In this section, I’ve collected a few tricks and techniques that you might find useful when debugging Concurrent Haskell programs.
The threadStatus function (from GHC.Conc) returns the current
state of a thread:
threadStatus::ThreadId->IOThreadStatus
Here, ThreadStatus is defined as follows:
dataThreadStatus=ThreadRunning--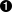
|ThreadFinished--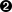
|ThreadBlockedBlockReason--
|ThreadDied--
deriving(Eq,Ord,Show)
-
The thread is currently running (or runnable).
-
The thread has finished.
-
The thread is blocked (the
BlockReasontype is explained shortly).-
The thread died because an exception was raised but not caught. This should never happen under normal circumstances because
forkIOincludes a default exception handler that catches and prints exceptions.
The BlockReason type gives more information about why a thread is
blocked and is self-explanatory:
dataBlockReason=BlockedOnMVar|BlockedOnBlackHole|BlockedOnException|BlockedOnSTM|BlockedOnForeignCall|BlockedOnOtherderiving(Eq,Ord,Show)
Here’s an example in GHCi:
> t <- forkIO (threadDelay 3000000) > GHC.Conc.threadStatus t ThreadBlocked BlockedOnMVar > -- wait a few seconds > GHC.Conc.threadStatus t ThreadFinished >
While threadStatus can be very useful for debugging, don’t use
it for normal control flow in your program. One reason
is that it breaks abstractions. For instance, in the previous example, it showed us
that threadDelay is implemented using MVar (at least in this
version of GHC). Another reason is that the result of
threadStatus is out of date as soon as threadStatus returns,
because the thread may now be in a different state.
While we should never underestimate the usefulness of adding
putStrLn calls to our programs to debug them, sometimes this isn’t
quite lightweight enough. putStrLn can introduce some extra
contention for the stdout Handle, which might perturb the
concurrency in the program you’re trying to debug. So in this section,
we’ll look at another way to investigate the behavior of a concurrent
program at runtime.
We’ve used ThreadScope a lot to diagnose performance problems in
this book. ThreadScope generates its graphs from the
information in the .eventlog file that is produced when we run a
program with the +RTS -l option. This file is a mine of information
about what was happening behind the scenes when the program ran, and
we can use it for debugging our programs, too.
You may have noticed that ThreadScope identifies threads by their
number. For debugging, it helps a lot to know which thread in the
program corresponds to which thread number; this connection can be
made using labelThread:
labelThread::ThreadId->String->IO()-- defined in GHC.Conc
The labelThread function has no effect on the running of the
program but causes the program to emit a special event into the event log.
There are also a couple of ways to put your own information in the
eventlog file:
traceEvent::String->a->atraceEventIO::String->IO()-- defined in Debug.Trace
Here’s a simple program to demonstrate labelThread and
traceEventIO in action:
mvar4.hs
main=dot<-myThreadIdlabelThreadt"main"m<-newEmptyMVart<-forkIO$putMVarm'a'labelThreadt"a"t<-forkIO$putMVarm'b'labelThreadt"b"traceEventIO"before takeMVar"takeMVarmtakeMVarm
This program forks two threads. Each of the threads puts a value into
an MVar, and then the main thread calls takeMVar on the MVar
twice.
Compile the program with -eventlog and run it with +RTS -l:
$ ghc mvar4.hs -threaded -eventlog $ ./mvar4 +RTS -l
This generates the file mvar4.eventlog, which is a space-efficient binary representation of the sequence of events that occurred in the runtime system when the program ran. You need a program to display the
contents of a .eventlog file; ThreadScope of course is one such
tool, but you can also just display the raw event stream using
the ghc-events program:[64]
$ ghc-events show mvar4.eventlog
As you might expect, there is a lot of implementation detail in the
event stream, but with the help of labelThread and traceEventIO, you
can sort through it to find the interesting bits. Note that if you
try this program yourself, you might not see exactly the same event
log; such is the nature of implementation details.
