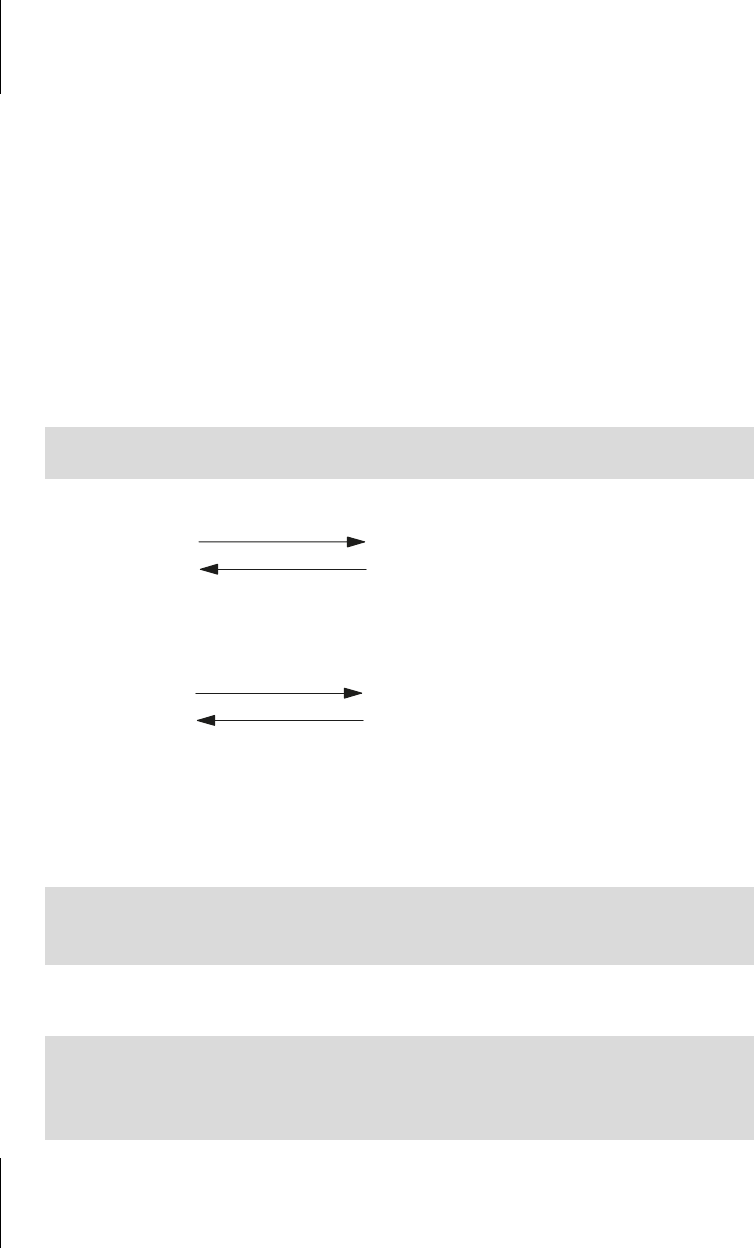
Abb. 13.2: Codierung und Decodierung
Vielleicht möchten Sie kontrollieren, welche Codierung in Ihrem System voreingestellt ist.
Das geht so:
Beim Codieren und Decodieren können Sie auch andere Codecs wählen:
>>> print(wort_bytes.decode())
Ärger
>>> import sys
>>> sys.getdefaultencoding()
'utf-8'
>>> wort = "Ärger"
>>> wort_latin = wort.encode("latin-1")
>>> wort_latin
b'\xc4rger'
platonische Zeichen
Oktette
(Bytestring)
Codierung
Decodierung
Ä
rger
196 114 103 101 114
Codierung mit Latin-1
(ISO-8859-1)
Decodierung mit Latin 1
Get Python 3 - Lernen und professionell anwenden now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

