Data. Databases. It just kind of makes sense. If you have data, you need to put it somewhere. And what better place to put it than in a âdataâ base?
Just to make sure I had all the âbasesâ covered, I did a quick search on the Internet for a useful definition. What a shock. According to virtually every web site I found, a database is âa collection of data organized for easy retrieval by a computer.â With a definition like that, pretty much everything I put on my system is stored in a database. All my disk files are organized for easy access. My saved emails can be sorted by subject or date received or sender, so they must be in a database, too. Even this document can be searched and sorted in any manner I wish. Is it a database?
Perhaps that definition is too broad. These days, when we think of âdatabase,â itâs generally a relational database system. Such databases are built on the ârelational modelâ designed by Edgar Codd of IBM. In 1970, he issued âA Relational Model of Data for Large Shared Data Banks,â the seminal paper on relational modeling, and later expanded on the basic concepts with C. J. Date, another âreal programmer.â Upon reading that 1970 paperâand if you have a free afternoon, you would really benefit from spending time with your family or friends rather than reading that paperâyou will enter a world of n-tuples, domains, and expressible sets. Fortunately, you donât need to know anything about these terms to use relational database systems.
The relational databases that most programmers use collect data in tables, each of which stores a specific set of unordered records. For convenience, tables are presented as a grid of data values, with each row representing a single record and each column representing a consistent field that appears in each record. Table 4-1 presents a table of orders, with a separate record for each line item of the order.
Table 4-1. Boy, a lot of people drink coffee and tea
Record ID | Order ID | Customer ID | Customer Name | Product ID | Product | Price | Quantity |
|---|---|---|---|---|---|---|---|
92231 | 10001 | AA1 | Al Albertson | BEV01COF | Coffee | 3.99 | 3 |
92232 | 10001 | AA1 | Al Albertson | BRD05RYE | Rye bread | 2.68 | 1 |
92233 | 10002 | BW3 | Bill Williams | BEV01COF | Coffee | 3.99 | 1 |
92234 | 10003 | BW3 | Will Williams | BEV01COF | Tea | 3.99 | 2 |
92235 | 10004 | CC1 | Chuck Charles | CHP34PTO | Potato chips | 0.99 | 7 |
Putting all of your information in a table is really convenient. The important data appears at a glance in a nice and orderly arrangement, and itâs easy to sort the results based on a particular column. Unfortunately, this table of orders has a lot of repetition. Customer names and product names repeat multiple times. Also, although the product ID âBEV01COFâ indicates coffee, one of the lines lists it as âTea.â A few other problems are inherent in data thatâs placed in a single flat file database table.
Mr. Codd, the brilliant computer scientist that he was, saw these problems, too. But instead of just sitting around and complaining about them like I do, he came up with a solution: normalization. By breaking the data into separate tables with data subsets, assigning a unique identifier to each record/row in every table (a primary key), and making a few other adjustments, the data could be ânormalizedâ for both processing efficiency and data integrity. For the sample orders in Table 4-1, the data could be normalized into three separate tables: one for order line items, one for customers, and one for products (see Table 4-2, Table 4-3, and Table 4-4, respectively). In each table, Iâve put an asterisk next to the column title that acts as the primary key column.
Table 4-2. The table of customers
Customer ID * | Customer Name |
|---|---|
AA1 | Al Albertson |
BW3 | Bill Williams |
CC1 | Chuck Charles |
Table 4-3. The table of products
Product ID * | Product Name | Unit Price |
|---|---|---|
BEV01COF | Coffee | 3.99 |
BRD05RYE | Rye bread | 2.68 |
BEV01COF | Coffee | 3.99 |
CHP34PTO | Potato chips | 0.99 |
Table 4-4. The table of order line items
Record ID * | Order ID | Customer ID | Product ID | Quantity |
|---|---|---|---|---|
92231 | 10001 | AA1 | BEV01COF | 3 |
92232 | 10001 | AA1 | BRD05RYE | 1 |
92233 | 10002 | BW3 | BEV01COF | 1 |
92234 | 10003 | BW3 | BEV01COF | 2 |
92235 | 10004 | CC1 | CHP34PTO | 7 |
To get combined results from multiple tables at once, join (or link) their matching fields. For instance, you can link the Customer ID field in the table of line items with the matching Customer ID primary key field in the table of customers. Once joined, the details for a single combined line item record can be presented with the matching full customer name. Itâs the same for direct joins with any two tables that have linkable fields. Figure 4-1 shows the relationships between the customer, product, and order line tables.
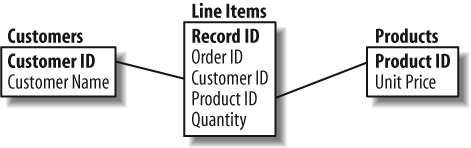
To join tables together, relational databases implement query languages that allow you to manipulate the data using relational algebra (from which the term relational database derives). The most popular of these languages, SQL, uses simple English-like sentences to join, order, summarize, and retrieve just the data values you need. The primary statement, SELECT, provides basic data selection and retrieval features. Three other common statements, INSERT, UPDATE, and DELETE, let you manipulate the records stored in each table. Together, these four statements make up the primary data manipulation language (DML) commands of SQL. SQL also includes data definition language (DDL) statements that let you design the tables used to hold the data, as well as other database features. Iâll show examples of various SQL statements later in this chapter.
Vendor-specific systems such as Microsoftâs SQL Server, Oracleâs Oracle, Microsoftâs Access, and IBMâs DB2 extend these core DDL and DML features through additional data analysis and management tools. They also battle one another over important features such as data replication, crash-proof data integrity, the speed at which complex queries return the requested results, and who has the biggest private jet.