We labeled the main thread "main", so searching for main in the
log finds this section:
912458: cap 0: running thread 3 950678: cap 0: thread 3 has label "main" --997067: cap 0: running thread 4 --
1007167: cap 0: stopping thread 4 (thread finished) 1008066: cap 0: running thread 5 --
1010022: cap 0: stopping thread 5 (blocked on an MVar) 1045297: cap 0: running thread 3 --
1064248: cap 0: before takeMVar --
1066973: cap 0: waking up thread 5 on cap 0 --
1067747: cap 0: stopping thread 3 (thread finished) --
-
This event was generated by
labelThread. GHC needs some threads for its own purposes, so it turns out that in this case the main thread is thread 3.-
This is the first
forkIOexecuted by the main thread, creating thread 4.-
The main thread labels thread 4 as
a.-
The second
forkIOcreates thread 5, which is then labeled asb.-
Next, the main thread “yields.” This means it stops running to give another thread a chance to run. This happens at regular intervals during execution due to pre-emption.
-
The next thread to run is thread 4, which is
a. This thread will put a value into theMVarand then finish.-
Next, thread 5 (
b) runs. It also puts in theMVarbut gets blocked because theMVaris already full.-
The main thread runs again.
-
This is the effect of the call to
traceEventIOin the main thread; it helps us to know where in the code we’re currently executing. Be careful withtraceEventIOandtraceEvent, though. They have to convertStringvalues into raw bytes to put in the event log and can be expensive, so use them only to annotate things that don’t happen too often.-
When the main thread calls
takeMVar, this has the effect of waking up thread 5 (b), which was blocked inputMVar.
The main thread has finished, so the program exits.
So from this event log we can see the sequence of actions that happened at runtime, including which threads got blocked when, and some information about why they got blocked. These clues can often be enough to point you to the cause of a problem.
As I mentioned briefly in Communication: MVars, the GHC runtime system can
detect when a thread has become deadlocked and send it the
BlockedIndefinitelyOnMVar exception. How exactly does this work?
Well, in GHC both threads and MVars are objects on the heap, just
like other data values. An MVar that has blocked threads is
represented by a heap object that points to a list of the blocked
threads. Heap objects are managed by the garbage
collector, which traverses the heap starting from the roots to
discover all the live objects. The set of roots consists of the
running threads and the stack associated with each of these threads.
Any thread that is not reachable from the roots is definitely
deadlocked. The runtime system cannot ever find these threads by
following pointers, so they can never become runnable again.
For example, if a thread is blocked in takeMVar on an MVar that is
not referenced by any other thread, then both the MVar that it is
blocked on and the thread itself will be unreachable. When a thread
is found to be unreachable, it is sent the BlockedIndefinitelyOnMVar
exception (there is also a BlockedIndefinitelyOnSTM exception for
when a thread is blocked in an STM transaction). The exception gives
the thread a chance to clean up any resources it may have been
holding and also allows the program to quit with an error message
rather than hanging in the event of a deadlock.
The concept extends to mutual deadlock between a group of threads. Suppose we create two threads that deadlock on each other like this:
a<-newEmptyMVarb<-newEmptyMVarforkIO(dotakeMVara;putMVarb())forkIO(dotakeMVarb;putMVara())...
Then both threads are blocked, each on an MVar that is reachable
from the other. As far as the garbage collector is concerned, both
threads and the MVars a and b are unreachable (assuming the
rest of the program does not refer to a or b). When there are
multiple unreachable threads, they are all sent the
BlockedIndefinitelyOnMVar exception at the same time.
This all seems quite reasonable, but you should be aware of some consequences that might not be immediately obvious. Here’s an example:[65]
deadlock1.hs
main=dolock<-newEmptyMVarcomplete<-newEmptyMVarforkIO$takeMVarlock`finally`putMVarcomplete()takeMVarcomplete
Study the program for a moment and think about what you expect to happen.
The child thread is clearly deadlocked, and so it should receive the
BlockedIndefinitelyOnMVar exception. This will cause the finally
action to run, which performs putMVar complete (), which will in
turn unblock the main thread. However, this is not what happens. At
the point where the child thread is deadlocked, the main thread is also deadlocked. The runtime system has no idea that sending the
exception to the child thread will cause the main thread to become
unblocked, so the behavior when there is a group of deadlocked
threads is to send them all the exception at the same time. Hence the
main thread also receives the BlockedIndefinitelyOnMVar exception,
and the program prints an error message.
