All of the data structures discussed so far in this chapter are server entities. Users request data from an Oracle server through database queries. Oracle’s query optimizer must then determine the best way to access the data requested by each query.
One of the great virtues of a relational database is its ability to access data without predefining the access paths to the data. When a SQL query is submitted to an Oracle database, Oracle must decide how to access the data. The process of making this decision is called query optimization , because Oracle looks for the optimal way to retrieve the data. This retrieval is known as the execution path . The trick behind query optimization is to choose the most efficient way to get the data, since there may be many different options available.
For instance, even with a query that involves only a single table, Oracle can take either of these approaches:
Although it’s usually much faster to retrieve data using an index, the process of getting the values from the index involves an additional I/O step in processing the query. Query optimization may be as simple as determining whether the query involves selection conditions that can be imposed on values in the index. Using the index values to select the desired rows involves less I/O and is therefore more efficient than retrieving all the data from the table and then imposing the selection conditions.
Another factor in determining the optimal query execution plan is whether there is an ORDER BY condition in the query that can be automatically implemented by the presorted index. Alternatively, if the table is small enough, the optimizer may decide to simply read all the blocks of the table and bypass the index since it estimates the cost of the index I/O plus the table I/O to be higher than just the table I/O.
The query optimizer has to make some key decisions even with a query on a single table. When a more involved query is submitted, such as one involving many tables that must be joined together efficiently or one that has a complex selection criteria and multiple levels of sorting, the query optimizer has a much more complex task.
You can choose between two different Oracle query optimizers, a rule-based optimizer and a cost-based optimizer, which are described in the following sections.
Oracle has always had a query optimizer, but until Oracle7 the optimizer was only rule-based. The rule-based optimizer, as the name implies, uses a set of predefined rules as the main determinant of query optimization decisions.
Rule-based optimization is smarter than other random methods of optimization, despite some significant weaknesses. One weakness is the simplistic set of rules. The Oracle rule-based optimizer has about twenty rules and assigns a weight to each one of them. In a complex database, a query can easily involve several tables, each with several indexes and complex selection conditions and ordering. This complexity means that there will be a lot of options, and the simple set of rules used by the rule-based optimizer might not make the best choice.
The rule-based optimizer assigns an optimization score to each potential execution path and then takes the path with the best optimization score. Another main weakness of the rule-based optimizer stems from the way it resolves optimization choices made in the event of a “tie” score. When two paths present the same optimization score, the rule-based optimizer looks to the syntax of the SQL statement to resolve the tie. The winning execution path is based on the order in which the tables occur in the SQL statement.
You can understand the potential impact of this type of tie-breaker by looking at a simple situation in which a small table with 10 rows, SMALLTAB, is joined to a large table with 10,000 rows, LARGETAB, as shown in Figure 4-4. If the optimizer chooses to read SMALLTAB first, the Oracle database will read the 10 rows and then read LARGETAB to find the matching rows for all 10 of these rows. If the optimizer chooses to read LARGETAB first, the database will read 10,000 rows from LARGETAB and then read SMALLTAB 10,000 times to find the matching rows. Of course, the rows in SMALLTAB will probably be cached, thus reducing the impact of each probe, but the two optimizer choices still offer a dramatic difference in potential performance.
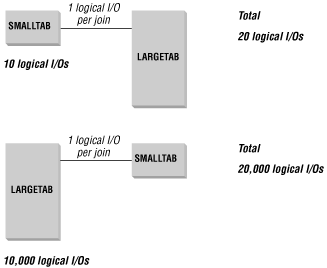
Differences like this occur as a result of the ordering of the table names in the query. In the previous situation the rule-based optimizer returns the same results, but it uses widely varying amounts of resources to retrieve those results.
To improve the optimization of SQL statements, Oracle introduced the cost-based optimizer in Oracle7. As the name implies, the cost-based optimizer does more than simply look at a set of optimization rules; instead, it selects the execution path that requires the least number of logical I/O operations. This approach avoids the error discussed in the previous section. After all, the cost-based optimizer would know which table was bigger and would select the right table to begin the query, regardless of the syntax of the SQL statement.
Oracle8 and later versions, by default, attempt to use the cost-based optimizer to identify the optimal execution plan. To properly evaluate the cost of any particular execution plan, the cost-based optimizer uses statistics about the composition of the relevant data structures.
Like the rule-based optimizer, the cost-based optimizer finds the optimal execution plan by assigning an optimization score for each of the potential execution plans. However, the cost-based optimizer uses its own internal rules and logic along with statistics that reflect the state of the data structures in the database. These statistics relate to the tables, columns, and indexes involved in the execution plan. The statistics for each type of data structure are listed in Table 4-1.
