7.2 HOW HTTP AND HTML WORKS
This browser paradigm is really one of ‘link–fetch–response’. This string of words nicely reflects the concept behind the paradigm. The idea is that we first link to a resource, usually via the user actually clicking on a hyperlink displayed in the browser, or by entering an address that uniquely points to the linked resource. Linking to the resource causes the browser to initiate a fetch of the linked-to resource, which may be a web page, or some other content type, like a descriptor for a ringtone or a game (later on, we shall look at the download mechanism for media files and games in more detail). The fetch request to a server hopefully causes the server to generate a response.
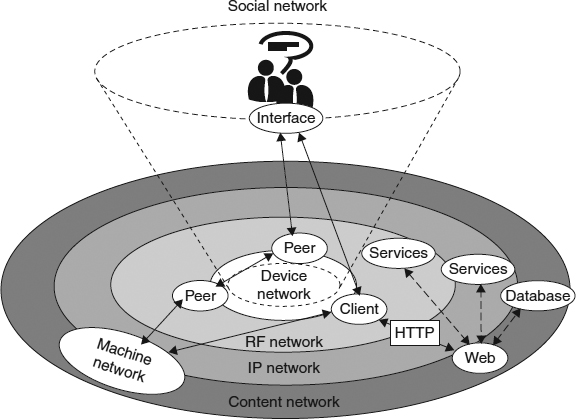
Figure 7.1 Device talking to server via the mobile network or networks.
HTTP was very much designed with this cycle in mind, and by assuming that an application called a browser was on the requesting end doing the fetching, so the details of the mechanism have been designed to facilitate a page browsing metaphor. However, we should caution that the requestor might not be a browser, and hence the general term is user agent, which is the terminology used in the HTTP specification2.
What we assume for HTTP is that the underlying transport mechanism used to shuttle fetch and response messages is the IP. This provides us with the essential means to connect one device with another ...
Get Next Generation Wireless Applications: Creating Mobile Applications in a Web 2.0 and Mobile 2.0 World, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

