Preface
The Web is more a social creation than a technical one.
I designed it for a social effect—to help people work together—and not as a technical toy. The ultimate goal of the Web is to support and improve our weblike existence in the world. We clump into families, associations, and companies. We develop trust across the miles and distrust around the corner.
Tim Berners-Lee, Weaving the Web (Harper)
A Note from Matthew Russell
It’s been more than five years since I put the final finishing touches on the manuscript for Mining the Social Web, 2nd Edition, and a lot has changed since then. I have lived and learned a lot of new things, technology has continued to evolve at a blistering pace, and the social web itself has matured to such an extent that governments are now formulating legal policy around how data can be collected, shared, and used.
Knowing that my own schedule could not possibly allow for the immense commitment needed to produce a new edition to freshen up and expand on the content, but believing wholeheartedly that there has never been a better moment for the message this book delivers, I knew that it was time to find a coauthor to help deliver it to the next wave of entrepreneurs, technologists, and hackers who are curious about mining the social web. It took well over a year for me to find a coauthor who shared the same passion for the subject and possessed the skill and determination that’s required to write a book.
I can’t even begin to tell you how grateful I am for Mikhail Klassen and his incredible contributions in keeping this labor of love alive for many more years to come. In the pages ahead, you’ll see that he’s done a tremendous job of modernizing the code, improving the accessibility of its runtime environment, and expanding the content with a substantial new chapter—all in addition to editing and freshening up the overall manuscript itself and enthusiastically carrying the mantle forward for the next wave of entrepreneurs, technologists, and hackers who are curious about mining the social web.
README.1st
This book has been carefully designed to provide an incredible learning experience for a particular target audience, and in order to avoid any unnecessary confusion about its scope or purpose by way of disgruntled emails, bad book reviews, or other misunderstandings that can come up, the remainder of this preface tries to help you determine whether you are part of that target audience. As busy professionals, we consider our time our most valuable asset, and we want you to know right from the beginning that we believe that the same is true of you. Although we often fail, we really do try to honor our neighbors above ourselves as we walk out this life, and this preface is our attempt to honor you, the reader, by making it clear whether or not this book can meet your expectations.
Managing Your Expectations
Some of the most basic assumptions this book makes about you as a reader are that you want to learn how to mine data from popular social web properties, avoid technology hassles when running sample code, and have lots of fun along the way. Although you could read this book solely for the purpose of learning what is possible, you should know up front that it has been written in such a way that you really could follow along with the many exercises and become a data miner once you’ve completed the few simple steps to set up a development environment. If you’ve done some programming before, you should find that it’s relatively painless to get up and running with the code examples. Even if you’ve never programmed before, if you consider yourself the least bit tech-savvy I daresay that you could use this book as a starting point to a remarkable journey that will stretch your mind in ways that you probably haven’t even imagined yet.
To fully enjoy this book and all that it has to offer, you need to be interested in the vast possibilities for mining the rich data tucked away in popular social websites such as Twitter, Facebook, LinkedIn, and Instagram, and you need to be motivated enough to install Docker, use it to run this book’s virtual machine experience, and follow along with the book’s example code in the Jupyter Notebook, a fantastic web-based tool that features all of the examples for every chapter. Executing the examples is usually as easy as pressing a few keys, since all of the code is presented to you in a friendly user interface.
This book will teach you a few things that you’ll be thankful to learn and will add a few indispensable tools to your toolbox, but perhaps even more importantly, it will tell you a story and entertain you along the way. It’s a story about data science involving social websites, the data that’s tucked away inside of them, and some of the intriguing possibilities of what you (or anyone else) could do with this data.
If you were to read this book from cover to cover, you’d notice that this story unfolds on a chapter-by-chapter basis. While each chapter roughly follows a predictable template that introduces a social website, teaches you how to use its API to fetch data, and presents some techniques for data analysis, the broader story the book tells crescendos in complexity. Earlier chapters in the book take a little more time to introduce fundamental concepts, while later chapters systematically build upon the foundation from earlier chapters and gradually introduce a broad array of tools and techniques for mining the social web that you can take with you into other aspects of your life as a data scientist, analyst, visionary thinker, or curious reader.
Some of the most popular social websites have transitioned from fad to mainstream to household names over recent years, changing the way we live our lives on and off the web and enabling technology to bring out the best (and sometimes the worst) in us. Generally speaking, each chapter of this book interlaces slivers of the social web along with data mining, analysis, and visualization techniques to explore data and answer the following representative questions:
-
Who knows whom, and which people are common to their social networks?
-
How frequently are particular people communicating with one another?
-
Which social network connections generate the most value for a particular niche?
-
How does geography affect your social connections in an online world?
-
Who are the most influential/popular people in a social network?
-
What are people chatting about (and is it valuable)?
-
What are people interested in based upon the human language that they use in a digital world?
