
363
13.2
Codierung und Decodierung
13.1.5 Suchen und Ersetzen
Beispiele:
13.2 Codierung und Decodierung
Dieser Abschnitt ist etwas spezieller und beschäftigt sich mit der Codierung von Zeichen-
ketten. Im Prinzip geht es darum, wie die Schriftzeichen eines Strings gespeichert werden.
Wenn Sie das nicht interessiert, überspringen Sie den Abschnitt einfach.
13.2.1 Platonische Zeichen und Unicode
Unicode ist ein Standard für sinntragende Schriftzeichen aus der ganzen Welt. Zurzeit sind
im Unicode-Reservoir etwa 100.000 Zeichen registriert und jedes Jahr werden es mehr.
Nun können ja Buchstaben je nach Schriftart unterschiedlich aussehen. Im Unicode-Stan-
dard geht es allein um so genannte platonische Schriftzeichen, bei denen von typografischen
Aspekten abstrahiert wird. So besteht ein platonisches »kleines i« aus einem kleinen senk-
rechten Strich mit einem Punkt darüber. Es ist gleichgültig, wie groß der Strich und der
Punkt sind und wie sie im Detail geformt sind. Unicode ordnet jedem Schriftzeichen eine
Nummer und einen eindeutigen Namen zu. Die Nummern werden von den Standardfunk-
tionen
ord() und chr() verwendet.
Der Aufruf
ord(c) liefert zu einem einzelnen Schriftzeichen c (String der Länge 1) seine
Unicode-Nummer. Der Aufruf
chr(n) liefert zu einer Unicode-Nummer n das zugehörige
Zeichen. Beispiel:
Methode Erklärung
count(sub)
Liefert Anzahl der Vorkommen der Zeichenkette sub.
find(sub)
Zurückgegeben wird der Index der ersten Position, an der die Zei-
chenkette
sub als Teilstring vorkommt, und -1, falls sub nicht
gefunden wird.
replace(old, new)
Vorkommen der Zeichenkette old werden durch new ersetzt.
Tabelle 13.5: String-Methoden zum Suchen und Ersetzen
>>> 'Hallenbad'.count('a')
2
>>> 'Gartenteich'.find('ei') # String 'ei' beginnt bei Index 7
7
>>> wetter = 'Regenschauer'
>>> wetter.replace('Regen', 'Hagel')
'Hagelschauer'
Kapitel 13
Verarbeitung von Zeichenketten
364
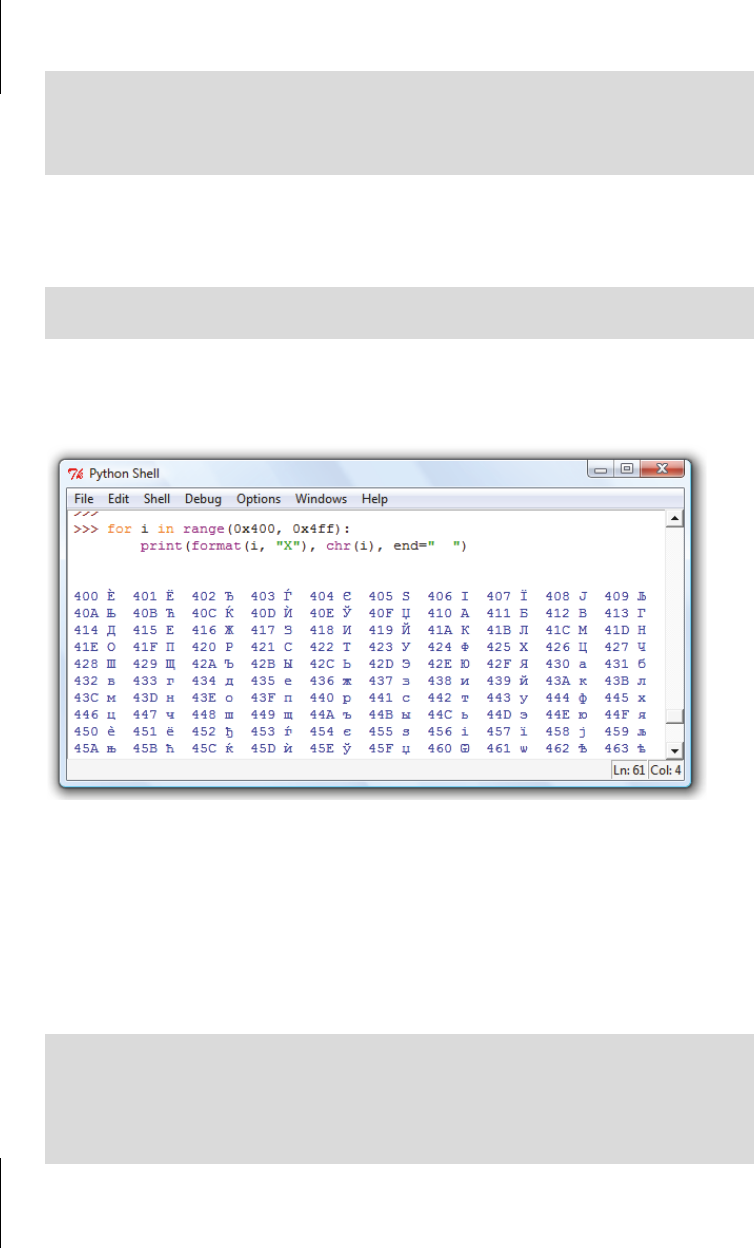
Die Hexadezimalzahlen 400 bis 4FF sind Unicode-Nummern für kyrillische Buchstaben.
Das folgende Programm gibt kyrillische Zeichen und ihre Nummern auf dem Bildschirm
aus.
Der Aufruf von
format(i, "X") bewirkt, dass die Zahl i in hexadezimaler (und nicht dezi-
maler) Darstellung ausgegeben wird. Das Ergebnis sehen Sie in Abbildung 13.1.
Abb. 13.1: Aufzählung kyrillischer Buchstaben
Tabellen mit Unicode-Nummern finden Sie im Internet: http://www.unicode.org/charts/.
Schriftzeichen können in Python-Skripten auch mit ihren Unicode-Namen angesprochen
werden. Dazu müssen Sie das Modul
unicodedata importieren. Der Funktionsaufruf uni-
codedata.lookup(name)
liefert zu einem Unicode-Namen das zugehörige Schriftzeichen.
Mit
unicodedata.name(ch) erhalten Sie zu einem Zeichen ch den Unicode-Namen. Viel-
leicht interessiert Sie, wie das deutsche ß genannt wird:
>>> ord("ß")
223
>>> chr(223)
'ß'
>>> for i in range(0x400, 0x4ff):
.....print(format(i, "X"), chr(i), end=" ")
>>> import unicodedata
>>> unicodedata.name("ß")
'LATIN SMALL LETTER SHARP S'
>>> unicodedata.lookup('LATIN SMALL LETTER SHARP S')
'ß'
Get Python 3 - Lernen und professionell anwenden now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

