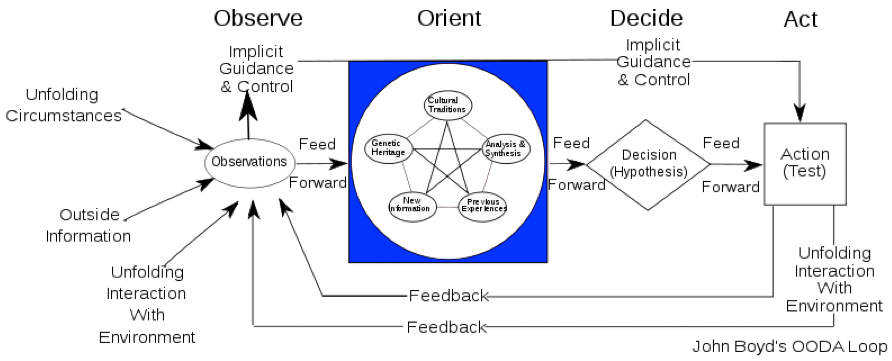
Military strategist John Boyd spent a lot of time understanding how to win battles. Building on his experience as a fighter pilot, he broke down the process of observing and reacting into something called an Observe, Orient, Decide, and Act (OODA) loop. Combat, he realized, consisted of observing your circumstances, orienting yourself to your enemy’s way of thinking and your environment, deciding on a course of action, and then acting on it.
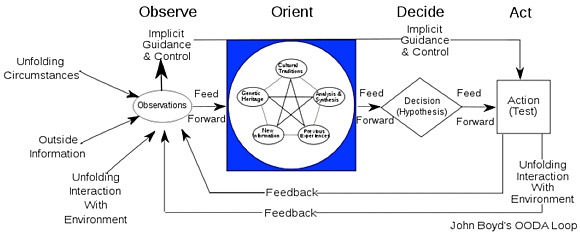
The most important part of this loop isn’t included in the OODA acronym, however. It’s the fact that it’s a loop. The results of earlier actions feed back into later, hopefully wiser, ones. Over time, the fighter “gets inside” their opponent’s loop, outsmarting and outmaneuvering them. The system learns.
Boyd’s genius was to realize that winning requires two things: being able to collect and analyze information better, and being able to act on that information faster, incorporating what’s learned into the next iteration. Today, what Boyd learned in a cockpit applies to nearly everything we do.
In our always-on lives we’re flooded with cheap, abundant information. We need to capture and analyze it well, separating digital wheat from digital chaff, identifying meaningful undercurrents while ignoring meaningless social flotsam. Clay Johnson argues that we need to go on an information diet, and makes a good case for conscious consumption. In an era of information obesity, we need to eat better. There’s a reason they call it a feed, after all.
It’s not just an overabundance of data that makes Boyd’s insights vital. In the last 20 years, much of human interaction has shifted from atoms to bits. When interactions become digital, they become instantaneous, interactive, and easily copied. It’s as easy to tell the world as to tell a friend, and a day’s shopping is reduced to a few clicks.
The move from atoms to bits reduces the coefficient of friction of entire industries to zero. Teenagers shun e-mail as too slow, opting for instant messages. The digitization of our world means that trips around the OODA loop happen faster than ever, and continue to accelerate.
We’re drowning in data. Bits are faster than atoms. Our jungle-surplus wetware can’t keep up. At least, not without Boyd’s help. In a society where every person, tethered to their smartphone, is both a sensor and an end node, we need better ways to observe and orient, whether we’re at home or at work, solving the world’s problems or planning a play date. And we need to be constantly deciding, acting, and experimenting, feeding what we learn back into future behavior.
We’re entering a feedback economy.
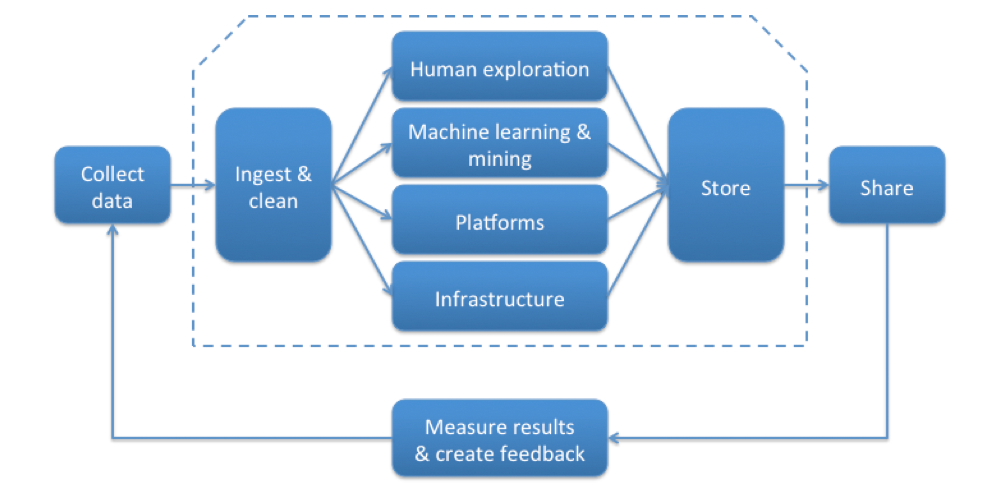
Consider how a company collects, analyzes, and acts on data.
