Chapter 1. The Basics
In this chapter, we’ll get you started with PostgreSQL. We begin by pointing you to resources for downloading and installing it. Next we provide an overview of indispensable administration tools and review PostgreSQL nomenclature. At the time of writing, PostgreSQL 9.4 is awaiting release, and we’ll highlight some of the new features you’ll find in it. We close the chapter with resources to turn to when you need help.
Where to Get PostgreSQL
Years ago, if you wanted PostgreSQL, you had to compile it from source. Thankfully, those days are long gone. Granted, you can still compile the source if you so choose, but most users nowadays use packaged installers. A few clicks or keystrokes, and you’re on your way.
If you’re installing PostgreSQL for the first time and have no existing database to upgrade, you should install the latest stable release version for your OS. The downloads page for the PostgreSQL Core Distribution maintains a listing of places where you can download PostgreSQL binaries for various OSes. In Appendix A, you’ll find useful installation instructions and links to additional custom distributions.
Administration Tools
There are four tools we commonly use to manage and use PostgreSQL: psql, pgAdmin, phpPgAdmin, and Adminer. PostgreSQL core developers actively maintain the first three; therefore, they tend to stay in sync with PostgreSQL releases. Adminer, while not specific to PostgreSQL, is useful if you also need to manage other relational databases: SQLite, MySQL, SQL Server, or Oracle. Beyond the four that we cover, you can find plenty of other excellent administration tools, both open source and proprietary.
psql
psql is a command-line interface for running queries. It is included in all distributions of PostgreSQL. psql has some unusual features, such as an import and export command for delimited files (CSV or tab), and a minimalistic report writer that can generate HTML output. psql has been around since the beginning of PostgreSQL and is the tool of choice for many expert users, for people working in consoles without a GUI, or for running common tasks in shell scripts. Newer converts favor GUI tools and wonder why the older generation still clings to the command line.
pgAdmin
pgAdmin is a widely used free GUI tool for PostgreSQL. You can download it separately from PostgreSQL if it isn’t already packaged with your installer.
pgAdmin runs on the desktop and can connect to multiple PostgreSQL servers regardless of version or OS.
Even if your database lives on a console-only Linux server, go ahead and install pgAdmin on your workstation, and you’ll find yourself armed with a fantastic GUI tool.
An example of pgAdmin appears in Figure 1-1.
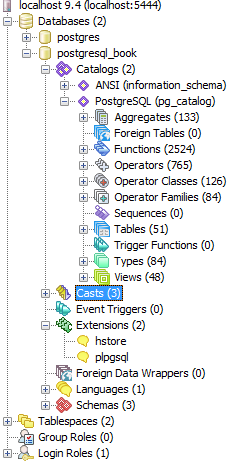
If you’re unfamiliar with PostgreSQL, you should definitely start with pgAdmin. You’ll get a bird’s-eye view and appreciate the richness of PostgreSQL just by exploring everything you see in the main interface. If you’re deserting from the SQL Server camp and are accustomed to Management Studio, you’ll feel right at home.
phpPgAdmin
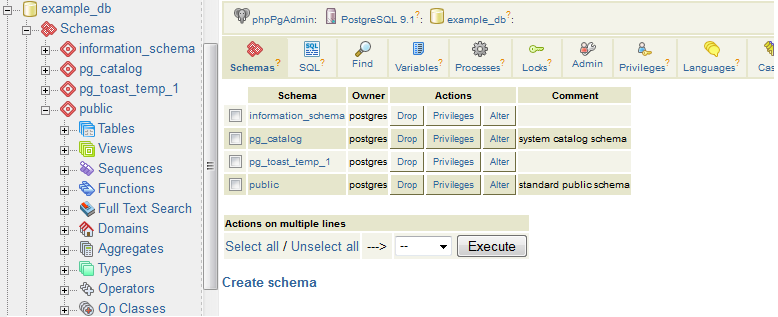
phpPgAdmin, pictured in Figure 1-2, is a free, web-based administration tool patterned after the popular phpPgMyAdmin from phpMyAdmin. PostgreSQL differs from phpPgAdmin by including additions to manage schemas, procedural languages, casts, operators, and so on. If you’ve used phpMyAdmin, you’ll find phpPgAdmin to have the same look and feel.
