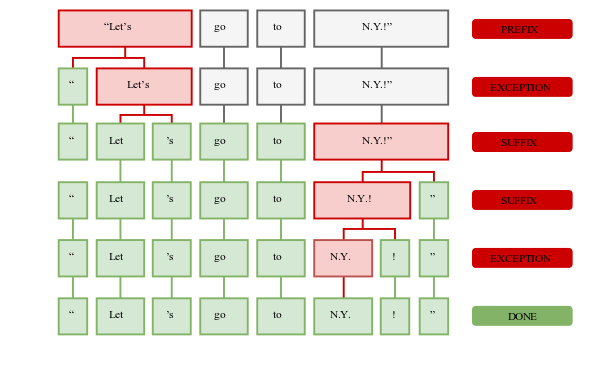
The simplest explanation is from the spaCy docs (spacy-101) itself.
First, the raw text is split on whitespace characters, similar to text.split (' '). Then, the tokenizer processes the text from left to right. On each substring, it performs two checks:
- Does the substring match a tokenizer exception rule? For example, don't does not contain whitespace, but should be split into two tokens, do and n't, while U.K. should always remain one token.
- Can a prefix, suffix, or infix be split off? For example, punctuation such as commas, periods, hyphens, or quotes: