Chapter 1. Practical Machine Learning
A key to one of most sophisticated and effective approaches in machine learning and recommendation is contained in the observation: “I want a pony.” As it turns out, building a simple but powerful recommender is much easier than most people think, and wanting a pony is part of the key.
Machine learning, especially at the scale of huge datasets, can be a daunting task. There is a dizzying array of algorithms from which to choose, and just making the choice between them presupposes that you have sufficiently advanced mathematical background to understand the alternatives and make a rational choice. The options are also changing, evolving constantly as a result of the work of some very bright, very dedicated researchers who are continually refining existing algorithms and coming up with new ones.
What’s a Person To Do?
The good news is that there’s a new trend in machine learning and particularly in recommendation: very simple approaches are proving to be very effective in real-world settings. Machine learning is moving from the research arena into the pragmatic world of business. In that world, time to reflect is very expensive, and companies generally can’t afford to have systems that require armies of PhDs to run them. Practical machine learning weighs the trade-offs between the most advanced and accurate modeling techniques and the costs in real-world terms: what approaches give the best results in a cost-benefit sense?
Let’s focus just on recommendation. As you look around, it’s obvious that some very large companies have for some years put machine learning into use at large scale (see Figure 1-1).
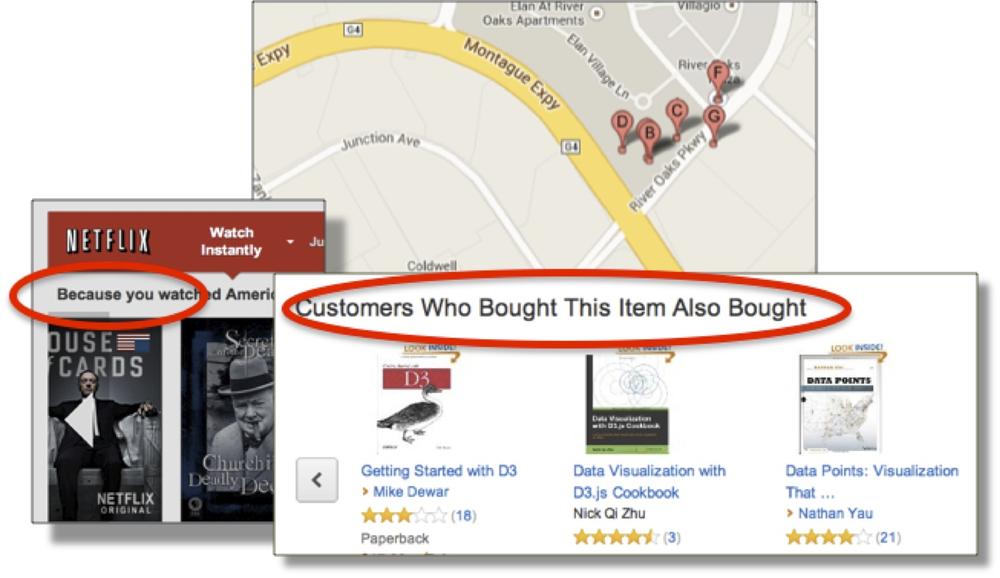
As you order items from Amazon, a section lower on the screen suggests other items that might be of interest, whether it be O’Reilly books, toys, or collectible ceramics. The items suggested for you are based on items you’ve viewed or purchased previously. Similarly, your video-viewing choices on Netflix influence the videos suggested to you for future viewing. Even Google Maps adjusts what you see depending on what you request; for example, if you search for a tech company in a map of Silicon Valley, you’ll see that company and other tech companies in the area. If you search in that same area for the location of a restaurant, other restaurants are now marked in the area. (And maybe searching for a big data meetup should give you technology companies plus pizza places.)
But what does machine learning recommendation look like under the covers? Figure 1-2 shows the basics.