Adminer
If you manage other databases besides PostgreSQL and are looking for a unified tool, Adminer might fit the bill. Adminer is a lightweight, open source PHP application with options for PostgreSQL, MySQL, SQLite, SQL Server, and Oracle, all delivered through a single interface.
One unique feature of Adminer we’re impressed with is the relational diagrammer that can produce a graphical layout of your database schema, along with a linear representation of foreign key relationships. Another hassle-reducing feature is that you can deploy Adminer as a single PHP file.
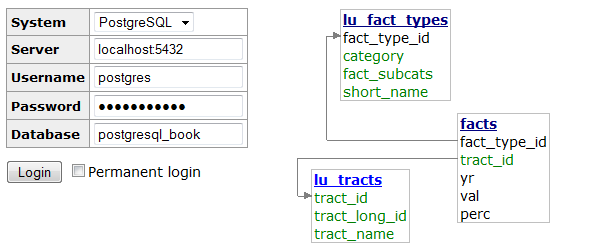
Figure 1-3 is a screenshot of the login screen and a snippet from the diagrammer output. Many users stumble in the login screen of Adminer because it doesn’t include a separate text box for indicating the port number. If PostgreSQL is listening on the standard 5432 port, you need not worry. But if you use some other port, append the port number to the server name with a colon, as shown in Figure 1-3.
Adminer is sufficient for straightforward querying and editing, but because it’s tailored to the lowest common denominator among database products, you won’t find management applets that are specific to PostgreSQL for such tasks as creating new users, granting rights, or displaying permissions. If you’re a DBA, stick to pgAdmin but make Adminer available.
PostgreSQL Database Objects
So you installed PostgreSQL, fired up pgAdmin, and expanded its browse tree. Before you is a bewildering display of database objects, some familiar and some completely foreign. PostgreSQL has more database objects than most other relational database products (and that’s before add-ons). You’ll probably never touch many of these objects, but if you dream up something new, more likely than not it’s already implemented using one of those esoteric objects. This book is not even going to attempt to describe all that you’ll find in a standard PostgreSQL install. With PostgreSQL churning out features at breakneck speed, we can’t imagine any book that could possibly do this. We’ll limit our discussion to those objects that you should be familiar with:
servicePostgreSQL installs as a service (daemon) on most OSes. More than one service can run on a physical server as long as they listen on different ports and don’t share data storage. In this book, we use the terms server and service interchangeably, because most people stick to one service per physical server.
databaseschemaSchemas are part of the ANSI SQL standard. They are the immediate next level of organization within each database. If you think of the database as a country, schemas would be the individual states (or provinces, prefectures, or departments, depending on the country.) Most database objects first belong in a schema, which belongs in a database. PostgreSQL automatically creates a schema named
publicwhen you create a new database. PostgreSQL puts everything you create intopublicby default unless you change thesearch_pathof the database (discussed in an upcoming item). If you have just a few tables, this is fine. But if you have thousands of tables, you’ll need to put them in different schemas.catalogCatalogs are system schemas that store PostgreSQL built-in functions and meta-data. Each database is born containing two catalogs:
pg_catalog, which has all the functions, tables, system views, casts, and types packaged with PostgreSQL; andinformation_schema, which consists of ANSI standard views that expose PostgreSQL metainformation in a format dictated by the ANSI SQL standard.PostgreSQL practices what it preaches. You will find that PostgreSQL itself is built atop a self-replicating structure. All settings to fine-tune servers are kept in system tables that you’re free to query and modify. This gives PostgreSQL a level of flexibility (or hackability) impossible to attain by proprietary database products. Go ahead and take a close look inside the
pg_catalogschema. You’ll get a sense of how PostgreSQL is put together. If you have superuser privileges, you have the right to make updates to the schema directly (and to screw up your installation royally).The
information_schemacatalog is one you’ll also find in MySQL and SQL Server. The most commonly used views in the PostgreSQLinformation_schemaarecolumns, which lists all table columns in a database;tables, which lists all tables (including views) in a database; andviews, which lists all views and the associated SQL to build rebuild the view. Again, you will also find these views in MySQL and SQL Server, with a subset of columns that PostgreSQL has. PostgreSQL adds a couple more columns, such ascolumns.udt_name,to describe custom data type columns.Although
columns,tables, andviewsare all implemented as PostgreSQL views, pgAdmin shows them in an information_schema→Catalog Objects branch.variablePart of what PostgreSQL calls the Grand Unified Configuration (GUC), variables are various options that can be set at the service level, database level, and other levels. One option that trips up a lot of people is
search_path, which controls which schema assets don’t need to be prefixed with the schema name to be used. We discusssearch_pathin greater detail in Using Schemas.extensionIntroduced in PostgreSQL 9.1, this feature allows developers to package functions, data types, casts, custom index types, tables, GUCs, etc. for installation or removal as a unit. Extensions are similar in concept to Oracle packages and are the preferred method for distributing add-ons. You should follow the developer’s instructions on how to install the extension files onto your server. This usually involves installing the extension binaries and scripts. Once done, you must enable the extension for each database separately.