Table 4-1. Database Statistics
|
Data Structure |
Type of Statistics |
|---|---|
|
Table |
Number of rows Number of blocks Number of unused blocks Average available free space per block Number of chained rows Average row length |
|
Column |
Number of distinct values per column Second-lowest column value Second-highest column value Column density factor |
|
Index |
Depth of index B*-tree structure Number of leaf blocks Number of distinct values Average number of leaf blocks per key Average number of data blocks per key Clustering factor |
These statistics are stored in three tables in the data dictionary, which are described in Section 4.9.
You can see that these statistics can be used individually and in combination to determine the overall cost of the I/O required by an execution plan. The statistics reflect both the size of a table and the amount of unused space within the blocks; this space can, in turn, affect how many I/O operations are needed to retrieve rows. The index statistics reflect not only the depth and breadth of the index tree, but also the uniqueness of the values in the tree, which can affect the ease with which values can be selected using the index.
Oracle8 and later versions use the SQL statement ANALYZE to collect these statistics. You can analyze a table, an index, or a cluster in a single SQL statement. Collecting statistics can be a resource-intensive job; in some ways, it’s like building an index. Because of its potential impact, the ANALYZE command has two options:
The latter choice makes gathering the relative statistics for the data structure consume far fewer resources than computing the exact figures for the entire structure. If you have a very large table, for example, analyzing 5% or less of the table will probably produce an accurate estimate of the relative percentages of unused space and other relative data.
Tip
The accuracy of the cost-based optimizer depends on the accuracy of the statistics it uses, so you should make updating statistics a standard part of your maintenance plan.
The use of statistics makes it possible for the cost-based optimizer to make a much more well-informed choice of the optimal execution plan. For instance, the optimizer could be trying to decide between two indexes to use in an execution plan that involves a selection based on a value in either index. The rule-based optimizer might very well rate both indexes equally and resort to the order in which they appear in the WHERE clause to choose an execution plan. The cost-based optimizer, however, knows that one index contains 1,000 entries while the other contains 10,000 entries. It even knows that the index that contains 1,000 values contains only 20 unique values, while the index that contains 10,000 values has 5,000 unique values. The selectivity offered by the larger index is much greater, so that index will be assigned a better optimization score and used for the query.
With Oracle9i, you have the option of allowing the cost-based optimizer to use CPU speed as one of the factors in determining the optimal execution plan. An initialization parameter turns this feature on and off.
Even with all the information available to it, the cost-based optimizer does have flaws. Aside from the fact that it (like all software) occasionally has bugs, the cost-based optimizer uses statistics that don’t provide a complete picture of the data structures. In the previous example, the only thing the statistics tell the optimizer about the indexes is the number of distinct values in each index. They don’t reveal anything about the distribution of those values. For instance, the larger index can contain 5,000 unique values, but these values can each represent two rows in the associated table, or one index value can represent 5,001 rows while the rest of the index values represent a single row. The selectivity of the index varies wildly, depending on the value used in the selection criteria of the SQL statement. Fortunately, Oracle 7.3 introduced support for collecting histogram statistics for indexes to address this exact problem. You create histograms using syntax within the ANALYZE INDEX command, which is described in your Oracle SQL reference documentation.
Oracle8 and beyond come with a built-in PL/SQL package, DBMS_STATS, which contains a number of procedures that can help you to automate the process of collecting statistics. Many of the procedures in this package also collect statistics with parallel operations, which can speed up the collection process.
There are two ways you can influence the way the cost-based optimizer selects an execution plan. The first way is by setting the optimizer mode to favor either batch-type requests or interactive requests with the ALL_ROWS or FIRST_ROWS choice.
You can set the optimizer mode to weigh the options for the execution plan to either favor ALL_ROWS, meaning the overall time that it takes to complete the execution of the SQL statement, or FIRST_ROWS, meaning the response time for returning the first set of rows from a SQL statement. The optimizer mode tilts the evaluation of optimization scores slightly and, in some cases, may result in a different execution plan. ALL_ROWS and FIRST_ROWS are two of four choices for the optimizer mode, which is described in more detail in the next section.