Microsoftâs primary business-level database tool is SQL Server. Although it began its life as a derivative of Sybase (another relational database), it has been given the Microsoft touch. Unlike Access (Microsoftâs other relational database product), SQL Server includes advanced data management and analysis features, and a nifty price tag to go along with those features. Although Microsoft was somewhat late in joining the relational database game, it has done a pretty good job at playing catch-up. Oracle still gets high marks for at least its perception of being the most robust, the most stable, and the most platform-independent of the various players. But SQL Server scores big as well, especially with its somewhat lower costs and its more intuitive visual tools.
Originally, Microsoft touted SQL Server as a business-minded tool for business-minded people with their business-minded agendas and their business-minded three-piece poly-knit double-breasted suits, and it is still viewed in this way. But Microsoft is increasingly identifying the database as a development tool, especially with the 2005 release. It was no coincidence that Microsoft chose to debut that version of SQL Server November 7, 2005, the same day as the release of Visual Studio 2005. All flavors of Visual Studio now include some version of SQL Serverâeven the low-end Visual Studio Express Edition products have access to a SQL Server Express Edition complement. (As of this writing, it was available at no cost from Microsoftâs web site.) And itâs a two-way relationship between the products: you could always use SQL Server data in your .NET applications, but SQL Server 2005 now allows you to craft embedded stored procedures using .NET code, along with the native and more traditional T-SQL scripting language.
Tip
Microsoft announced the release of SQL Server 2008, the latest version of its star database product, in tandem with Visual Studio 2008. However, although the two products share a common launch date, the actual availability dates of the two products are months apart, with SQL Server 2008 coming out after Visual Studio. Since I cannot be sure that you, as a reader, already have access to SQL Server 2008, I have opted to use SQL Server 2005 as this bookâs core database. Almost everything you read about SQL Server 2005 in this book will work identically in SQL Server 2008. If you choose to use the 2008 version of the product, you should have no difficulties in following the discussion in this book.
SQL Server, as the name implies, is a âserverâ product. It runs in the background on a system and communicates with you, the user, by having you first establish a standard network connection with the server engine. This is true even if the SQL Server engine runs on your own workstation. Watching a server product is about as exciting as reading some of those other Visual Basic 2008 tutorial books that you wisely avoided, so Microsoft provides various client tools that let you manage databases, tables, and other relational database properties. SQL Server Management Studio is the standard enterprise-level client tool for managing SQL Server databases. For SQL Server 2005 Express Edition, Microsoft supplies a reduced yet friendlier tool, SQL Server Management Studio Express (see Figure 4-2). This tool lets you manage databases and process DDL and DML statements. Management Studio Express is not included in SQL Server 2005 Express Edition; you must download or obtain it separately from Microsoft. As of this writing, it is available at no cost from Microsoftâs web site.
Tip
Because some readers of Programming Visual Basic 2008 may only have access to SQL Server 2005 Express Edition (and the related SQL Server 2005 Management Studio Express tool), all examples in this book are designed for use with that edition of the database engine. This only impacts the few times when I refer specifically to the client tools. All SQL statements (both DDL and DML) presented in this book and in the Library Projectâs source code will work with any edition of SQL Server 2005 or SQL Server 2008.
Although Microsoft continues to update and sell Microsoft Access, it is recommending more and more that professional developers use and distribute databases in SQL Server format. Microsoft will even permit you to redistribute SQL Server 2005 Express Edition with your application. To do this, you must first obtain a âSQL Server 2005 Express Edition redistribution licenseâ from Microsoft. Fortunately, itâs free and can be had for the asking from the SQL Server 2005 Express Edition web site, http://www.microsoft.com/sql/express.
Conducting business in Japan is pretty easyâonce you know the language. The same is true of SQL Server: itâs pretty easy to manipulate and access data, once you know the language. In this case, the language is SQL, or Structured Query Language. Originally developed by IBM, SQL has since become a standard across the database industry. Well, kind of. As with America and England, Microsoftâs SQL Server and Oracleâs Oracle are two relational databases that are divided by a common language. The core parts of the SQL language are pretty consistent between vendors, but each supplier adds a lot of extra features and syntax variations designed by Edgar Codd wannabes.
This section describes those DDL and DML statements that will be most useful in our development of the Library program. Youâll be glad to know that SQL isnât too picky about the formatting of the various statements. Upper- and lowercase distinctions are ignored; SELECT is the same as select is the same as SeLeCt. (Traditional SQL code is mostly uppercase. I use uppercase for all keywords, and mixed case for tables, fields, and other custom items. Whatever you choose, consistency is important.) Also, employ whitespace as you see fit. You can put statements on one gigantic line, or put every word on a separate line. The only time whitespace and case matter is in the actual data text strings; whatever you type, thatâs how it stays.
SQL statements normally end with a semicolon, but some tools do not require you to include the semicolon, and other tools require that you exclude it. When using the SQL Server visual client tools (Management Studio and Management Studio Express), semicolons are optional, but itâs a good idea to include them when you are using multiple statements together, one after another. SQL statements used in Visual Basic code never include semicolons.
Later, when you look at a SQL script I wrote, you will see the word GO from time to time. In SQL Server, this command says, âFor all of the other statements that appeared so far, go ahead and process them now.â
This may come as a shock to you, but before you can store any data in a table, you have to create that table. SQL has just the tool to do this: the CREATE TABLE statement. Itâs one of the many DDL statements. The basic syntax is pretty straightforward:
CREATE TABLE tableName ( fieldName1 dataType options, fieldName2 dataType options, and so on... )
Just fill in the parts and youâre ready to populate (data, that is). Table and field names are built from letters and digits; you can include spaces and some other special characters, but it makes for difficult coding later on. Each vendor has its own collection of data types; Iâll stick with the SQL Server versions here. The options let you specify things such as whether the field requires data, whether it represents the tableâs primary key, and other similar constraints. Extensions to the syntax let you set up constraints that apply to the entire table, indexes (which let you sort or search a specific column more quickly), and data storage specifics.