You don’t need to enable every extension you use in all databases. For example, if you need advanced text search in only one of your databases, enable
fuzzystrmatchjust for that database. When you add extensions, you have a choice of the schemas they will go in. If you take the default, extension objects will litter thepublicschema. This could make that schema unwieldy, especially if you store your own database objects in there. We recommend that you create a separate schema that will house all extensions and even create a separate schema to hold each large extension. Include the new schemas in thesearch_pathvariable of the database so you can use the functions without specifying which schema they’re in. Some extensions dictate which schema they should be installed in. For those, you won’t be able to change the schema. For example, many language extensions, such as plv8, must be installed inpg_catalog.tableTables are the workhorses of any database. In PostgreSQL, tables are first of all citizens of their respective schemas, before being citizens of the database.
PostgreSQL tables have two remarkable talents. First, they recognize parents and children. This hierarchy streamlines your database design and can save you endless lines of looping code when querying similar tables. We cover inheritance in Example 6-2.
Second, creating a table automatically results in the creation of an accompanying custom data type. In other words, you can define a complete data structure as a table and then use it as a column in another table. See Custom and Composite Data Types for a thorough discussion of composite types.
foreign tableandforeign data wrapperForeign tables showed their faces in version 9.1. These are virtual tables linked to data outside a PostgreSQL database. Once you’ve configured the link, you can query them like any other tables. Foreign tables can link to CSV files, a PostgreSQL table on another server, a table in a different product such as SQL Server or Oracle, a NoSQL database such as Redis, or even a web service such as Twitter or Salesforce. Configuring foreign tables is done through foreign data wrappers (FDWs). FDWs contain the magic handshake between PostgreSQL and external data sources. Their implementation follows the standards decreed in SQL/Management of External Data (MED).
Many programmers have already developed FDWs for popular data sources that they freely share. You can try your hand at creating your own FDWs as well. (Be sure to publicize your success so the community can reap the fruits of your toil.) Install FDWs using the extension framework. Once they’re installed, pgAdmin will show them listed under a node called Foreign Data Wrappers.
tablespaceA tablespace is the physical location where data is stored. PostgreSQL allows tablespaces to be independently managed, so you can easily move databases or even single tables and indexes to different drives.
viewMost relational database products offer views for abstracting queries and allow for updating data via a view. PostgreSQL offers the same features and allows for auto-updatable single-table views in versions 9.3 and later that don’t require any extra writing of rules or triggers to make them updatable. For more complex logic or views involving more than one table, you still need triggers or rules to make the view updatable. Version 9.3 introduced materialized views, which cache data to speed up commonly used queries. See Materialized Views.
functionFunctions in PostgreSQL can return a scalar value or sets of records. You can also write functions to manipulate data; when functions are used in this fashion, other database engines call them stored procedures.