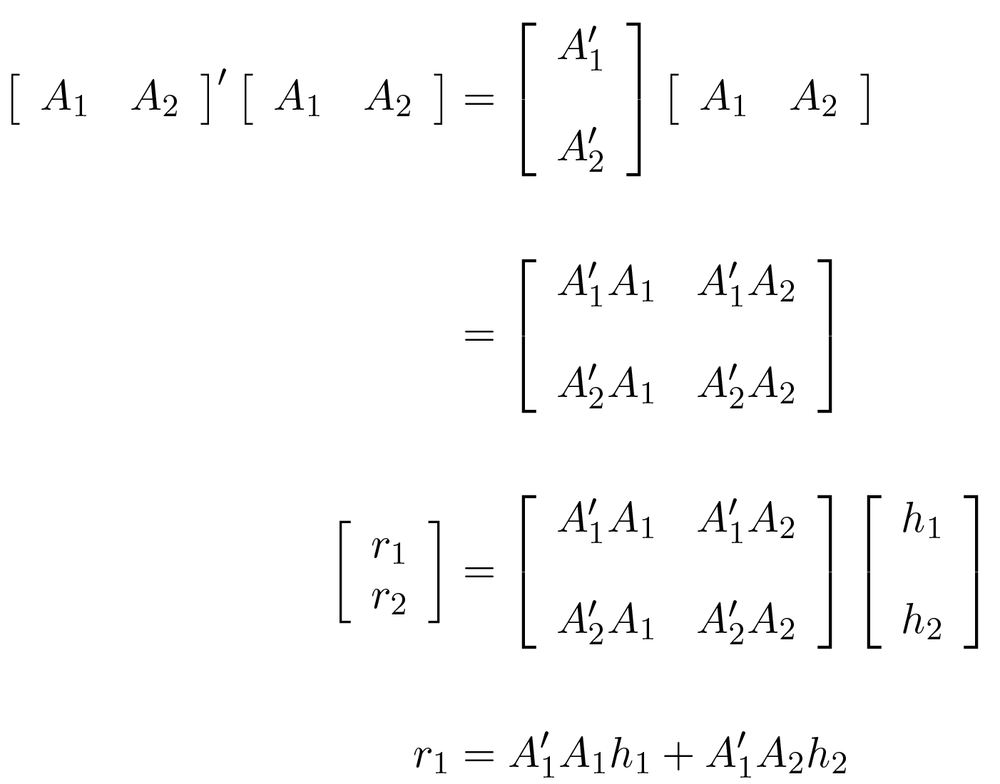
If you love matrix algebra, this figure is probably a form of comfort food. If not, you may be among the majority of people looking for solutions to machine-learning problems who want something more approachable. As it turns out, there are some innovations in recommendation that make it much easier and more powerful for people at all levels of expertise.
There are a few ways to deal with the challenge of designing recommendation engines. One is to have your own team of engineers and data scientists, all highly trained in machine learning, to custom design recommenders to meet your needs. Big companies such as Google, Twitter, and Yahoo! are able to take that approach, with some very valuable results.
Other companies, typically smaller ones or startups, hope for success with products that offer drag-and-drop approaches that simply require them to supply a data source, click on an algorithm, and look for easily understandable results to pop out via nice visualization tools. There are lots of new companies trying to design such semiautomated products, and given the widespread desire for a turnkey solution, many of these new products are likely to be financially successful. But designing really effective recommendation systems requires some careful thinking, especially about the choice of data and how it is handled. This is true even if you have a fairly automated way of selecting and applying an algorithm. Getting a recommendation model to run is one thing; getting it to provide effective recommendations is quite a lot of work. Surprisingly to some, the fancy math and algorithms are only a small part of that effort. Most of the effort required to build a good recommendation system is put into getting the right data to the recommendation engine in the first place.
If you can afford it, a different way to get a recommendation system is to use the services of a high-end machine-learning consultancy. Some of these companies have the technical expertise necessary to supply stunningly fast and effective models, including recommenders. One way they achieve these results is by throwing a huge collection of algorithms at each problem, and—based on extensive experience in analyzing such situations—selecting the algorithm that gives the best outcome. SkyTree is an example of this type of company, with its growing track record of effective machine learning models built to order for each customer.
Making Recommendation Approachable
A final approach is to do it yourself, even if you or your company lack access to a team of data scientists. In the past, this hands-on approach would have been a poor option for small teams. Now, with new developments in algorithms and architecture, small-scale development teams can build large-scale projects. As machine learning becomes more practical and approachable, and with some of the innovations and suggestions in this paper, the self-built recommendation engine becomes much easier and effective than you may think.
Why is this happening? Resources for Apache Hadoop–based computing are evolving and rapidly spreading, making projects with very large-scale datasets much more approachable and affordable. And the ability to collect and save more data from web logs, sensor data, social media, etc., means that the size and number of large datasets is also growing.
How is this happening? Making recommendation practical depends in part on making it simple. But not just any simplification will do, as explained in Chapter 2.
Get Practical Machine Learning: Innovations in Recommendation now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