Hereâs a sample CREATE TABLE statement that could be used for the table of order line items (refer to Table 4-4):
CREATE TABLE LineItems
(
RecordID bigint IDENTITY PRIMARY KEY,
OrderID bigint NOT NULL,
CustomerID varchar(20) NOT NULL
REFERENCES Customers (CustomerID),
ProductID varchar(20) NOT NULL,
Quantity smallint NOT NULL
)The IDENTITY keyword lets SQL Server take charge of filling the RecordID field with data; it will use a sequential counter to supply a unique RecordID value with each new record. The PRIMARY KEY clause identifies the RecordID field as the unique identifying value for each record in the table. The bigint and smallint data types indicate appropriately sized integer fields, and the varchar type provides space for text, up to the maximum length specified in the parentheses (20 characters). The REFERENCES option clause identifies a relationship between this LineItems table and another table named Customers; values in the LineItems.CustomerID field match the key values from the Customers.CustomerID field. (Note the âdotâ syntax to separate table and field names. It shows up everywhere in SQL.) References between tables are also known as foreign references.
If you need to make structure or option changes to a table or its fields after it is created, SQL includes an ALTER TABLE statement that can change almost everything in the table. Additionally, there is a related DROP TABLE statement used to get rid of a table and all of its data. You might want to avoid this statement on live production data, as users tend to get a bit irritable when their data suddenly disappears off the surface of the earth.
Table 4-5 summarizes the available data types used in SQL Server.
Table 4-5. SQL Server data types
Data type | Description |
|---|---|
| An 8-byte (64-bit) integer field for values ranging from â9,223,372,036,854,775,808 to 9,223,372,036,854,775,807. |
| Fixed-length binary data, up to 8,000 bytes in length. You specify the length through a parameter, as in |
| Supports three possible values: |
| Fixed-length standard ( |
| This data type is used within stored procedures, and cannot be used to create a column. |
| A general date and time field for dates ranging from January 1, 1753 AD to December 31, 9999 AD. Time accuracy for any given value is within 3.33 milliseconds. SQL Server 2008 adds several new date-related data types: |
| A fixed-precision and scale decimal field. You specify the maximum number of digits to appear on both sides of the decimal point (the precision) and the maximum number of those digits that can appear on the right side of the decimal point (the scale). For instance, a setting of |
| A floating-point decimal field with variable storage. You can specify the number of bits used to store the value, up to 53. By default, all 53 bits are used, so a setting of |
| This data type, new with SQL Server 2008, supports querying of hierarchical and tree-shaped data. It is not available in SQL Server 2005. |
| Donât use these data types, as they will eventually be removed from SQL Server. |
| A 4-byte (32-bit) integer field for values ranging from â2,147,483,648 to 2,147,483,647. |
| An 8-byte (64-bit) high-accuracy field for storing currency values, with up to four digits after the decimal point. Stored data values range from â922,337,203,685,477.5808 to 922,337,203,685,477.5807. |
| This data type is used to record modification events on records. There are restrictions on its use, and it is not guaranteed to be unique within a table. |
| A general date and time field for dates ranging from January 1, 1900 AD to June 6, 2079 AD. Time accuracy for any given value is within one minute. |
| A 2-byte (16-bit) integer field for values ranging from â32,768 to 32,767. |
| A 4-byte (32-bit) high-accuracy field for storing currency values, with up to four digits after the decimal point. Stored data values range from â214,748.3648 to 214,748.3647. |
| A generic type that stores values from many other type-specific fields. |
| A special field that temporarily stores the results of a query in a compacted table format. Defining a table field is somewhat complex, and its use naturally carries with it certain restrictions. |
| A 1-byte (8-bit) unsigned integer field for values ranging from 0 to 255. |
| A 16-byte globally unique identifier (GUID). The related |
| Variable-length binary data, up to 8,000 bytes in length. You specify the length through a parameter, as in |
| Variable-length standard ( |
| Provides storage for typed and untyped XML data documents, up to 2 GB. |
Although DDL statements are powerful, they arenât used that much. Once you create your database objects, thereâs not much call for tinkering. The DML statements are more useful for everyday data surfing.
The INSERT statement adds data records to a table. Data is added to a table one record at a time. (A variation of INSERT lets you insert multiple records, but those records must come from another existing table source.) To use the INSERT statement, specify the destination table and fields, and then the individual values to put into each field. One data value corresponds to each specified data column name.
INSERT INTO LineItems (OrderID, CustomerID, ProductID, Quantity) VALUES (10002, 'BW3', 'BEV01COF', 1)
Assuming this statement goes with the CREATE TABLE statement written earlier, this insert action will add a new record to the LineItems table with five new fieldsâfour specified fields, plus the primary key automatically added to the RecordID field (since it was marked as IDENTITY). SQL Server also does a variety of data integrity checks on your behalf. Each data field you add must be of the right data type, but you already expected that. Since we designed the CustomerID field to be a reference to the Customer table, the insert will fail if customer BW3 does not already exist in the Customer table.
Numeric literals can be included in your SQL statements as needed without any additional qualification. String literals are always surrounded by single quotes, as is done for the customer and product IDs in this INSERT statement. If you need to include single quotes in the literal, enter them twice:
'John O''Sullivan'
Surround literal date and time values with single quotes:
'7-Nov-2005'
Such date and time values accept any recognized format, although you should use a format that is not easy for SQL Server to misinterpret.
Many field types support an âunassignedâ value, a value that indicates that the field contains no data at all. Such a value is known as the ânullâ value, and is specified in SQL Server using the NULL keyword. You cannot assign NULL to primary key fields, or to any field marked with the NOT NULL option.
To remove a previously added record, use the DELETE statement:
DELETE FROM LineItems WHERE RecordID = 92231
The DELETE statement includes a WHERE clause (the WHERE RecordID = 92231 part). WHERE clauses let you indicate one or more records in a table by making comparisons with data fields. Your WHERE clauses can include AND and OR keywords to join multiple conditions, and parentheses for grouping.
DELETE FROM LineItems WHERE OrderID = 10001 AND ProductID = 'BRD05RYE'
Such a DELETE statement may delete zero, one, or 1,000 records, so precision in the WHERE clause is important. To delete all records in the table, exclude the WHERE clause altogether.