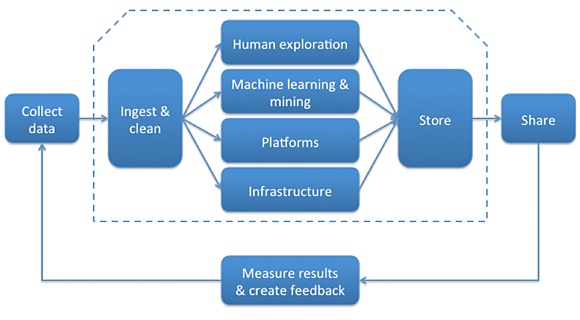
Let’s look at these components in order.
The first step in a data supply chain is to get the data in the first place.
Information comes in from a variety of sources, both public and private. We’re a promiscuous society online, and with the advent of low-cost data marketplaces, it’s possible to get nearly any nugget of data relatively affordably. From social network sentiment, to weather reports, to economic indicators, public information is grist for the big data mill. Alongside this, we have organization-specific data such as retail traffic, call center volumes, product recalls, or customer loyalty indicators.
The legality of collection is perhaps more restrictive than getting the data in the first place. Some data is heavily regulated — HIPAA governs healthcare, while PCI restricts financial transactions. In other cases, the act of combining data may be illegal because it generates personally identifiable information (PII). For example, courts have ruled differently on whether IP addresses aren’t PII, and the California Supreme Court ruled that zip codes are. Navigating these regulations imposes some serious constraints on what can be collected and how it can be combined.
The era of ubiquitous computing means that everyone is a potential source of data, too. A modern smartphone can sense light, sound, motion, location, nearby networks and devices, and more, making it a perfect data collector. As consumers opt into loyalty programs and install applications, they become sensors that can feed the data supply chain.
In big data, the collection is often challenging because of the sheer volume of information, or the speed with which it arrives, both of which demand new approaches and architectures.
Once the data is collected, it must be ingested. In traditional business intelligence (BI) parlance, this is known as Extract, Transform, and Load (ETL): the act of putting the right information into the correct tables of a database schema and manipulating certain fields to make them easier to work with.
One of the distinguishing characteristics of big data, however, is that the data is often unstructured. That means we don’t know the inherent schema of the information before we start to analyze it. We may still transform the information — replacing an IP address with the name of a city, for example, or anonymizing certain fields with a one-way hash function — but we may hold onto the original data and only define its structure as we analyze it.
The information we’ve ingested needs to be analyzed by people and machines. That means hardware, in the form of computing, storage, and networks. Big data doesn’t change this, but it does change how it’s used. Virtualization, for example, allows operators to spin up many machines temporarily, then destroy them once the processing is over.
Cloud computing is also a boon to big data. Paying by consumption destroys the barriers to entry that would prohibit many organizations from playing with large datasets, because there’s no up-front investment. In many ways, big data gives clouds something to do.
Where big data is new is in the platforms and frameworks we create to crunch large amounts of information quickly. One way to speed up data analysis is to break the data into chunks that can be analyzed in parallel. Another is to build a pipeline of processing steps, each optimized for a particular task.
Big data is often about fast results, rather than simply crunching a large amount of information. That’s important for two reasons:
Much of the big data work going on today is related to user interfaces and the web. Suggesting what books someone will enjoy, or delivering search results, or finding the best flight, requires an answer in the time it takes a page to load. The only way to accomplish this is to spread out the task, which is one of the reasons why Google has nearly a million servers.
We analyze unstructured data iteratively. As we first explore a dataset, we don’t know which dimensions matter. What if we segment by age? Filter by country? Sort by purchase price? Split the results by gender? This kind of “what if” analysis is exploratory in nature, and analysts are only as productive as their ability to explore freely. Big data may be big. But if it’s not fast, it’s unintelligible.
Much of the hype around big data companies today is a result of the retooling of enterprise BI. For decades, companies have relied on structured relational databases and data warehouses — many of them can’t handle the exploration, lack of structure, speed, and massive sizes of big data applications.
One way to think about big data is that it’s “more data than you can go through by hand.” For much of the data we want to analyze today, we need a machine’s help.
