Who says Pigs can’t fly? Knowing how to optimize your Pig Latin scripts can make a significant difference in how they perform. Pig is still a young project and does not have a sophisticated optimizer that can make the right choices. Instead, consistent with Pig’s philosophy of user choice, it relies on you to make these choices. Beyond just optimizing your scripts, Pig and MapReduce can be tuned to perform better based on your workload. And there are ways to optimize your data layout as well. This chapter covers a number of features you can use to help Pig fly.
Before diving into the details of how to optimize your Pig Latin, it is worth understanding what items tend to create bottlenecks in Pig jobs:
- Input size
It does not seem that a massively parallel system should be I/O bound. Hadoop’s parallelism reduces I/O bound but does not entirely remove it. You can always add more map tasks. However, the law of diminishing returns comes into effect. Additional maps take more time to start up, and MapReduce has to find more slots in which to run them. If you have twice as many maps as you have slots to run them, it will take twice your average map time to run all of your maps. Adding one more map in that case will actually make it worse because the map time will increase to three times the average. Also, every record that is read might need to be decompressed and will need to be deserialized.
- Shuffle size
By shuffle size I mean the data that is moved from your map tasks to your reduce tasks. All of this data has to be serialized, sorted, moved over the network, merged, and deserialized. Also, the number of maps and reduces matters. Every reducer has to go to every mapper, find the portion of the map’s output that belongs to it, and copy that. So if there are
mmaps andrreduces, the shuffle will havem x rnetwork connections. And if reducers have too many map inputs to merge in one pass, they will have to do a multipass merge, reading the data from and writing it to disk multiple times (see Combiner Phase for details).- Output size
Every record written out by a MapReduce job has to be serialized, possibly compressed, and written to the store. When the store is HDFS, it must be written to three separate machines before it is considered written.
- Intermediate results size
Pig moves data between MapReduce jobs by storing it in HDFS. Thus the size of these intermediate results is affected by the input size and output size factors mentioned previously.
- Memory
Some calculations require your job to hold a lot of information in memory, for example, joins. If Pig cannot hold all of the values in memory simultaneously, it will need to spill some to disk. This causes a significant slowdown, as records must be written to and read from disk, possibly multiple times.
There are a number of things you can do when writing Pig Latin scripts to help reduce the bottlenecks discussed earlier. It may be helpful to review which operators force new MapReduce jobs in Chapters 5 and 6.
Getting rid of data as quickly as possible will help your
script perform better. Pushing filters higher in your
script can reduce the amount of data you are shuffling or storing in
HDFS between MapReduce jobs. Pig’s logical optimizer will push your
filters up whenever it can. In cases where a
filter has multiple predicates joined by and,
and one or more of the predicates can be applied before the operator
preceding the filter, Pig will split the
filter at the and and push the eligible
predicate(s). This allows Pig to push parts of the filter
when it might not be able to push the filter as a whole.
Table 8-1 describes when these
filter predicates will and will not be pushed once they
have been split.
Table 8-1. When Pig pushes filters
Also, consider adding filters that
are implicit in your script. For example, all of the records with null
values in the key will be thrown out by an inner join. If
you know that more than a few hundred of your records have null key
values, put a filter input by key is not null before the
join. This will enhance the performance of your
join.
For earlier versions of Pig, we told users to
employ foreach to remove fields they were not using as soon
as possible. As of version 0.8, Pig’s logical optimizer does a fair job
of removing fields aggressively when it can tell that they will no
longer be used:
-- itemid does not need to be loaded, since it is not used in the script txns = load 'purchases' as (date, storeid, amount, itemid); todays = filter txns by date == '20110513'; -- date not needed after this bystore = group todays by storeid; avgperstore = foreach bystore generate group, AVG(todays.amount);
However, you are still smarter than Pig’s
optimizer, so there are situations where you can tell that a field is no
longer needed but Pig cannot. If AVG(todays.amount) were
changed to COUNT(todays) in the preceding example, Pig
would not be able to determine that, after the
filter, only storeid and amount were required. It cannot see that
COUNT does not need all of the fields in the bag it is
being passed. Whenever you pass a UDF the entire record (udf(*)) or an entire complex field, Pig cannot
determine which fields are required. In this case, you will need to put
in the foreach yourself to remove unneeded data as early as
possible.
Joins are one of the most common data operations, and also one of the costliest. Choosing the correct join implementation can improve your performance significantly. The flowchart in Figure 8-1 will help you make the correct selection.