DELETE FROM LineItems
The UPDATE statement also uses a WHERE clause to modify values in existing table records.
UPDATE LineItems SET Quantity = 4 WHERE RecordID = 92231
Assignments are made to fields with the SET clause; put the field name (Quantity) on the left side of the equals sign, and the new value on the right (4). To assign multiple values at once, separate each assignment with a comma. You can also include formulas and calculations.
UPDATE LineItems SET Quantity = Quantity + 1, ProductID = 'BEV02POP' WHERE RecordID = 92231
As with the DELETE statement, the UPDATE statement may update zero, one, or many records based on which records match the WHERE clause.
The final DML statement, and the one most often used, is SELECT.
SELECT ProductID, Quantity FROM LineItems WHERE RecordID = 92231
SELECT scans a table (LineItems), looking for all records matching a given criterion (RecordID = 92231), and returns a smaller table that contains just the indicated fields (ProductID and Quantity) for the matching records. The most basic query returns all rows and columns.
SELECT * FROM LineItems
This query returns all records from the table in no particular order. The asterisk (*) means âinclude all fields.â
The optional ORDER BY clause returns the results in a specific order.
SELECT * FROM LineItems WHERE Quantity > 5 ORDER BY ProductID, Quantity DESC
This query returns all records that have a Quantity field value of more than five, and sorts the results first by the ProductID column (in ascending order) and then by the numeric quantity (in descending order, specified with DESC).
Aggregate functions and grouping features let you summarize results from the larger set of data. The following query documents the total ordered quantity for each product in the table:
SELECT ProductID, SUM(Quantity) FROM LineItems GROUP BY ProductID
You can use joins to link together the data from two or more distinct tables. The following query joins the LineItems and Customer tables on their matching CustomerID columns. This SELECT statement also demonstrates the use of table abbreviations (the âLIâ and âCUâ prefixes) added through the AS clauses; they arenât usually necessary, but they can help make a complex query more readable.
SELECT LI.OrderID, CU.CustomerName, LI.ProductID FROM LineItems AS LI INNER JOIN Customer AS CU ON LI.CustomerID = CU.CustomerID ORDER BY LI.OrderID, CU.CustomerName
This table uses an âinner join,â one of the five main types of joins, each of which returns different sets of records based on the relationship between the first (left) and second (right) tables in the join:
- Inner join
Returns only those records where there is a match in the linked fields. This type of join uses the
INNER JOINkeywords.- Left outer join
Returns every record from the left table and only those records from the right table where there is a match in the linked fields. If a left table record doesnât have a match, it acts as though all the fields in the right table for that record contain
NULLvalues. This type of join uses theLEFT JOINkeywords. One use might be to join theProductandLineItemstables. You could return a list of the full product name for all available products, plus the total quantity ordered for each one. By putting theProducttable on the left of a left outer join, the query would return all product names, even if that product had never been ordered (and didnât appear in theLineItemstable).- Right outer join
This works just like a left outer join, but all records from the right table are returned, and just the left table records that have a match. This type of join uses the
RIGHT JOINkeywords.- Full outer join
Returns all records from the left and right tables, whether they have matches or not. When there is a match, it is reflected in the results. This type of join uses the
FULL JOINkeywords.- Cross join
Also called a Cartesian join. Returns every possible combination of left and right records. This type of join uses the
CROSS JOINkeywords.
Joining focuses on the relationship that two tables have. (This use of ârelationship,â by the way, is not the basis for the term relational database.) Some tables exist in a âparent-childâ relationship; one âparentâ record has one or more dependent âchildâ records in another table. This is often true of orders; a single âorder headerâ has multiple âline items.â This type of relationship is known as one-to-many, since one record is tied to many records in the other table. And the relationship is unidirectional; a given child record does not tie to multiple parent records.
A one-to-one relationship ties a single record in one table to a single record in another table. Itâs pretty straightforward, and is often used to enhance the values found in the original record through a supplementary record in a second table.
In a many-to-many relationship, a single record in one table is associated with multiple records in a second table, and a single record in that second table is also associated with multiple records in the first table. A real-world example would be the relationship between teachers and students in a college setting. One teacher has multiple students in the classroom, but each student also has multiple teachers each semester. Practical implementations of many-to-many relationships actually require three tables: the two related tables, and a âgo-betweenâ table that links them together. I will show you a sample of such a table in the upcoming "Project" section of this chapter.
The sample statements I listed here only scratch the surface of the data manipulation possibilities available through SQL. But by now you should have noticed that SQL is remarkably English-like in syntax, much more than even Visual Basic. In fact, the original name for the languageâSEQUELâwas an acronym for âStructured English Query Language.â As the SQL statements get more complex, they will look less and less like an eighth-grade essay and more like random collections of English words.
The goal here is to introduce you to the basic structure of SQL statements. Most of the statements we will encounter in the Library Project will be no more complex than the samples included here. If youâre hungry for more, the âBooks Onlineâ component installed with SQL Server (a separate download for the Express Edition) has some pretty good usage documentation. Several good books on the ins and outs of SQL, including vendor-specific dialects, are also available.
Visual Basic can interact with data stored in a database in a few different ways:
Use ADO.NET, the primary data access technology included in the .NET Framework, to interact with database-stored content. This is the method used throughout the Library program to interact with its database. ADO.NET is discussed in Chapter 10, with examples of its use. I will also introduce ADO.NET-specific code into the Library Project in that chapter.
Use the âdata bindingâ features available in Visual Basic and Visual Studio. Binding establishes a connection between an on-screen data control or similar data-enabled object and content from a database. Code written for you by Microsoft takes care of all the communication work; you can even drag and drop these types of interactions. Although I will discuss data binding in Chapter 10 (since binding is based on ADO.NET), I tend to avoid it since it reduces the amount of control the programmer can exert on user data management. Data binding will not be used in the Library program.