The second consequence is that the runtime can’t always prove that a thread is deadlocked even if it seems obvious to you. Here’s another example:
deadlock2.hs
main=dolock<-newEmptyMVarforkIO$dor<-try(takeMVarlock);(r::EitherSomeException())threadDelay1000000(lock==lock)
We might expect the child thread to be detected as deadlocked here because it is clear that nothing is ever going to put into the lock
MVar. But the child thread never receives an exception, and the
program completes printing True. The reason the deadlock is not
detected here is that the main thread is holding a reference to the
MVar lock because it is used in the (slightly contrived)
expression (lock == lock) on the last line. Deadlock detection
works using garbage collection, which is necessarily a conservative
approximation to the true future behavior of the program.
Suppose that instead of the last line, we had written this:
ifisPrime43thenreturn()elseputMVarlock()
Provided that the compiler optimizes away isPrime 43, we would get a
deadlock exception. You can’t in general know how clever the compiler
is going to be, so you should not rely on deadlock detection for the correct working of your program. Deadlock detection is a debugging
feature; in the event of a deadlock, you get an exception rather than a
silent hang, but you should aim to never have any deadlocks in your
program.
In this section, I’ll cover a few tips and techniques for improving the performance of concurrent programs. The standard principles apply here, just as much as in ordinary sequential programming:
- Avoid premature optimization. Don’t overoptimize code until you know there’s a problem. That said, “avoiding premature optimization” is not an excuse for writing awful code. For example, don’t use wildly inappropriate data structures if using the right one is just a matter of importing a library. I like to “write code with efficiency in mind”: know the complexity of your algorithms, and if you find yourself using something worse than O(nlogn), think about whether it might present a problem down the road. The more of this you do, the better your code will cope with larger and larger problems.
-
Don’t waste time optimizing code that doesn’t contribute much to overall runtime. Profile your program so that you can focus your
efforts on the important parts. GHC has a reasonable space and
time profiler that should point out at least where the inner loops
of your code are. In concurrent programs, the problem can often be
I/O or contention, in which case using ThreadScope together with
labelThreadandtraceEventcan help track down the culprits (see Event Logging and ThreadScope).
GHC strives to provide an extremely efficient implementation of threads. This section explores the performance of a couple of very simple concurrent programs to give you a feel for the efficiency of the basic concurrency operations and how to inspect the performance of your programs.
The first program creates 1,000,000 threads, has each of them put a
token into the same MVar, and then reads the 1,000,000 tokens from
the MVar:
threadperf1.hs
numThreads=1000000main=dom<-newEmptyMVarreplicateM_numThreads$forkIO(putMVarm())replicateM_numThreads$takeMVarm
This program should give us an indication of the memory overhead for
threads because all the threads will be resident in memory at once.
To find out the memory cost, we can run the program with +RTS -s
(the output is abbreviated slightly here):
$ ./threadperf1 +RTS -s
1,048,049,144 bytes allocated in the heap
3,656,054,520 bytes copied during GC
799,504,400 bytes maximum residency (10 sample(s))
146,287,144 bytes maximum slop
1,768 MB total memory in use (0 MB lost due to fragmentation)
INIT time 0.00s ( 0.00s elapsed)
MUT time 0.75s ( 0.76s elapsed)
GC time 2.21s ( 2.22s elapsed)
EXIT time 0.18s ( 0.18s elapsed)
Total time 3.14s ( 3.16s elapsed)So about 1 GB was allocated, although the total memory required by
the program was 1.7 GB. The amount of allocated memory tells us that
threads require approximately 1 KB each, and the extra memory used by the program is due to copying GC overheads. In fact, it is possible to
tune the amount of memory given to a thread when it is allocated,
using the +RTS -k<size> option; here is the same program using
400-byte threads:
$ ./threadperf1 +RTS -s -k400
424,081,144 bytes allocated in the heap
1,587,567,240 bytes copied during GC
387,551,912 bytes maximum residency (9 sample(s))
87,195,664 bytes maximum slop
902 MB total memory in use (0 MB lost due to fragmentation)
INIT time 0.00s ( 0.00s elapsed)
MUT time 0.59s ( 0.59s elapsed)
GC time 1.60s ( 1.61s elapsed)
EXIT time 0.13s ( 0.13s elapsed)
Total time 2.32s ( 2.33s elapsed)A thread will allocate more memory for its stack on demand, so whether
it is actually a good idea to use +RTS -k400 will depend on your
program. In this case, the threads were doing very little before
exiting, so it did help the overall performance.
