29.1
Cluster-Architekturen
683
29.1 Cluster-Architekturen
Das Angebot an Cluster-Datenbanksystemen ist relativ begrenzt. Zusätzlich unter-
scheiden sich die Systeme grundlegend in ihrer Architektur. So bietet IBM die
DB2 Shared Database als Alternative an. Im Unterschied zu Real Application Clus-
ters basiert diese jedoch auf einer Shared Nothing-Architektur.
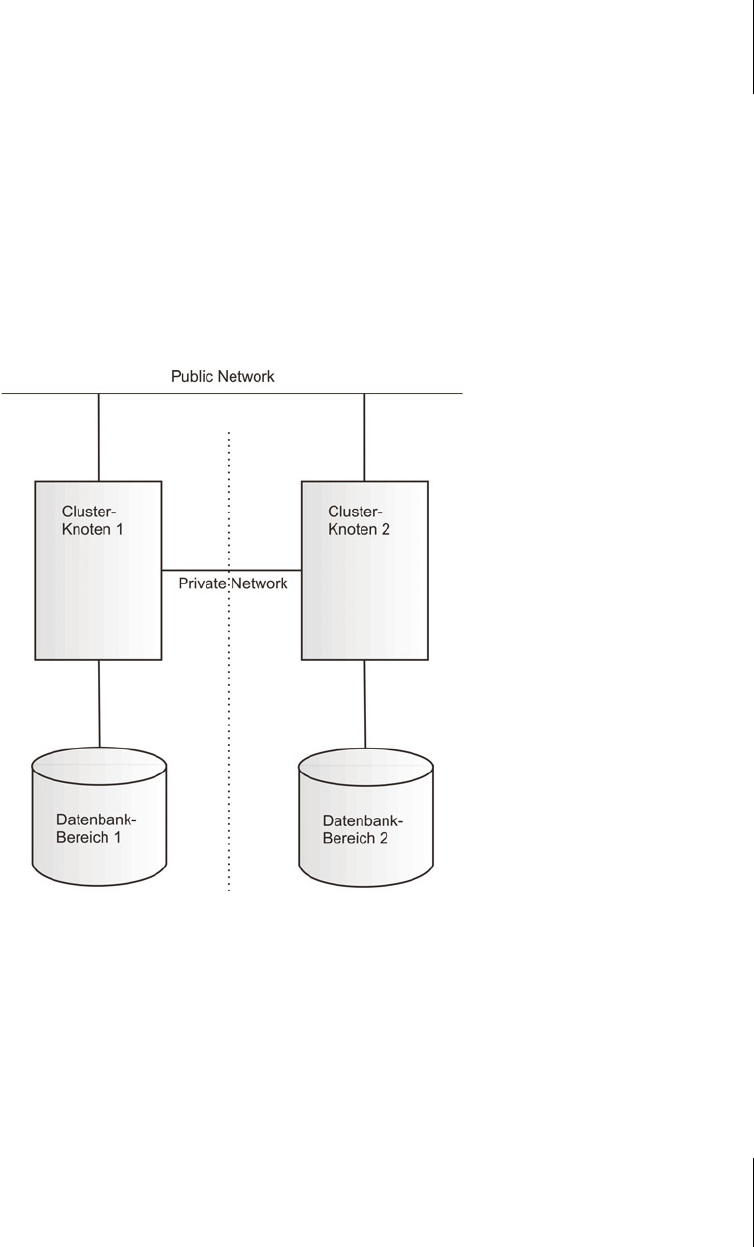
쐽 In einer Shared Nothing-Architektur verwendet jeder Clusterknoten einen
Disk-Bereich, auf den er exklusiv zugreifen kann. Für die Cluster-Datenbank
bedeutet das, dass eine Teilmenge der Datenbank auf einem einzelnen Knoten
zugeordnet und exklusiv von diesem verwaltet und bearbeitet wird.