languageFunctions are created in procedural languages (PLs). Out of the box, PostgreSQL supports three: SQL, PL/pgSQL, and C. You can install additional languages using the
CREATE EXTENSIONorCREATE PRODCEDURAL LANGUAGEcommands. Languages currently in vogue are Python, JavaScript, Perl, and R. You’ll see plenty of examples in Chapter 8.operatorOperators are symbolic, named functions (e.g.,
=,&&) that take one or two arguments and that have the backing of a function. In PostgreSQL, you can invent your own. When you define a custom type, you can also define operators that work with that custom type. For example, you can define the=operator for your type. You can even define an operator with operands of two disparate types.data type(or justtype)Every database product has a set of data types that it works with: integers, characters, arrays, etc. PostgreSQL has something called a composite type, which is a type that has attributes from other types. Imaginary numbers, polar coordinates, and tensors are examples of composite types. If you define your own type, you can define new functions and operators to work with the type:
div,grad, andcurls, anyone?castCasts are prescriptions for converting from one data type to another. They are backed by functions that actually perform the conversion. What is rare about PostgreSQL is the ability to create your own casts and thus change the default behavior of casting. For example, imagine you’re converting zip codes (which in the United States are five digits long) to
characterfrominteger. You can define a custom cast that automatically prepends a zero when the zip is between 1000 and 9999. Casting can be implicit or explicit. Implicit casts are automatic and usually expand from a more specific to a more generic type. When an implicit cast is not offered, you must cast explicitly.sequenceA sequence controls the autoincrementation of a serial data type. PostgresSQL automatically creates sequences when you define a serial column, but you can easily change the initial value, increment, and next value. Because sequences are objects in their own right, more than one table can use the same sequence object. This allows you to create a unique key value that can span tables. Both SQL Server and Oracle have sequence objects, but you must create them manually.
roworrecordWe use the terms rows and records interchangeably. In PostgreSQL, rows can be treated independently from their respective tables. This distinction becomes apparent and useful when you write functions or use the row constructor in SQL.
triggerYou will find triggers in most enterprise-level databases; triggers detect data-change events. When PostgreSQL fires a trigger, you have the opportunity to execute trigger functions in response. A trigger can run in response to particular types of statements or in response to changes to particular rows, and can fire before or after a data-change event.
Trigger technology is evolving rapidly in PostgreSQL. Starting in version 9.0, a
WITHclause lets you specify a BooleanWHENcondition, which is tested to see whether the trigger should be fired. Version 9.0 also introduced theUPDATE OFclause, which allows you to specify which column(s) to monitor for changes. When the column changes, the trigger is fired, as demonstrated in Example 8-11. In version 9.1, a data change in a view can fire a trigger. In version 9.3, data definition language (DDL) events can fire triggers. The DDL events that can fire triggers are listed in the Event Trigger Firing Matrix. In version 9.4, triggers for foreign tables were introduced. See CREATE TRIGGER for more details about these options.ruleRules are instructions to substitute one action for another. PostgreSQL uses rules internally to define views. As an example, you could create a view as follows:
CREATEVIEWvw_pupilsASSELECT*FROMpupilsWHEREactive;Behind the scenes, PostgresSQL adds an
INSTEAD OF SELECTrule dictating that when you try to select from a table calledvw_pupils, you will get back only rows from thepupilstable in which theactivefield istrue.A rule is also useful in lieu of certain simple triggers. Normally a trigger is called for each record in your update/insert/delete statement. A rule, instead, rewrites the action (your SQL statement) or inserts additional SQL statements on top of your original. This avoids the overhead of touching each record separately. For changing data, triggers are the preferred method of operation. Many PostgreSQL users consider rules to be legacy technology for action-based queries because they are much harder to debug when things go wrong, and you can write rules only in SQL, not in any of the other PLs.
What’s New in Latest Versions of PostgreSQL?
The PostgreSQL release cycle is fairly predictable, with major releases slated for each September. Each new version adds enhancements to ease of use, stability, security, performance, and avant-garde features. The upgrade process gets simpler with each new version. The lesson here? Upgrade, and upgrade often. For a summary chart of key features added in each release, check the PostgreSQL Feature Matrix.
Why Upgrade?
If you’re using PostgreSQL 8.4 or below, upgrade now! Version 8.4 entered end-of-life (EOL) support in July 2014. Details about PostgreSQL EOL policy can be found at the PostgreSQL Release Support Policy. EOL is not a place you want to be. New security updates and fixes to serious bugs will no longer be available. You’ll need to hire specialized PostgreSQL core consultants to patch problems or to implement workarounds—probably not a cheap proposition, assuming you can even locate someone willing to do the work.
Regardless of which major version you are running, you should always try to keep up with the latest micro versions. An upgrade from, say, 8.4.17 to 8.4.21, requires just binary file replacement and a restart. Micro versions only patch bugs. Nothing will stop working after a micro upgrade, and performing a micro upgrade can in fact save you grief.