The second example also creates 1,000,000 threads, but this time we
create a separate MVar for each thread to put a token into and then
take all the MVars in the main thread before exiting:
threadperf2.hs
numThreads=1000000main=doms<-replicateMnumThreads$dom<-newEmptyMVarforkIO(putMVarm())returnmmapM_takeMVarms
This program has quite different performance characteristics:
$ ./threadperf2 +RTS -s
1,153,017,744 bytes allocated in the heap
267,061,032 bytes copied during GC
62,962,152 bytes maximum residency (8 sample(s))
4,662,808 bytes maximum slop
121 MB total memory in use (0 MB lost due to fragmentation)
INIT time 0.00s ( 0.00s elapsed)
MUT time 0.70s ( 0.72s elapsed)
GC time 0.50s ( 0.50s elapsed)
EXIT time 0.02s ( 0.02s elapsed)
Total time 1.22s ( 1.24s elapsed)Although it allocated a similar amount of memory, the total memory in use
by the program at any one time was only 121 MB. This is because each
thread can run to completion independently, unlike the previous
example where all the threads were present and blocked on the same
MVar. So while the main thread is busy creating more threads, the
threads it has already created can run, complete, and be garbage-collected, leaving behind only the MVar for the main thread to take later.
Note that the GC overheads of this program are much lower than the
first example. The total time gives us a rough indication of the time
it takes to create an MVar and a thread, and for the thread to run,
put into the MVar, complete, and be garbage-collected. We did this
1,000,000 times in about 1.2s, so the time per thread is about 1.2
microseconds.
The conclusion is that threads are cheap in GHC, in both creation time and memory overhead. Context-switch performance is also efficient, as it does not require a kernel round-trip, although we haven’t measured that here. The memory used by threads is automatically recovered when the thread completes, and because thread stacks are movable in GHC, you don’t have to worry about memory fragmentation or running out of address space, as you do with OS threads. The number of threads we can have is limited only by the amount of memory.
We covered one trick here: the +RTS -k<size> option, which tunes the
initial stack size of a thread. If you have a lot of very tiny
threads, it might be worth tweaking this option from its default 1k
to see if it makes any difference.
We’ve encountered shared data structures a few times so far: the phonebook example in MVar as a Container for Shared State, the window-manager in Chapter 10, and the semaphore in Limiting the Number of Threads with a Semaphore, not to mention various versions of channels. Those examples covered most of the important techniques to use with shared data structures, but we haven’t compared the various choices directly. In this section, I’ll briefly summarize the options for shared state, with a focus on the performance implications of the different choices.
Typically, the best approach when you want some shared state is to take
an existing pure data structure, such as a list or a Map, and store
it in a mutable container. Not only is this straightforward to
accomplish, but there are a wide range of well-tuned pure data
structures to choose from, and using a pure data structure means that
reads and writes are automatically concurrent.
There are a couple of subtle performance issues to be aware of, though. The first is the effect of lazy evaluation when writing a new value into the container, which we covered in MVar as a Container for Shared State. The second is the choice of mutable container itself, which exposes some subtle performance trade-offs. There are three choices:
-
MVar -
We found in Limiting the Number of Threads with a Semaphore that using an
MVarto keep a shared counter did not perform well under high contention. This is a consequence of the fairness guarantee thatMVaroffers: if a thread relinquishes anMVarand there is another thread waiting, it must then hand over to the waiting thread; it cannot continue running and take theMVaragain. -
TVar -
Using a
TVarsometimes performs better thanMVarunder contention and has the advantage of being composable with other STM operations. However, be aware of the other performance pitfalls with STM described in Performance. -
IORef Using an
IOReftogether withatomicModifyIORefis often a good choice for performance, as we saw in Limiting the Number of Threads with a Semaphore. The main pitfall here is lazy evaluation; getting enough strictness when usingatomicModifyIORefis quite tricky. This is a good pattern to follow:b<-atomicModifyIORefref(\x->let(a,b)=fxin(a,a`seq`b))b`seq`returnbThe
seqcall on the last line forces the second component of the pair, which itself is aseqcall that forcesa, which in turn forces the call tof. All of this ensures that both the value stored inside theIORefand the return value are evaluated strictly, and no chains of thunks are built up.
GHC has plenty of options to tune the behavior of the runtime system (RTS). For full details, see the GHC User’s Guide. Here, I’ll highlight a few of the options that are good targets for tuning concurrent and parallel programs.
RTS options should be placed between +RTS and -RTS, but the -RTS
can be omitted if it would be at the end of the command line.