Part of that help happens at ingestion. For example, natural language processing tries to read unstructured text and deduce what it means: Was this Twitter user happy or sad? Is this call center recording good, or was the customer angry?
Machine learning is important elsewhere in the data supply chain. When we analyze information, we’re trying to find signal within the noise, to discern patterns. Humans can’t find signal well by themselves. Just as astronomers use algorithms to scan the night’s sky for signals, then verify any promising anomalies themselves, so too can data analysts use machines to find interesting dimensions, groupings, or patterns within the data. Machines can work at a lower signal-to-noise ratio than people.
While machine learning is an important tool to the data analyst, there’s no substitute for human eyes and ears. Displaying the data in human-readable form is hard work, stretching the limits of multi-dimensional visualization. While most analysts work with spreadsheets or simple query languages today, that’s changing.
Creve Maples, an early advocate of better computer interaction, designs systems that take dozens of independent, data sources and displays them in navigable 3D environments, complete with sound and other cues. Maples’ studies show that when we feed an analyst data in this way, they can often find answers in minutes instead of months.
This kind of interactivity requires the speed and parallelism explained above, as well as new interfaces and multi-sensory environments that allow an analyst to work alongside the machine, immersed in the data.
Big data takes a lot of storage. In addition to the actual information in its raw form, there’s the transformed information; the virtual machines used to crunch it; the schemas and tables resulting from analysis; and the many formats that legacy tools require so they can work alongside new technology. Often, storage is a combination of cloud and on-premise storage, using traditional flat-file and relational databases alongside more recent, post-SQL storage systems.
During and after analysis, the big data supply chain needs a warehouse. Comparing year-on-year progress or changes over time means we have to keep copies of everything, along with the algorithms and queries with which we analyzed it.
All of this analysis isn’t much good if we can’t act on it. As with collection, this isn’t simply a technical matter — it involves legislation, organizational politics, and a willingness to experiment. The data might be shared openly with the world, or closely guarded.
The best companies tie big data results into everything from hiring and firing decisions, to strategic planning, to market positioning. While it’s easy to buy into big data technology, it’s far harder to shift an organization’s culture. In many ways, big data adoption isn’t a hardware retirement issue, it’s an employee retirement one.
We’ve seen similar resistance to change each time there’s a big change in information technology. Mainframes, client-server computing, packet-based networks, and the web all had their detractors. A NASA study into the failure of Ada, the first object-oriented language, concluded that proponents had over-promised, and there was a lack of a supporting ecosystem to help the new language flourish. Big data, and its close cousin, cloud computing, are likely to encounter similar obstacles.
A big data mindset is one of experimentation, of taking measured risks and assessing their impact quickly. It’s similar to the Lean Startup movement, which advocates fast, iterative learning and tight links to customers. But while a small startup can be lean because it’s nascent and close to its market, a big organization needs big data and an OODA loop to react well and iterate fast.
The big data supply chain is the organizational OODA loop. It’s the big business answer to the lean startup.
Just as John Boyd’s OODA loop is mostly about the loop, so big data is mostly about feedback. Simply analyzing information isn’t particularly useful. To work, the organization has to choose a course of action from the results, then observe what happens and use that information to collect new data or analyze things in a different way. It’s a process of continuous optimization that affects every facet of a business.
Software is eating the world. Verticals like publishing, music, real estate and banking once had strong barriers to entry. Now they’ve been entirely disrupted by the elimination of middlemen. The last film projector rolled off the line in 2011: movies are now digital from camera to projector. The Post Office stumbles because nobody writes letters, even as Federal Express becomes the planet’s supply chain.
Companies that get themselves on a feedback footing will dominate their industries, building better things faster for less money. Those that don’t are already the walking dead, and will soon be little more than case studies and colorful anecdotes. Big data, new interfaces, and ubiquitous computing are tectonic shifts in the way we live and work.
Big data, continuous optimization, and replacing everything with data pave the way for something far larger, and far more important, than simple business efficiency. They usher in a new era for humanity, with all its warts and glory. They herald the arrival of the feedback economy.
The efficiencies and optimizations that come from constant, iterative feedback will soon become the norm for businesses and governments. We’re moving beyond an information economy. Information on its own isn’t an advantage, anyway. Instead, this is the era of the feedback economy, and Boyd is, in many ways, the first feedback economist.
Alistair Croll is the founder of Bitcurrent, a research firm focused on emerging technologies. He’s founded a variety of startups, and technology accelerators, including Year One Labs, CloudOps, Rednod, Coradiant (acquired by BMC in 2011) and Networkshop. He’s a frequent speaker and writer on subjects such as entrepreneurship, cloud computing, Big Data, Internet performance and web technology, and has helped launch a number of major conferences on these topics.
Get Planning for Big Data now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.


{kind=link}
{kind=link}