Extract the data from the database into a standard file, and use file manipulation features in Visual Basic to process the data. Hmm, that doesnât seem very useful, but I have actually had to do it, especially in the old days when some proprietary databases could not interact easily with Visual Basic code.
Each time you need some of the data, tell the user that somehow the data has been lost, and that it must be reentered immediately. If you have ever been curious to know what the inside of an unemployment office looks like, this could be your chance.
If you are a former Visual Basic 6.0 (or earlier) programmer, you may think that your knowledge of ADO will translate directly into ADO.NET development. Ha! You couldnât be more wrong. Although the two data technologies share a partial name, the code written to use each method varies considerably. I will not discuss the older ADO technology at all in this book.
Technical content that describes the tables and fields in your applicationâs database represents the most important piece of documentation generated during your applicationâs lifetime. In fact, the need for good documentation is the basis for one of my core programming beliefs: project documentation is as important, and sometimes more important, than source code.
You may think Iâm joking about this. Although you will (hopefully) find a lot of humor in the pages of this book, this is something I donât joke about. If you are developing an application that centers on database-stored user content, complete and accurate documentation of every table and field used in the database is a must. Any lack in this area willânot might, not perhaps, but willâlead to data integrity issues and a longer-than-necessary development timeline. Figure 4-3 puts it another way.

Why do I think that database documentation is even more important than user documentation or functional specifications? Itâs because of the impact the document will have on the userâs data. If you have a documented database, you can make guesses about the functional specification, and probably come pretty close. If you lack user documentation, you can always write it when the program is done (as though there was any other way?). But if you lack database documentation, you are in for a world of hurt.
If you havenât worked on large database projects before, you might not believe me. But I have. I once inherited an existing enterprise-wide database system written in Visual Basic 3.0. The source code was bad enough, but the associated undocumented 100-table database was a mishmash of inconsistently stored data values. The confusing stored procedure code wasnât much better. Since there wasnât a clear set of documentation on each field, the six programmers who originally developed the system had each made their own decisions about what range of data would be allowed in each field, or about which fields were required or not.
Tracing back through the uncommented 100,000 lines of source code to determine what every field did was not fun, and it took a few months to complete it with accuracy. Since the customer had paid for and expected a stable and coherent system, most of the extra cost involved in replacing the documentation that should have been there in the first place was borne by my development group. Donât let this happen to you!
Most Visual Basic applications target the business world and are designed to interact with some sort of database. Understanding the database system used with your application is important; even more important is documenting the specific database features you incorporate into your application.
Because of the influence of relational databases and the SQL language on the database industry, it wonât be hard to find a lot of resources to assist you in crafting SQL statements and complex data analysis queries. The Library Project in this book uses SQL Server 2005, but because of the generally consistent use of the core SQL language features, the application could just as easily have used Oracle, Microsoft Access, or any of a number of other relational databases.
To assist in my development of Visual Basic database projects, I always write a âTechnical Resource Kitâ document before I begin the actual coding of the application. The bulk of this word processing document consists of the table- and field-level documentation for the applicationâs associated database. Also included are the formats for all configuration and custom datafiles, a map of the online help pages, and information about third-party products used in the application. Depending on the type of application, my expectations for the user, and the terms of any contract, I may supply none, some, or all of the Resource Kitâs content to the user community.
Letâs begin the Technical Resource Kit for the Library Project by designing and documenting the database tables to be used by the application. This Resource Kit appears in the bookâs installation directory, in the Chapter 4 subdirectory, and contains the following three files:
- ACME Library Resource Kit.doc
A Microsoft Word version of the technical documentation for the project
- ACME Library Resource Kit.pdf
A second copy of the Technical Resource Kit, this time in Adobe Acrobat (PDF) format
- Database Creation Script.sql
A SQL Server database script used to build the actual tables and fields in the database
This section includes a listing of the tables included in the Library database. Each table includes a general description to assist you in your understanding of the database structure. You will encounter all of these tables in successive chapters, along with associated source code, so donât freak out if some table or field seems unknowable right now.
Although patrons do not need to log in to the application to look up items in the database, administrators must log in before they can access enhanced features of the program. The following four tables manage the security credentials of each administrator. The application uses SQL Server or Windows-based security credentials only to access the database initially, not to restrict features.
This table defines the features of the application that can be secured using group rights. These activities are linked with security groups (from the GroupName table) to establish the rights for a particular group.
Field | Type | Description |
|---|---|---|
|
| Primary key. This key is not auto-generated; the value supplied matches internal values used within the Library application. Required. |
|
| Descriptive name of this activity. Required. |
The following activities are defined at this time:
1âManage authors and names
2âManage author and name types
3âManage copy status codes
4âManage media types
5âManage series
6âManage security groups
7âManage library materials
8âManage patrons
9âManage publishers
10âManage system values
11âManage administrative users
12âProcess and accept fees
13âManage locations
14âCheck out library items
15âCheck in library items
16âAccess administrative features
17âPerform daily processing
18âRun system reports
19âAccess patrons without patron password
20âManage bar codes
21âManage holidays
22âManage patron groups
23âView administrative patron messages
Each record in this table defines a single security group. Librarians and other administrators each belong to a single security group.
Field | Type | Description |
|---|---|---|
|
| Primary key; automatically assigned. Required. |
|
| Name of this group. Required. |
This table connects records in the Activity table to records in the GroupName table (a many-to-many relationship) to establish the activities a security group can perform.
Field | Type | Description |
|---|---|---|
|
| Primary key. The associated security group. Foreign reference to |
|
| Primary key. The activity that members of the associated security group can perform. Foreign reference to |
This table contains the actual records for each librarian or administrator. Each record includes the userâs password and security group setting.