-
-N[cores] (Default: 1) We encountered
-Nmany times throughout Part I. But what value should you pass? GHC can automatically determine the number of processors in your machine if you use-Nwithout an argument, but that might not always be the best choice. The GHC runtime system scales well when it has exclusive access to the number of processors specified with-N, but performance can degrade quite rapidly if there is contention for some of those cores with other processes on the machine.Should you include hyperthreaded cores in the count? Anecdotal evidence suggests that using hyperthreaded cores often gives a small performance boost, but obviously not as much as a full core. On the other hand, it might be wise to leave the hyperthreaded cores alone in order to provide some insulation against any contention arising from other processes. Be aware that using
-Nalone normally includes hyperthreaded cores.-
-qa -
(Default: off) Enables the use of processor affinity, which locks
the Haskell program to specific cores. Normally the operating
system is free to migrate the threads that run the Haskell program
around the cores in the machine in response to other activity, but
using
-qaprevents it from doing so. This can improve performance or degrade it, depending on the scheduling behavior of your operating system and the demands of the program. -
-Asize (Default:
512k) This option controls the size of the memory allocation area for each core. A good rule of thumb is to keep this around the size of the L2 cache per core on your machine. Cache sizes vary a lot and are often shared between cores, and sometimes there is even an L3 cache, too. So setting the-Avalue is not an exact science.There are two opposing factors at play here: using more memory means we run the garbage collector less, but using less memory means we use the caches more. The sweet spot depends on the characteristics of the program and the hardware, so the only consistent advice is to try various values and see what helps.
-
-Iseconds - (Default: 0.3) This option affects deadlock detection (Detecting Deadlock). The runtime needs to perform a full garbage collection in order to detect deadlocked threads. When the program is idle, the runtime doesn’t know whether a thread will wake up again, or the program is deadlocked and the garbage collector should be run to detect the deadlock. The compromise is to wait until the program has been idle for a short period of time before running the garbage collector, which by default is 0.3 seconds. This might be a bad idea if a full GC takes a long time (because your program has lots of data) and it regularly goes idle for short periods of time, in which case you might want to tune this value higher.
-
-C[seconds] - (Default 0.02) This option sets the context-switch interval, which determines how often the scheduler interrupts the current thread to run the next thread on the run queue. The scheduler switches between runnable threads in a round-robin fashion. As a rule of thumb, this option should not be set too low because frequent context switches harm performance, and should not be set too high because that can cause jerkiness and stuttering in interactive threads.
Haskell has a foreign function interface (FFI) that allows Haskell code to call, and be called by, foreign language code (primarily C). Foreign languages also have their own threading models—in C, there are POSIX and Win32 threads, for example—so we need to specify how Concurrent Haskell interacts with the threading models of foreign code.
All of the following assumes the use of GHC’s -threaded option.
Without -threaded, the Haskell process uses a single OS thread only,
and multithreaded foreign calls are not supported.
An out-call is a call made from Haskell to a foreign language. At the
present time, the FFI supports only calls to C, so that’s all we
describe here. In the following, we refer to threads in C (i.e., POSIX
or Win32 threads) as “OS threads” to distinguish them from the Haskell
threads created with forkIO.
As an example, consider making the POSIX C function read() callable
from Haskell:
foreign import ccall"read"c_read::CInt-- file descriptor->PtrWord8-- buffer for data->CSize-- size of buffer->CSSize-- bytes read, or -1 on error
This declares a Haskell function c_read that can be used to call the
C function read(). Full details on the syntax of foreign
declarations and the relationship between C and Haskell types can be
found in the Haskell
2010 Language Report.
Just as Haskell threads run concurrently with one another, when a
Haskell thread makes a foreign call, that foreign call runs
concurrently with the other Haskell threads, and indeed with any other
active foreign calls. The only way that two C calls can be
running concurrently is if they are running in two separate OS
threads, so that is exactly what happens; if several Haskell threads
call c_read and they all block waiting for data to be read, there
will be one OS thread per call blocked in read().
This has to work even though Haskell threads are not normally mapped one to one with OS threads; in GHC, Haskell threads are lightweight and managed in user space by the runtime system. So to handle concurrent foreign calls, the runtime system has to create more OS threads, and in fact it does this on demand. When a Haskell thread makes a foreign call, another OS thread is created (if necessary), and the responsibility for running the remaining Haskell threads is handed over to the new OS thread, while the current OS thread makes the foreign call.