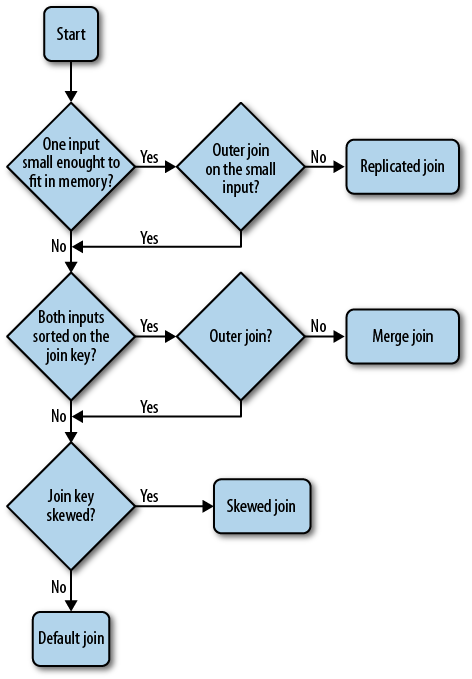
Once you have selected your join implementation,
make sure to arrange your inputs in the correct order as well. For
replicated joins, the small table must be given as the last input. For
skewed joins, the second input is the one that is sampled
for large keys. For the default join, the rightmost input has its
records streamed through, whereas the other input(s) have their records
for a given key value materialized in memory. Thus if you have one join
input that you know has more records per key value, you should place it
in the rightmost position in the join. For merge join, the left input is taken as the input for the
MapReduce job, and thus the number of maps started are based on this
input. If one input is much larger than the other, you should place it
on the left in order to get more map tasks dedicated to your jobs. This
will also reduce the size of the sampling step that builds the index for
the right side. For complete details on each of these join
implementations, see the sections Join and
Using Different Join Implementations.
Whenever you are doing operations that can be combined by multiquery, such as grouping and filtering, these should be written together in one Pig Latin script so that Pig can combine them. Although adding extra operations does increase the total processing time, it is still much faster than running jobs separately.
As discussed elsewhere, Pig can run with or without data
type information. In cases where the load function you are using creates
data that is already typed, there is little you need to do to optimize
the performance. However, if you are using the default
PigStorage load function that reads tab-delimited files, then whether you use types will
affect your performance.
On the one hand, converting fields from
bytearray to the appropriate type has a cost.
So, if you do not need type information, you should not declare it. For example, if you are just counting
records, you can omit the type declaration without affecting the outcome
of your script.
On the other hand, if you are doing integer
calculations, types can help your script perform better. When Pig is
asked to do a numeric calculation on a bytearray, it treats
that bytearray as a double because this is the safest
assumption. But floating-point arithmetic is much slower than integer
arithmetic on most machines. For example, if you are doing a
SUM over integer values, you will get better performance by
declaring them to be of type integer.
Setting your parallelism properly can be difficult, as there are a number of factors. Before we discuss the factors, a little background will be helpful. It would be natural to think more parallelism is always better; however, that is not the case. Like any other resource, parallelism has a network cost, as discussed under the shuffle size performance bottleneck.
Second, increasing parallelism adds latency to
your script because there is a limited number of reduce slots in your
cluster, or a limited number that your scheduler will assign to you. If
100 reduce slots are available to you and you specify parallel
200, you still will be able to run only 100 reduces at a time.
Your reducers will run in two separate waves. Because there is
overhead in starting and stopping reduce tasks, and the shuffle gets
less efficient as parallelism increases, it is often not efficient to
select more reducers than you have slots to run them. In fact, it is
best to specify slightly fewer reducers than the number of slots that
you can access. This leaves room for MapReduce to restart a few failed
reducers and use speculative execution without doubling your reduce time.
See Handling Failure for information on
speculative execution.
Also, it is important to keep in mind the
effects of skew on parallelism. MapReduce generally does a good job
partitioning keys equally to the reducers, but the
number of records per key often varies radically. Thus a few reducers
that get keys with a large number of records will significantly lag the
other reducers. Pig cannot start the next MapReduce job until all of the
reducers have finished in the previous job. So the slowest reducer
defines the length of the job. If you have 10G of input to your reducers
and you set parallel to 10, but one key accounts for
50% of the data (not an uncommon case), nine of your reducers will
finish quite quickly while the last lags. Increasing your parallelism
will not help; it will just waste more cluster resources. Instead, you
need to use Pig’s mechanisms to handle skew.