Field | Type | Description |
|---|---|---|
|
| Primary key; automatically assigned. Required. |
|
| Name of this user, administrator, or librarian. Required. |
|
| User ID that gives this user access to the system. It is entered into the Library programâs âloginâ form, along with the password, to gain access to enhanced features. Required. |
|
| The password for this user, in an encrypted format. Optional. |
|
| Is this user allowed to access the system? |
|
| To which security group does this user belong? Foreign reference to |
Several tables exist simply to provide a list of values to other tables. In an application, these list tables often appear as the choices in a drop-down (âcombo boxâ) control.
In the Library program, the word author is a generic term used for authors, illustrators, editors, and any other similar contributor to an item in the libraryâs inventory. This table lets you define those roles.
Field | Type | Description |
|---|---|---|
|
| Primary key; automatically assigned. Required. |
|
| Name of this type of author or contributor. Required. |
Copy status codes include things like âcirculating,â âbeing repaired,â and any other primary status the library wishes to set. The checked-in or checked-out status is handled through other features, as is the flag that indicates whether an item is a reference item.
Field | Type | Description |
|---|---|---|
|
| Primary key; automatically assigned. Required. |
|
| Name of this status entry. Required. |
Physical locations where library items are stored. This could be separate sites, or rooms or areas within a common location.
Field | Type | Description |
|---|---|---|
|
| Primary key; automatically assigned. Required. |
|
| Name of this location. Required. |
|
| The date when daily processing was last done for this location. If |
Types of media, such as books, magazines, videos, CDs, etc.
Field | Type | Description |
|---|---|---|
|
| Primary key; automatically assigned. Required. |
|
| Name of this media type. Required. |
|
| Number of days for which items in this type can be checked out, before renewal. Required. |
|
| Number of days to add to the original checkout period for a renewal of items within this type. Required. |
|
| Maximum number of times the item can be renewed by a patron before it must be returned. Required. |
|
| Amount charged per day for an overdue item of this type. Required. |
Categories of groups into which patrons are placed. These are not security groups, but general groups for reporting purposes. This was added to support grouping of patrons by units within a company, or by class/grade within a school library setting.
Field | Type | Description |
|---|---|---|
|
| Primary key; automatically assigned. Required. |
|
| Name of this patron group. Required. |
The tables in this section manage the actual inventory of items. Since a library may own more than one copy of a single item, these tables manage the ânamed itemâ and its individual âcopiesâ separately.
A library item, such as a book, CD, or magazine. This table represents a general item, and not the actual copy of the item.
Field | Type | Description |
|---|---|---|
|
| Primary key; automatically assigned. Required. |
|
| Title of this item. Required. |
|
| Subtitle of this item. Optional. |
|
| Full description of this item. Optional. |
|
| Edition number for this item. Optional. |
|
| This itemâs publisher. Foreign reference to |
|
| Dewey decimal number. Use |
|
| Library of Congress number. Use |
|
| ISBN, ISSN, or other standardized number of this item. Optional. |
|
| Library of Congress control number. Optional. |
|
| Year of original copyright, or of believed original copyright. Optional. |
|
| The series or collection in which this item appears. Foreign reference to |
|
| The media classification of this item. Foreign reference to |
|
| Is this title out of print? |
A single copy of a named item. Separate copies of the same item will appear as separate records in this table.
Field | Type | Description |
|---|---|---|
|
| Primary key; automatically assigned. Required. |
|
| The related named item record. Foreign reference to |
|
| Numbered position of this item within the set of copies for a named item. Required, and unique among items with the same |
|
| Comments specific to this copy of the item. Optional. |
|
| Is this copy available for checkout or circulation? |
|
| Has this copy been reported missing? |
|
| Is this a reference copy? |
|
| Any comments relevant to the condition of this copy. Optional. |
|
| Date this copy was acquired by the library. Optional. |
|
| Value of this item, either original or replacement value. Optional. |
|
| The general status of this copy. Foreign reference to |
|
| Bar code found on the copy. At this time, only numeric bar codes are supported. Optional. |
|
| The site or room location of this item. Foreign reference to |
An organization that publishes books or some other type of media.
Field | Type | Description |
|---|---|---|
|
| Primary key; automatically assigned. Required. |
|
| Name of the publisher. Required. |
|
| URL for this publisherâs web site. Optional. |
Someone who writes, edits, illustrates, or in some other way contributes to a book or media item. In all cases, when the term author appears in this table, it refers to anyone who contributes to the item.
Field | Type | Description |
|---|---|---|
|
| Primary key; automatically assigned. Required. |
|
| Last name of this author. Required. |
|
| First name of this author. Optional. |
|
| Middle name or initial of this author. Optional. |
|
| Name suffix, such as âJr.â Optional. |
|
| Year of birth. Use negative numbers for BC. Optional. |
|
| Year of death. Use negative numbers for BC. Optional. |
|
| Miscellaneous comments about this author. Optional. |
An author, editor, and so on, for a specific named item. This table establishes a many-to-many relationship between the NamedItem and Author tables.
Field | Type | Description |
|---|---|---|
|
| Primary key. The associated named item. Foreign reference to |
|
| Primary key. The author associated with the named item. Foreign reference to |
|
| Relative order of this author among the authors for this named item. Authors with smaller numbers appear first. Required. |
|
| The specific type of contribution given by this author for this named item. Foreign reference to |
Custom words that can be applied to named items to make searching easier.
Field | Type | Description |
|---|---|---|
|
| Primary key; automatically assigned. Required. |
|
| Name of this keyword. Required. |
Connects a keyword with a named item through a many-to-many relationship between the NamedItem and Keyword tables.
Field | Type | Description |
|---|---|---|
|
| Primary key. The associated named item. Foreign reference to |
|
| Primary key. The keyword to associate with the named item. Foreign reference to |
Subject headings used to classify named items.
Field | Type | Description |
|---|---|---|
|
| Primary key; automatically assigned. Required. |
|
| Name of this subject. Required. |
Connects a subject with a named item through a many-to-many relationship between the NamedItem and Subject tables.
