The Network architecture comprises of an encoder network, which is a typical convolutional pyramid. Each convolutional layer is followed by a max-pooling layer; this reduces the dimensions of the layers.
The decoder converts the input from a sparse representation to a wide reconstructed image. A schematic of the network is shown here:
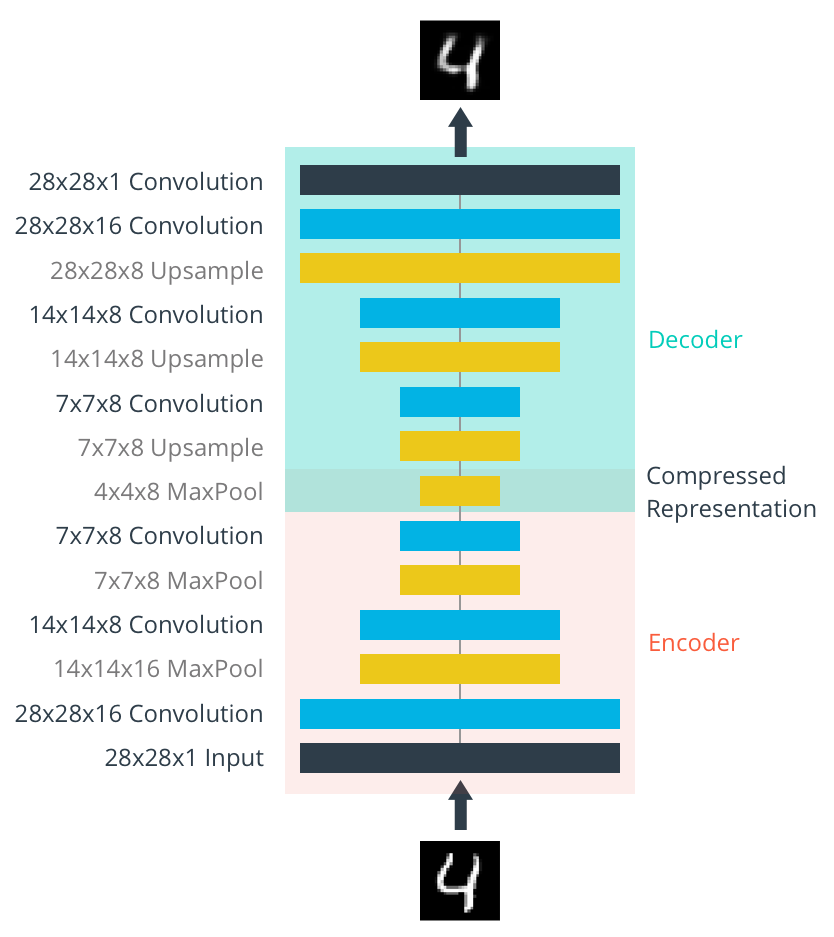
The encoder layer output image size is 4 x 4 x 8 = 128. The original image size was 28 x 28 x 1 = 784, so the compressed image vector is roughly 16% of the size of the original image.
Usually, you'll see transposed convolution layers used to increase the width and height of the layers. ...