Pig has a couple of features intended to enable aggregate
functions to run significantly faster. The
Algebraic interface allows UDFs to use Hadoop’s
combiner (see Combiner Phase). The
Accumulator interface allows Pig to break a
collection of records into several sets and give each set to the UDF
separately. This avoids the need to materialize all of the records
simultaneously, and thus spill to disk when there are too many records.
For details on how to use these interfaces, see Algebraic Interface and Accumulator Interface. Whenever possible, you should write
your aggregate UDFs to make use of these features.
Pig also has optimizations to help loaders minimize the amount of data they load. Pig can tell a loader which fields it needs and which keys in a map it needs. It can also push down certain types of filters. For information on this, see Pushing down projections and Loading metadata.
On your way out of a commercial jet airliner, have you ever peeked around the flight attendant to gaze at all the dials, switches, and levers in the cockpit? This is sort of what tuning Hadoop is like: many, many options, some of which make an important difference. But without the proper skills, it can be hard to know which is the right knob to turn. Table 8-2 looks at a few of the important features.
Note
This table is taken from Tables 6-1 and 6-2 in Hadoop: The Definitive Guide, Second Edition, by Tom White (O’Reilly), used with permission. See those tables for a more complete list of parameters.
Table 8-2. MapReduce performance-tuning properties
Compared to Hadoop, tuning Pig is much simpler. There are a couple of memory-related parameters that will help ensure Pig uses its memory in the best way possible. These parameters are covered in Table 8-3.
Table 8-3. Pig performance-tuning properties
All of these values for Pig and MapReduce can be
set using the set option in your Pig Latin script (see set) or by passing them with -D on the command line.
As is probably clear by now, some of the biggest costs in Pig are moving data between map and reduce phases and between MapReduce jobs. Compression can be used to reduce the amount of data to be stored to disk and written over the network. By default, compression is turned off, both between map and reduce tasks and between MapReduce jobs.
To enable compression between map and reduce
tasks, two Hadoop parameters are used: mapred.compress.map.output and mapred.map.output.compression.codec. To turn on
compression, set mapred.compress.map.output to true. You will also need to select a compression
type to use. The most commonly used types are gzip and LZO. gzip is more CPU-intensive but compresses better. To
use gzip, set mapred.map.output.compression.codec to org.apache.hadoop.io.compress.GzipCodec. In most
cases, LZO provides a better performance boost. See the sidebar Setting Up LZO on Your Cluster for details. To use LZO as your codec, set
mapred.map.output.compression.codec to
com.hadoop.compression.lzo.LzopCodec.
Compressing data between MapReduce jobs can also
have a significant impact on Pig performance. This is particularly true of
Pig scripts that include joins or other operators that expand your data
size. To turn on compression, set pig.tmpfilecompression to true. Again, you can choose between gzip and LZO
by setting pig.tmpfilecompression.codec
to gzip or lzo, respectively. In the testing we did while
developing this feature, we saw performance improvements of up to four
times when using LZO, and slight performance degradation when using
gzip.
How you lay out your data can have a significant impact on how your Pig jobs perform. On the one hand, you want to organize your files such that Pig can scan the minimal set of records. For example, if you have regularly collected data that you usually read on an hourly basis, it likely makes sense to place each hour’s data in a separate file. On the other hand, the more files you create, the more pressure you put on your NameNode. And MapReduce operates more efficiently on larger files than it does on files that are less than one HDFS block (64 MB by default). You will need to find a balance between these two competing forces.
Beginning in 0.8, when your inputs are files and they are
smaller than half an HDFS block, Pig will automatically combine the
smaller sections when using the file as input. This allows MapReduce to be
more efficient and start fewer map tasks. This is almost always better for
your cluster utilization. It is not always better for the performance of
your individual query, however, because you will be losing locality of
data reads for many of the combined blocks, and your map tasks may run
longer. If you need to turn this feature off, pass -Dpig.noSplitCombination=true on your command
line or set the property in your pig.properties file.
When processing gigabytes or terabytes of data, the odds are
overwhelming that at least one row is corrupt or will cause an unexpected
result. An example is division by zero, even though no records were
supposed to have a zero in the denominator. Causing an entire job to fail
over one bad record is not good. To avoid these failures, Pig inserts a
null, issues a warning, and continues processing. This way, the job still
finishes. Warnings are aggregated and reported as a count at the end. You
should check the warnings to be sure that the failure of a few records is
acceptable in your job. If you need to know more details about the
warnings, you can turn off the aggregation by passing
-w on the command line.
Get Programming Pig now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