Field | Type | Description |
|---|---|---|
|
| Primary key. The associated named item. Foreign reference to |
|
| Primary key. The subject to associate with the named item. Foreign reference to |
The tables in this section define the actual patron records and their relationship to item copies (when such copies are checked out by the patron).
An identified library user. Patrons usually have checkout privileges.
Field | Type | Description |
|---|---|---|
|
| Primary key; automatically assigned. Required. |
|
| Last name of this patron. Required. |
|
| First name of this patron. Required. |
|
| Date of last checkout, renewal, or return. Optional. |
|
| Is this an active patron? |
|
| Any comments associated with this patron. Optional. |
|
| Comments that are displayed to administrative users when the patronâs record is accessed. Optional. |
|
| Bar code found on this patronâs library card. At this time, only numeric bar codes are supported. Optional. |
|
| Patronâs password, in an encrypted format. Required. |
|
| Patronâs email address. Optional. |
|
| Patronâs phone number. Optional. |
|
| Patronâs street address. Optional. |
|
| Patronâs city. Optional. |
|
| Patronâs state abbreviation. Optional. |
|
| Patronâs postal code. Optional. |
|
| The group in which this patron appears. Foreign reference to |
This table manages item copies currently checked out by a patron, or item copies that were previously checked out and have since been returned.
Field | Type | Description |
|---|---|---|
|
| Primary key; automatically assigned. Required. |
|
| The associated patron. Foreign reference to |
|
| The item copy currently or previously checked out by the patron. Foreign reference to |
|
| The date when this item copy was initially checked out. Required. |
|
| The number of times this item copy has been renewed. Set to |
|
| Current due date for this item copy. Required. |
|
| The date when this item copy was returned. Optional. |
|
| Has the item copy been returned? |
|
| Is the item copy missing and considered lost? |
|
| Total fine accumulated for this item copy. Defaults to |
|
| Total amount paid (in fees) for this item copy. Required. |
|
| When an item copy is processed for overdue fines, this field contains the last date for which processing was done. Optional. |
Fines, payments, and dismissals on a patron copy record. Overdue fines are not recorded in this table, but administrator-initiated fines due to charges for missing items are recorded here.
Field | Type | Description |
|---|---|---|
|
| Primary key; automatically assigned. Required. |
|
| The associated item checked out by the patron. Foreign reference to |
|
| Date and time when this entry was recorded. Required. |
|
| The type of payment entry. Required. The possible values are:
|
|
| The amount associated with this entry. The value is always positive. Required. |
|
| A short comment about this entry. Optional. |
|
| The user who added this payment event. Foreign reference to |
There are three levels of definition to create a bar code: (1) the sheet on which a grid of labels prints; (2) a single label on the sheet; and (3) the individual items that appear on each label. The three tables in this section define those three levels.
Describes the template for a single page of bar code labels.
Field | Type | Description |
|---|---|---|
|
| Primary key; automatically assigned. Required. |
|
| Name of this sheet template. Required. |
|
| Units used in the various measurements found in most fields in this record. Required.
|
|
| Width of the entire page. Required. |
|
| Height of the entire page. Required. |
|
| Left border, up to the edge of the printable label area. Required. |
|
| Right border, up to the edge of the printable label area. Required. |
|
| Top border, up to the edge of the printable label area. Required. |
|
| Bottom border, up to the edge of the printable label area. Required. |
|
| The width of the blank area between label columns. Required. |
|
| The height of the blank area between label rows. Required. |
|
| The number of label columns on this template. Required. |
|
| The number of label rows on this template. Required. |
Describes the template for a single label on a bar code sheet. Any number of labels may be on a single sheet, but they all have the same shape and format.
Field | Type | Description |
|---|---|---|
|
| Primary key; automatically assigned. Required. |
|
| Name of this label template. Required. |
|
| The sheet template on which this label template appears. Foreign reference to |
|
| Units used in the various measurements found in most fields in this record. Required.
|
Describes a single item as found on a bar code label. Items include static and generated text, lines, rectangles, and generated bar codes.
Field | Type | Description |
|---|---|---|
|
| Primary key; automatically assigned. Required. |
|
| Identifies the order in which items on the label are printed. Lower numbers are printed first. Required. |
|
| The label template on which this item appears. Foreign reference to |
|
| What type of item does this record represent? Required.
|
|
| Left edge of the item relative to the left edge of the label. Measured according to the related |
|
| Top edge of the item relative to the top edge of the label. Measured according to the related |
|
| Width of the item, or of the box in which the item is drawn. For lines, this is the x coordinate of the endpoint. Measured according to the related |
|
| Height of the item, or of the box in which the item is drawn. For lines, this is the y coordinate of the endpoint. Measured according to the related |
|
| Rotation angle, in degrees, of the box in which the item is drawn. Zero ( |
|
| The name of the font used to write the text. Valid only when |
|
| The size of the font used to write the text. Valid only when |
|
| The static text to display on the label. Valid only when |
|
| The style of the font text. May be any combination of the following four codes:
Leave this field |
|
| The main color of the text, bar code, or line. When printing a rectangle, this is the border color. If |
|
| The fill color when printing a rectangle. If |
|
| The alignment of the text within the bounding box. Valid only when
|
|
| The number of digits in which to pad the bar code number. Set to zero ( |
Two additional tables provide support for features not handled through other tables.
When checking out an item to a patron, the return date should not fall on a holiday (or any day that the library is closed) since the patron might not have a way to return the book on the day itâs due. This table defines one-time and recurring holidays.
Field | Type | Description |
|---|---|---|
|
| Primary key, automatically assigned. Required. |
|
| Name of this holiday. Not necessarily unique. Required. |
|
| The type of entry. Required. From the following list:
|
|
| Entry-type-specific detail. Required. Differs for each entry type. Entry type Detail value
|
This table stores miscellaneous enterprise-wide settings that apply to every workstation. Local workstation-specific settings are stored on each machine, not in the database.