The implication of this design is that a foreign call may be executed in any OS thread, and subsequent calls may even be executed in different OS threads. In most cases, this isn’t a problem, but sometimes it is; some foreign code must be called by a particular OS thread. There are two situations where this happens:
- Libraries that allow only one OS thread to use their API. GUI libraries often fall into this category. Not only must the library be called by only one OS thread, but it must often be one particular thread (e.g., the main thread). The Win32 GUI APIs are an example of this.
- APIs that use internal thread-local state. The best known example of this is OpenGL, which supports multithreaded use but stores state between API calls in thread-local storage. Hence, subsequent calls must be made in the same OS thread; otherwise, the later call will see the wrong state.
To handle these requirements, Haskell has a concept of bound
threads. A bound thread is a Haskell thread/OS thread pair that guarantees
that foreign calls made by the Haskell thread always take place in the
associated OS thread. A bound thread is created by forkOS:
forkOS::IO()->IOThreadId
Care should be taken when calling forkOS; it creates a complete new
OS thread, so it can be quite expensive. Furthermore, bound threads
are much more expensive than unbound threads. When context-switching
to or from a bound thread, the runtime system has to switch OS
threads, which involves a trip through the operating system and tends
to be very slow. Use bound threads sparingly.
For more details on bound threads, see the documentation for the
Control.Concurrent module.
Note
There is a common misconception about forkOS, which is partly a
consequence of its poorly chosen name. Upon seeing a function called
forkOS, one might jump to the conclusion that you need to use
forkOS to call a foreign function like read() and have it run
concurrently with the other Haskell threads. This isn’t the case. As
I mentioned earlier, the GHC runtime system creates more OS threads on
demand for running foreign calls. Moreover, using forkOS instead of
forkIO will make your code a lot slower.
The only reason to call forkOS is to create a bound thread,
and the only reason for wanting bound threads is to work with foreign
libraries that have particular requirements about the OS thread in which a
call is made.
Caution
The thread that runs main in a Haskell program is a bound thread.
This can give rise to a serious performance problem if you use the
main thread heavily; communication between the main thread and other
Haskell threads will be extremely slow. If you notice that your
program runs several times slower when -threaded is added, this
is the most likely cause.
The best way around this problem is just to create a new thread from
main and work in that instead.
When a Haskell thread is making a foreign call, it cannot receive
asynchronous exceptions. There is no way in general to interrupt a
foreign call, so the runtime system waits until the call returns
before raising the exception. This means that a thread blocked in a
foreign call may be unresponsive to timeouts and interrupts, and
moreover that calling throwTo will block if the target thread is in
a foreign call.
The trick for working around this limitation is to perform the foreign call in a separate thread. For example:
doa<-async$c_readfdbufsizer<-waita...
Now the current thread is blocked in wait and can be interrupted
by an exception as usual. Note that if an exception is raised it
won’t cancel the read() call, which will continue in the background.
Don’t be tempted to use withAsync here because withAsync will
attempt to kill the thread calling read() and will block in doing so.
Operations in the standard System.IO library already work this way
behind the scenes because they delegate blocking operations to a
special IO manager thread. So there’s no need to worry about forking
extra threads when calling standard IO operations.
In-calls are calls to Haskell functions that have been exposed to
foreign code with a foreign export declaration. For example, if we have a
function f of type Int -> IO Int, we could expose it like this:
foreign export ccall"f"f::Int->IOInt
This would create a C function with the following signature:
HsIntf(HsInt);
Here, HsInt is the C type corresponding to Haskell’s Int
type.
In a multithreaded program, it is entirely possible for f to be
called by multiple OS threads concurrently. The GHC runtime system
supports this (provided you use -threaded) with the following
behavior: each call becomes a new bound thread. That is, a
new Haskell thread is created for each call, and the Haskell thread is
bound to the OS thread that made the call. Hence, any further
out-calls made by the Haskell thread will take place in the same OS
thread that made the original in-call. This turns out to be important
for dealing with GUI callbacks. The GUI wants to run in the main OS
thread only, so when it makes a callback into Haskell, we need to
ensure that GUI calls made by the callback happen in the same OS
thread that invoked the callback.
Get Parallel and Concurrent Programming in Haskell now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

