If we want to read data from an HBase table, we have to give an appropriate row ID, and HBase will perform a lookup based on the given row ID. HBase uses the following sorted nested map to return the column value of the row ID: row ID a column family, a column at timestamp, and value. HBase is always deployed on Hadoop. The following is a typical installation:
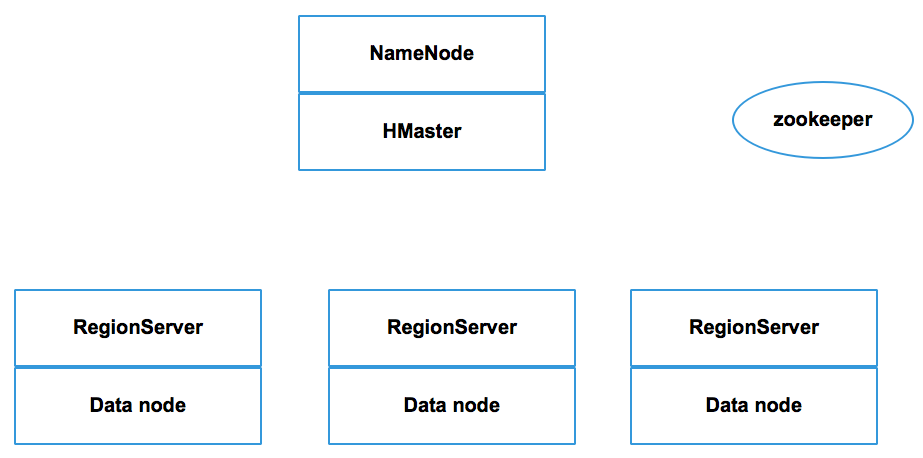
It is a master server of the HBase cluster and is responsible for the administration, monitoring, and management of RegionServers, such as assignment of regions to RegionServer, region splits, and so on. In a distributed cluster, the HMaster typically runs on the Hadoop ...