Field | Type | Description |
|---|---|---|
|
| Primary key; automatically assigned. Required. |
|
| Name of this value. Required. |
|
| Information associated with this entry. Optional. |
The following system values are defined at this time. The name of the code appears in the ValueName field. The corresponding value appears in the ValueData field.
BarcodeCode39Is the specified bar code in âcode 39â or âcode 3 of 9â format? If so, an asterisk will be placed before and after the bar code number before it is printed on a label. Use a value of
0for False or any nonzero value for True (â1is preferred). If missing orNULL, False is assumed.BarcodeFontThe name of the font used to print bar codes. This font must be installed on any workstation that displays or prints bar codes. It is not needed to scan bar codes.
DatabaseVersionWhich structural version of the database is currently in use? Right now, it is set to â1,â and is reserved for future enhancement.
DefaultLocationCodeLocation.IDvalue for the location that is set as the default.FineGraceNumber of days that an item can be overdue without incurring a fine.
NextBarcodeItemThe next starting value to use when printing item bar codes.
NextBarcodeMiscThe next starting value to use when printing miscellaneous bar codes.
NextBarcodePatronThe next starting value to use when printing patron bar codes.
PatronCheckOutIndicates whether patrons can check out items without being logged in as an administrative user. Use a value of
0(zero) to indicate no checkout privileges, or any nonzero value to allow patron checkout (â1is preferred). If this value is missing or empty, patrons will not be allowed to check out items without administrator assistance.SearchLimitIndicates the maximum number of results returned in any search or lookup. If this value is missing or invalid, a default of
250is used. The allowed range is between 25 and 5,000, inclusive.TicketHeadingDisplay text to be printed at the top of checkout tickets. All lines are centered on the ticket. Include the vertical bar character (
|) to break the text into multiple lines.TicketFootingDisplay text to be printed at the bottom of checkout tickets. All lines are centered on the ticket. Include the vertical bar character (
|) to break the text into multiple lines.UseLCIndicates whether books are categorized by Dewey or Library of Congress (LC) call numbers. Use a value of
0(zero) to indicate Dewey, or any nonzero value for LC (â1is preferred). If this value is missing or empty, Dewey is assumed.
Adding the database to SQL Server is almost as easy as documenting it; in fact, it requires less typing. The CREATE TABLE statements are straightforward, and they all pretty much look the same. Iâm going to show only a few of them here. The Database Creation Script.sql file in this bookâs installation directory includes the full script content.
The instructions listed here are for SQL Server 2005 Management Studio Express. You can perform all of these tasks using SQL Server 2005 Management Studio, or even the command-line tools supplied with SQL Server, but the details of each step will vary. The same CREATE TABLE statements work with whichever tool you choose.
If you havenât done so already, install SQL Server 2005 Express Edition (or whichever version of the database you will be using). SQL Server 2005 Management Studio Express is a separate product from SQL Server itself, so you must install that as well.
Most of the tables in the Library Project are simple data tables with a single primary key. Their code is straightforward. The Author table is a good example.
CREATE TABLE Author ( ID bigint IDENTITY PRIMARY KEY, LastName varchar(50) NOT NULL, FirstName varchar(30) NULL, MiddleName varchar(30) NULL, Suffix varchar(10) NULL, BirthYear smallint NULL, DeathYear smallint NULL, Comments varchar(250) NULL );
The fields included in each CREATE TABLE statement appear as a comma-delimited list, all enclosed in parentheses. Each field includes either a NULL or a NOT NULL option that indicates whether NULL values may be used in that field. The PRIMARY KEY option automatically specifies NOT NULL.
Some statements create tables that link two other tables in a many-to-many relationship. One example is the GroupActivity table, which connects the GroupName table with the Activity table.
CREATE TABLE GroupActivity ( GroupID bigint NOT NULL, ActivityID bigint NOT NULL, PRIMARY KEY (GroupID, ActivityID) );
The Author table had a single primary key, so the PRIMARY KEY option could be attached directly to its ID field. Since the GroupActivity table has a two-field primary key (which is common in relational databases), the PRIMARY KEY option is specified as an entry all its own, with the key fields specified as a parentheses-enclosed comma-delimited list.
Earlier in this chapter, I showed how you could establish a reference to a field in another table by using the REFERENCES constraint as part of the CREATE TABLE statement. You can also establish them after the tables are already in place, as I do in the script. Here is the statement that establishes the link between the GroupActivity and GroupName tables:
ALTER TABLE GroupActivity ADD FOREIGN KEY (GroupID) REFERENCES GroupName (ID);
Since Iâve already written the entire SQL script for you, Iâll just have you process it directly using Microsoft SQL Server 2005 Management Studio Express. (If you will be using the full version of SQL Server or some other management tool, the provided script will still work, although the step-by-step instructions will differ.) Before adding the tables, we need to create a database specific to the Library Project. Start up Microsoft SQL Server 2005 Management Studio Express (see Figure 4-4).
To add a new database for the Library Project, right-click on the Database folder in the Object Explorer, and select New Database from the shortcut menu. On the New Database form that appears, enter Library in the Database Name field, and then click OK.
The Library database is a shell of a database; it doesnât contain any tables or data yet. Letâs use the Database Creation Script.sql file from the bookâs installation directory to generate the tables and initial data. In Management Studio Express, select the File â Open â File menu command, and locate the Database Creation Script.sql file. (You may be prompted to log in to SQL Server again.) Opening this file places its content in a new panel within Management Studio Express.
All thatâs left to do is to process the script. In the toolbar area, make sure that âLibraryâ is the selected database (see Figure 4-5). Then click the Execute toolbar button, or press the F5 key. Itâs a small script with not a lot going on (at least from SQL Serverâs point of view), so it should finish in just a few seconds.

Thatâs it! Close the script panel. Then, back in the Object Explorer, right-click on the Library database folder and select Refresh from the menu. If you then expand the Library database branch and its Tables sub-branch, you will see all the tables created by the script (see Figure 4-6).

With the database done, itâs time to start programming.
Get Programming Visual Basic 2008 now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