Abb. 29.1: Eine Shared Nothing Cluster-Architektur
Die Shared Nothing-Architektur besitzt eine Reihe von Nachteilen. So ist zum Bei-
spiel der Datenbankbereich 1 vom Clusterknoten 2 nicht erreichbar. Damit ist die
Failover-Funktionalität stark eingeschränkt. Der Datenbankbereich des verlorenen
gegangenen Knotens muss beim Failover wiederhergestellt und einem anderen
Knoten zugeordnet werden. Dieser Prozess ist jedoch sehr zeitintensiv und häufig
nicht automatisiert.

Kapitel 29
Real Application Clusters
684
Es gibt Shared Nothing-Architekturen, die ein automatisches Failover unterstüt-
zen, indem jeder Datenbereich mindestens zwei Knoten verfügbar gemacht wird.
Dies geschieht durch Replikationsmechanismen, die durch Trigger gesteuert
werden. Ein solches Vorgehen beschleunigt zwar den Failover-Prozess, impliziert
aber auch zusätzliche Probleme. So verschlechtert sich die Performance, da Daten
redundant gespeichert werden. Zusätzlich wird die doppelte Festplattenkapazität
benötigt. Solche Maßnahmen heben die durch das Cluster hinzugewonnene Per-
formance fast vollständig wieder auf und verschlechtern die Skalierbarkeit.
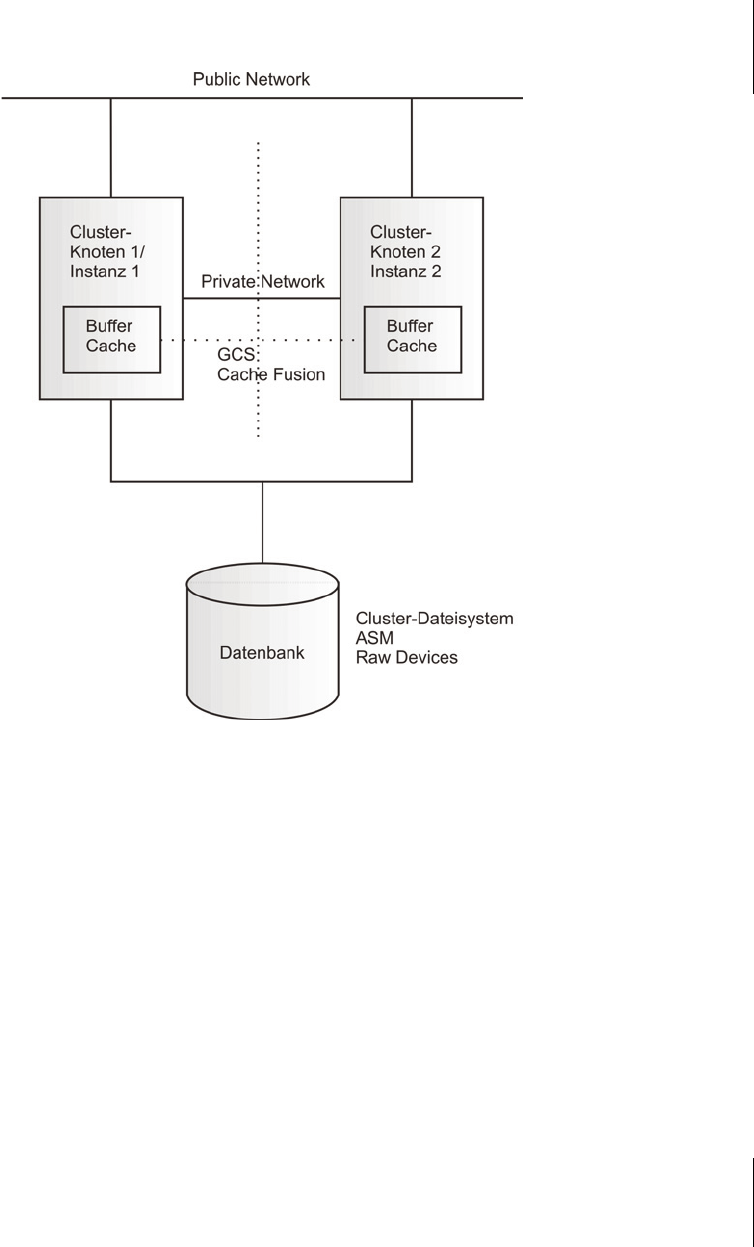
Real Application Clusters basiert auf einer Shared Everything-Architektur. Alle
Daten in der Datenbank stehen allen Cluster-Knoten für das Lesen und Schreiben
zur Verfügung. Da alle Instanzen gemeinsam auf die Daten zugreifen können,
spricht man auch von einer Shared Storage-Architektur. Eine RAC-Datenbank muss
sich deshalb auf einem Cluster-Dateisystem, Raw Devices oder im ASM befinden.