Oracle also gives you a way to completely override the decisions of the optimizer with a technique called hints. A hint is nothing more than a comment with a specific format inside a SQL statement. You can use hints to force a variety of decisions onto the optimizer, such as:
Use of the rule-based optimizer
Use of a full table scan
Use of a particular index
Use of a specific number of parallel processes for the statement
Hints come with their own set of problems. A hint looks just like a comment, as shown in this extremely simple SQL statement. Here, the hint forces the optimizer to use the EMP_IDX index for the EMP table:
SELECT /*+ INDEX(EMP_IDX) */ LASTNAME, FIRSTNAME, PHONE FROM EMP
If a hint isn’t in the right place in the SQL statement, if the hint keyword is misspelled, or if you change the name of a data structure so that the hint no longer refers to an existing structure, the hint will simply be ignored, just as a comment would be. Because hints are embedded into SQL statements, repairing them can be quite frustrating and time-consuming if they aren’t working properly. In addition, if you add a hint to a SQL statement to address a problem caused by a bug in the cost-based optimizer and the cost-based optimizer is subsequently fixed, the SQL statement is still outside the veil of the optimization calculated by the optimizer.
However, hints do have a place—for example, when a developer has a user-defined datatype that suggests a particular type of access. The optimizer cannot anticipate the effect of user-defined datatypes, but a hint can properly enable the appropriate retrieval path.
For more details about when hints might be considered, see Accepting the Verdict of the Optimizer later in this chapter.
In the previous section we mentioned two optimizer modes: ALL_ROWS and FIRST_ROWS. The two other valid optimizer modes are:
- RULE
Forces the use of the rule-based optimizer
- CHOOSE
Allows Oracle to choose whether to use the cost-based optimizer or the rule-based optimizer
With an optimizer mode of CHOOSE, which is the default setting, Oracle will use the cost-based optimizer if any of the tables in the SQL statement have statistics associated with them. The cost-based optimizer will make a statistical estimate for the tables that lack statistics. It’s important to understand that partially collected statistics can cause tremendous problems. If one of the tables in a SQL statement has statistics, Oracle will use the cost-based optimizer. If the optimizer is acting on incomplete information, the quality of optimization will suffer accordingly. If you’re going to use the cost-based optimizer, make sure you gather complete statistics for your databases.
You can set the optimizer level at the instance level, at the session level, or within an individual SQL statement. But the big question remains, especially for those of you who have been using Oracle since before the introduction of the cost-based optimizer: which optimizer should I choose?
We favor using the cost-based optimizer for several reasons.
First, the cost-based optimizer makes decisions with a wider range of knowledge about the data structures in the database. Although the cost-based optimizer isn’t flawless in its decision-making process, it does tend to make more accurate decisions based on its wider base of information, especially because it has been around since Oracle7 and has been improved with each new release.
Second, the cost-based optimizer has been enhanced to take into account improvements in the Oracle database itself, while the rule-based optimizer has not. For instance, the cost-based optimizer understands the impact that partitioned tables have on the selection of an execution plan, while the rule-based optimizer does not. As another example, the cost-based optimizer can optimize execution plans for star schema queries, which are heavily used in data warehousing, while the rule-based optimizer has not been enhanced to deal effectively with these types of queries.
The reason for this bias is simple: Oracle Corporation has been quite frank about their intention to make the cost-based optimizer the optimizer for the Oracle database. Oracle isn’t adding new features to the rule-based optimizer and hasn’t guaranteed support for it in future releases.
The future lies in the cost-based optimizer. But there are still situations in which you should use the rule-based optimizer.
As the old saying goes, if it ain’t broke, don’t fix it. And you may be in an environment in which you’ve designed and tuned your SQL to operate optimally with the rule-based optimizer. Although you should still look ahead to a future in which only the cost-based optimizer is supported, there may be no reason to switch over to the cost-based optimizer now if you have an application that is already performing at its best.
The chances are pretty good that the cost-based optimizer will choose the same execution plan as a properly tuned application using the rule-based optimizer. But there is always a chance that the cost-based optimizer will make a different choice, which can create more work for you, because you might have to spend time tracking down the different optimizations.
Remember the bottom line for all optimizers: no optimizer can provide a performance increase for a SQL statement that’s already running optimally. The cost-based optimizer is not a magic potion that remedies the problems brought on by a poor database and application design or an inefficient implementation platform.
The good news is that Oracle lets you use either optimization method to shape, or even override, the way the optimizers do their job.
There may be times when you want to prevent the optimizer from calculating a new plan whenever a SQL statement is submitted. For example, you might do this if you’ve finally reached a point at which you feel the SQL is running optimally, and you don’t want the plan to change regardless of future changes to the optimizer or the database.
Starting with Oracle8i, you can create a stored outline that will store the attributes used by the optimizer to create an execution plan. Once you have a stored outline, the optimizer simply uses the stored attributes to create an execution plan. With Oracle9i, you can also edit the hints that make up a stored outline.
Remember that storing an outline fixes the optimization of the outline at the time the outline was stored. Any subsequent improvements to the optimizer will not affect the stored outlines, so you should document your use of stored outlines and consider restoring them with new releases.
Get Oracle Essentials: Oracle9i, Oracle8i and Oracle8, Second Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

