Apache MapReduce is a framework that makes it easier for us to run MapReduce operations on very large, distributed datasets. One of the advantages of Hadoop is a distributed file system that is rack-aware and scalable. The Hadoop job scheduler is intelligent enough to make sure that the computation happens on the nodes where the data is located. This is also a very important aspect as it reduces the amount of network IO.
Let's see how the framework makes it easier to run massively parallel computations with the help of this diagram:
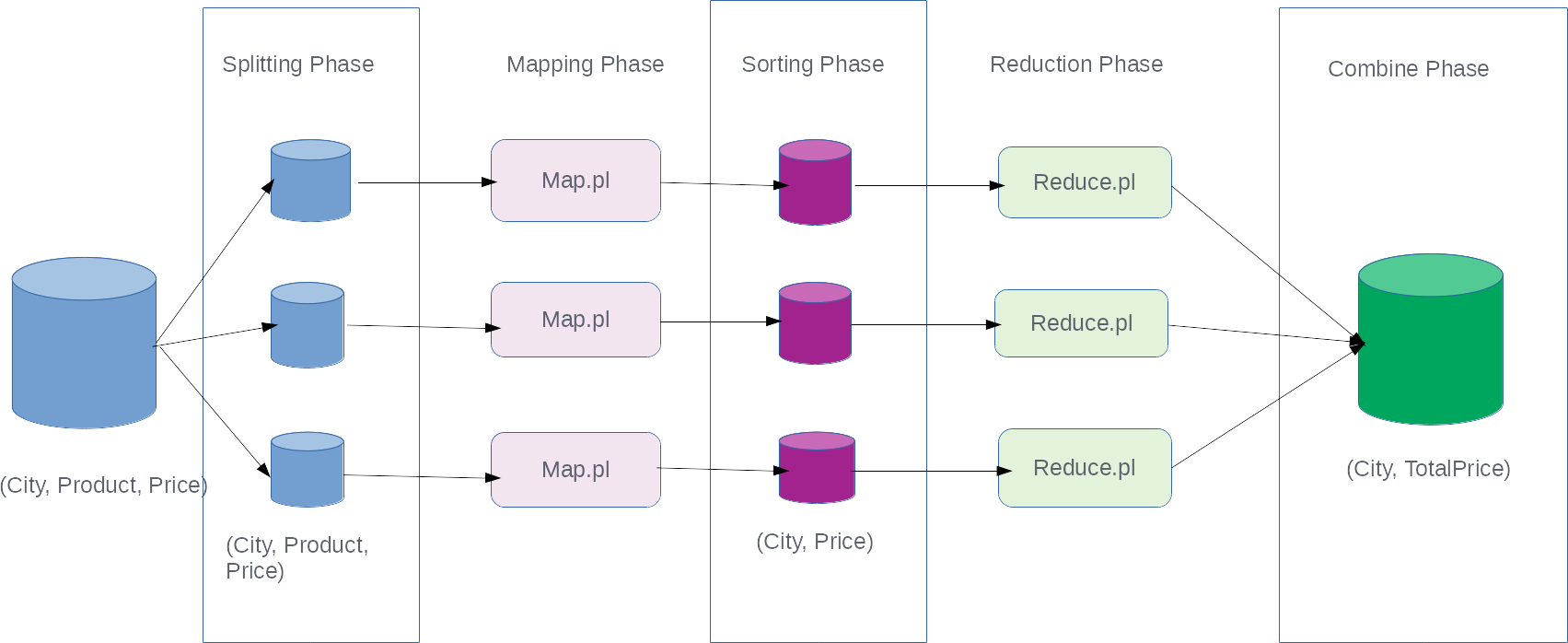
This diagram looks a bit more complicated than the previous diagram, but most of the things ...