What’s New in PostgreSQL 9.4?
At the time of writing, PostgreSQL 9.3 is the latest stable release, and 9.4 is in beta with binaries available for the brave. The following features have been committed and are available in the beta release:
Materialized views are improved. In version 9.3, refreshing a materialized view locks it for reading for the entire duration of the refresh. But refreshing materialized views usually takes time, so making them inaccessible during a refresh greatly reduces their usability in production environments. Version 9.4 removes the lock so you can still read the data while the view is being refreshed. One caveat is that for a materialized view to utilize this feature, it must have a unique index on it.
The SQL:2008 analytic functions
percentile_disc(percentile discrete) andpercentile_cont(percentile continuous) are added, with the companionWITHIN GROUP (ORDER BY…)SQL construct. Examples are detailed in Depesz ORDERED SET WITHIN GROUP Aggregates. These functions give you a built-in fast median function. For example, if we have test scores and want to get the median score (median is 0.5) and 75 percentile score, we would write this query:SELECTsubject,percentile_cont(ARRAY[0.5,0.75])WITHINGROUP(ORDERBYscore)Asmed_75_scoreFROMtest_scoresGROUPBYsubject;PostgreSQL’s implementation of
percentile_contandpercentile_disccan take an array or a single value between 0 and 1 that corresponds to the percentile values desired and correspondingly returns an array of values or a single value. TheORDER BY scoresays that we are interested in getting thescorefield values corresponding to the designated percentiles.WITH CHECK OPTIONsyntax for views allows you to ensure that an update/insert on a view cannot happen if the resulting data is no longer visible in the view. We demonstrate this feature in Example 7-2.A new data type—
jsonb, a JavaScript Object Notation (JSON) binary type replete with index support—was added.jsonballows you to index a full JSON document and speed up retrieval of subelements. For details, see JSON, and check out these blog posts: “Introduce jsonb: A Structured Format for Storing JSON,” and “jsonb: Wildcard Query.”Query speed for the Generalized Inverted Index (GIN) has improved, and GIN indexes have a smaller footprint. GIN is gaining popularity and is particularly handy for full text searches, trigrams,
hstores, andjsonb. You can also use it in lieu of B-Tree in many circumstances, and it is generally a smaller index in these cases. Check out GIN as a Substitute for Bitmap Indexes.More JSON functions are available. See Depesz: New JSON functions.
You can easily move all assets from one tablespace to another using the syntax
ALTER TABLESPACE old_space MOVE ALL TO new_space;.You can use a number for set-returning functions. Often, you need a row number when extracting denormalized data stored in arrays,
hstore, composite types, and so on. Now you can add the system columnordinality(an ANSI SQL standard) to your output. Here is an example using anhstoreobject and theeachfunction that returns a key-value pair:SELECTordinality,key,valueFROMeach('breed=>pug,cuteness=>high'::hstore)WITHordinality;You can use SQL to alter system-configuration settings. The
ALTER system SET ...construct allows you to set global-system settings normally set in postgresql.conf, as detailed in postgresql.conf.Triggers can be used on foreign tables. When someone half a world away edits data, your trigger will catch this event. We’re not sure how well this will perform with the expected latency in foreign tables when the foreign table is very far away.
A new
unnestfunction predictably allocates arrays of different sizes into columns.A
ROWS FROMconstruct allows the easy use of multiple set-returning functions in a series, even if they have an unbalanced set of elements in each set:SELECT*FROMROWSFROM(jsonb_each('{"a":"foo1","b":"bar"}'::jsonb),jsonb_each('{"c":"foo2"}'::jsonb))x(a1,a1_val,a2_val);You can code dynamic background workers in C to do work as needed. A trivial example is available in the version 9.4 source code in the contrib/worker_spi directory.
PostgreSQL 9.3: New Features
The notable features that first appeared in version 9.3 (released in 2013) are:
The ANSI SQL standard
LATERALclause was added. ALATERALconstruct allowsFROMclauses with joins to reference variables on the other side of the join. Without this, cross-referencing can take place only in the join conditions.LATERALis indispensable when you work with functions that return sets, such asunnest,generate_series, regular expression table returns, and numerous others. See Lateral Joins.Parallel
pg_dumpis available. Version 8.4 brought us parallel restore, and now we have parallel backup to expedite backing up of huge databases.Materialized view (see Materialized Views) was unveiled. You can now persist data into frequently used views to avoid making repeated retrieval calls for slow queries.
Views are updatable automatically. You can use an
UPDATEstatement on a single view and have it update the underlying tables, without needing to create triggers or rules.Views now accommodate recursive common table expressions (CTEs).
More JSON constructors and extractors are available. See JSON.
Indexed regular-expression search is enabled.
A 64-bit large object API allows storage of objects that are terabytes in size. The previous limit was a mere 2 GB.
The postgres_fdw driver, introduced in Querying Other PostgreSQL Servers, allows both reading and writing to other PostgreSQL databases (even on remote servers with lower versions of PostgreSQL). Along with this change is an upgrade of the FDW API to implement writable functionality.
Numerous improvements were made to replication. Most notably, replication is now architecture-independent and supports streaming-only remastering.
Using C, you can write user-defined background workers for automating database tasks.
You can use triggers on data-definition events.
A new
watchpsql command is available. See Watching Statements.You can use a new
COPY DATAcommand both to import from and export to external programs. We demonstrate this in Copy from/to Program.
PostgreSQL 9.2: New Features
The notable features released with version 9.2 (September 2012) are:
You can perform index-only scans. If you need to retrieve columns that are already a part of an index, PostgreSQL skips the unnecessary trip back to the table. You’ll see significant speed improvement in key-value queries as well as aggregates that use only key values such as
COUNT(*).In-memory sort operations are improved by as much as 20%.
Improvements were made in prepared statements. A prepared statement is now parsed, analyzed, and rewritten, but you can skip the planning to avoid being tied down to specific argument inputs. You can also now save the plans of a prepared statement that depend on arguments. This reduces the chance that a prepared statement will perform worse than an equivalent ad hoc query.
Cascading streaming replication supports streaming from a slave to another slave.
SP-GiST, another advance in GiST index technology using space filling trees, should have enormous positive impact on extensions that rely on GiST for speed.
Using
ALTER TABLE IF EXISTS, you can make changes to tables without needing to first check to see whether the table exists.Many new variants of
ALTER TABLE ALTER TYPEcommands that used to require dropping and recreating the table were added. More details are available at More Alter Table Alter Types.More
pg_dumpandpg_restoreoptions were added. For details, read our article “9.2 pg_dump Enhancements”.PL/V8 joined the ranks of procedural languages. You can now use the ubiquitous JavaScript to compose functions.
JSON rose to the level of a built-in data type. Tagging along are functions like
row_to_jsonandarray_to_json. This should be a welcome addition for web developers writing Ajax applications. See JSON and Example 7-16.You can create new range data type classes composed of two values to constitute a range, thereby eliminating the need to cludge range-like functionality, especially in temporal applications. The debut of range type was chaparoned by numerous range operators and functions. Exclusion contraints joined the party as the perfect guardian for range types.
SQL functions can now reference arguments by name instead of by number. Named arguments are easier on the eyes if you have more than one.
PostgreSQL 9.1: New Features
With version 9.1, PostgreSQL rolled out enterprise features to compete head-on with stalwarts like SQL Server and Oracle:
More built-in replication features, including synchronous replication.
Extension management using the new
CREATE EXTENSIONandALTER EXTENSIONcommands. The installation and removal of extensions became a breeze.ANSI-compliant foreign data wrappers for querying disparate, external data sources.
Writable CTEs. The syntactical convenience of CTEs now works for
UPDATEandINSERTqueries.Unlogged tables, which makes writes to tables faster when logging is unnecessary.
Triggers on views. In prior versions, to make views updatable, you had to resort to
DO INSTEADrules, which could be written only in SQL, whereas with triggers, you have many PLs to choose from. This opens the door for more complex abstraction using views.Improvements added by the KNN GiST index to popular extensions, such as full-text searchs, trigrams (for fuzzy search and case-insensitive search), and PostGIS.