Aus dem Buffer Cache einer Instanz wird damit ein Global Cache über alle Instan-
zen des Clusters. Dieser wird durch den Global Cache Service (GCS) verwaltet.
Datenblöcke können sich im lokalen Buffer Cache auf mehreren Knoten befinden.
Durch den GCS erfolgt die zentrale Verwaltung für die Änderungen, das Sperren
sowie das Lesen und Schreiben auf Disk. Die Kommunikation und die Übertra-
gung von Datenblöcken erfolgt über das Private Network. Die Performance des
globalen Buffer Cache ist damit hauptsächlich von der Performance des Private
Interconnect abhängig.
Die Shared Everything-Architektur bietet für Datenbanken die folgenden Vorteile:
쐽 Fällt ein Clusterknoten aus, ist eine schnelle und automatische Übernahme der
aktuellen Sitzungen durch den oder die überlebenden Knoten möglich. Abhän-
gig von der Größe der offenen Transaktionen kann ein solcher Failover-Prozess
im Sekundenbereich erfolgen. Der Anwender merkt dann in der Regel nicht,
dass ein Failover stattgefunden hat.
쐽 Da es keine feste Zuordnung zwischen Datenblöcken und Clusterknoten gibt,
kann eine Lastverteilung vorgenommen werden. SQL-Anweisungen können
damit nicht nur über mehrere Prozesse, sondern zusätzlich über mehrere Ins-
tanzen parallelisiert werden.
쐽 Die Last der Applikationen kann dynamisch über die Clusterknoten verteilt
werden.
쐽 Es kann ein hohes Maß an Skalierbarkeit erreicht werden. Im Falle einer guten
Verteilung der Dienste können Sie mit Real Application Clusters eine Skalier-
barkeit von 80% erreichen. Das heißt, mit einer Verdoppelung der Anzahl von
Clusterkonten wird ein Zuwachs an Performance von 80% erreicht. Umge-
kehrt gesagt, können Sie bei einer Verdoppelung 80% mehr Workload bei glei-
cher Performance erzeugen.
29.1
Cluster-Architekturen
685
Abb. 29.2: Die Shared Everything-Architektur von Real Application Clusters
Die Real Application Cluster-Architektur, so wie sie in Abbildung 29.3 dargestellt
ist, bietet ein hohes Maß an Ausfallsicherheit für die Instanzen. Es gibt jedoch
noch einen Single Point of Failure, wenn wir voraussetzen, dass die netzwerkseitige
Anbindungen redundant ausgelegt sind, nämlich die Datenbank. Durch eine Spie-
gelung der Dateien der Datenbank auf SAN-Ebene oder mithilfe von ASM wird die
Redundanz auf die Datenbank erweitert.
Mit einer solchen Architektur, wie in Abbildung 29.3 dargestellt, wird ein hohes
Maß an Hochverfügbarkeit erreicht. Die Architektur lässt sich sogar über größere
Entfernungen betreiben, zum Beispiel über zwei Data Center, die mehrere Kilo-
meter auseinander liegen. Damit wird nicht nur eine hohe Verfügbarkeit garan-
tiert, sondern gleichzeitig der Fall abgedeckt, dass eine Seite, etwa durch einen
Terroranschlag, komplett ausgeschaltet wird. Die neuen ASM-Features wie Prefer-
red Mirror Read und ASM Fast Resync unterstützen dieses Konzept.
Get Oracle 12c - Das umfassende Handbuch now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