Database Drivers
If you’re using or plan to use PostgreSQL, chances are that you’re not going to use it in a vacuum. To have it interact with other applications,you need a database driver. PostgreSQL enjoys a generous number of freely available drivers supporting many programming languages and tools. In addition, various commercial organizations provide drivers with extra bells and whistles at modest prices. Several popular open source drivers are available:
PHP is a common language used to develop web applications, and most PHP distributions come packaged with at least one PostgreSQL driver: the old pgsql driver and the newer pdo_pgsql. You may need to enable them in your php.ini, but they’re usually already installed.
For Java development, the JDBC driver keeps up with latest PostgreSQL versions. Download it from PostgreSQL.
For .NET (both Microsoft or Mono), you can use the Npgsql driver. Both the source code and the binary are available for .NET Framework 3.5 and later, Microsoft Entity Framework, and Mono.NET.
If you need to connect from Microsoft Access, Office productivity software, or any other products that support Open Database Connectivity (ODBC), download drivers from PostgreSQL. The link leads you to both 32-bit and 64-bit ODBC drivers.
LibreOffice 3.5 (and later) comes packaged with a native PostgreSQL driver. For OpenOffice and older versions of LibreOffice, you can use the JDBC driver or the SDBC driver. You can learn more details from our article OO Base and PostgreSQL.
Python has support for PostgreSQL via various Python database drivers; at the moment, psycopg is the most popular. Rich support for PostgreSQL is also available in the Django web framework
If you use Ruby, connect to PostgreSQL using rubygems pg.
You’ll find Perl’s connectivity support for PostgreSQL in the DBI and the DBD::Pg drivers. Alternatively, there’s the pure Perl DBD::PgPP driver from CPAN.
Node.js is a framework for running scalable network programs written in JavaScript. It is built on the Google V8 engine. There are three PostgreSQL drivers currently: Node Postgres, Node Postgres Pure (just like Node Postgres but no compilation required), and Node-DBI.
Where to Get Help
There will come a day when you need additional help. Because that day always arrives earlier than expected, we want to point you to some resources now rather than later. Our favorite is the lively mailing list specifically designed for helping new and old users with technical issues. First, visit PostgreSQL Help Mailing Lists. If you are new to PostgreSQL, the best list to start with is PGSQL-General Mailing List. If you run into what appears to be a bug in PostgreSQL, report it at PostgreSQL Bug Reporting.
Notable PostgreSQL Forks
The MIT/BSD-style licensing of PostgreSQL makes it a great candidate for forking. Various groups have done exactly that over the years. Some have contributed their changes back to the original project.
Netezza, a popular database choice for data warehousing, was a PostgreSQL fork at inception. Similarly, the Amazon Redshift data warehouse is a fork of a fork of PostgreSQL. GreenPlum, used for data warehousing and analyzing petabytes of information, was a spinoff of Bizgres, which focused on Big Data. PostgreSQL Advanced Plus by EnterpriseDB is a fork of the PostgreSQL codebase that adds Oracle syntax and compatibility features to woo Oracle users. EnterpriseDB ploughs funding and development support to the PostgreSQL community. For this, we’re grateful. Their Postgres Plus Advanced Server is fairly close to the most recent stable version of PostgreSQL.
All the aforementioned clones are proprietary, closed source forks.
tPostgres, Postgres-XC, and Big SQL are three budding forks with
open source licensing that we find interesting. These forks all garner
support and funding from OpenSCG.
The latest version of tPostgres is built on PostgreSQL 9.3 and targets
Microsoft SQL Server users. For instance, with tPostgres, you use the packaged pgtsql language extension to write
functions that use T-SQL. The pgtsql language extension is compatible with
PostgreSQL proper, so you can use it in any PostgreSQL 9.3 installation.
Postgres-XC is a cluster server providing write-scalable, synchronous
multimaster replication. What makes Postgres-XC special is its support for
distributed processing and replication. It is now at version 1.0. Finally,
BigSQL is a marriage of the two elephants: PostgreSQL and
Hadoop with Hive. BigSQL comes packaged with
hadoop_fdw, an FDW for querying and updating Hadoop
data sources.
Another recently announced PostgreSQL open source fork is Postgres-XL (the XL stands for eXtensible Lattice), which has built-in Massively Parallel Processing (MPP) capability and data sharding across servers.
Get PostgreSQL: Up and Running, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