The answers to these basic kinds of questions often yield valuable insights and present (sometimes lucrative) opportunities for entrepreneurs, social scientists, and other curious practitioners who are trying to understand a problem space and find solutions. Activities such as building a turnkey killer app from scratch to answer these questions, venturing far beyond the typical usage of visualization libraries, and constructing just about anything state-of-the-art are not within the scope of this book. You’ll be really disappointed if you purchase this book because you want to do one of those things. However, the book does provide the fundamental building blocks to answer these questions and provide a springboard that might be exactly what you need to build that killer app or conduct that research study. Skim a few chapters and see for yourself. This book covers a lot of ground.
One important thing to note is that APIs are constantly changing. Social media hasn’t been around all that long, and even the platforms that appear the most established today are still adapting to how people use them and confronting new threats to security and privacy. As such, the interfaces between our code and their platforms (the APIs) are liable to change too, which means that the code examples provided in this book may not work as intended in the future. We’ve tried to create realistic examples that are useful for general purposes and app developers, and therefore some of them will require submitting an application for review and approval. We’ll do our best to flag those with notes, but be advised API terms of service can change at any time. Nevertheless, as long as your app abides by the terms of service, it will likely get approved, so it’s worth the effort.
Python-Centric Technology
This book intentionally takes advantage of the Python programming language for all of its example code. Python’s intuitive syntax, amazing ecosystem of packages that trivialize API access and data manipulation, and core data structures that are practically JSON make it an excellent teaching tool that’s powerful yet also very easy to get up and running. As if that weren’t enough to make Python both a great pedagogical choice and a very pragmatic choice for mining the social web, there’s the Jupyter Notebook, a powerful, interactive code interpreter that provides a notebook-like user experience from within your web browser and combines code execution, code output, text, mathematical typesetting, plots, and more. It’s difficult to imagine a better user experience for a learning environment, because it trivializes the problem of delivering sample code that you as the reader can follow along with and execute with no hassles. Figure P-1 provides an illustration of the Jupyter Notebook experience, demonstrating the dashboard of notebooks for each chapter of the book. Figure P-2 shows a view of one notebook.
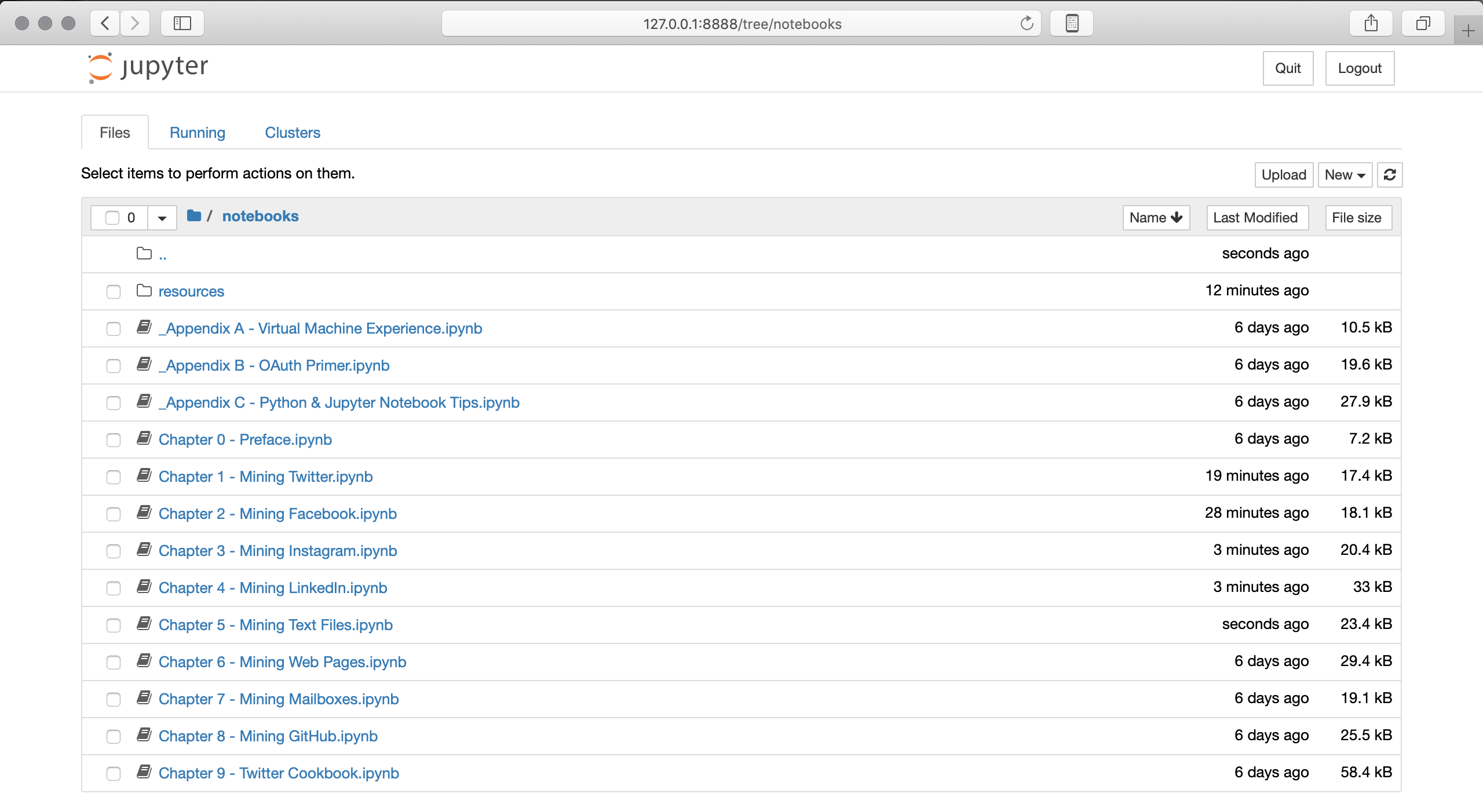
Figure P-1. Overview of the Jupyter Notebook; a dashboard of notebooks
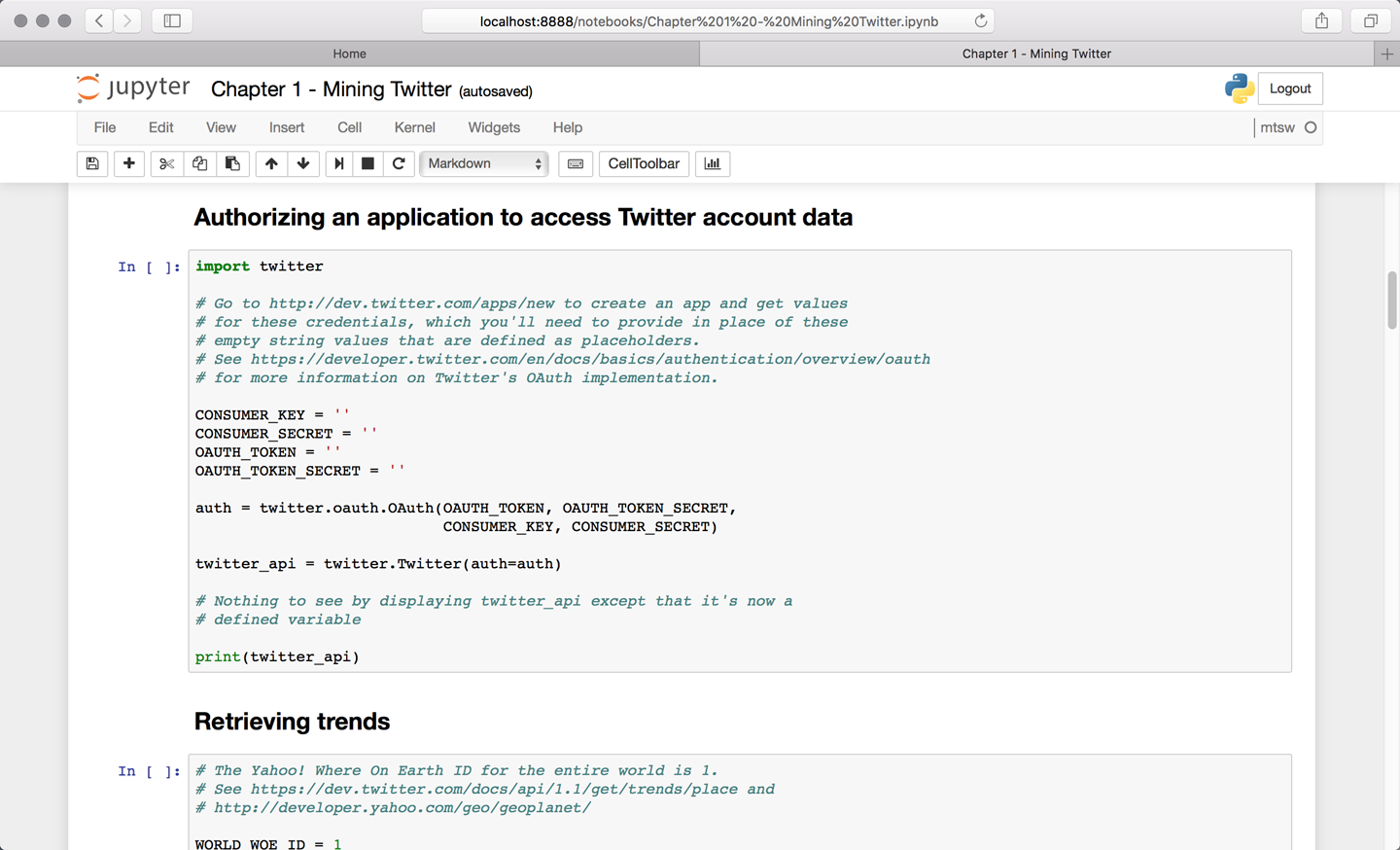
Figure P-2. The “Chapter 1 - Mining Twitter” notebook
Every chapter in this book has a corresponding Jupyter Notebook with example code that makes it a pleasure to study the code, tinker around with it, and customize it for your own purposes. If you’ve done some programming but have never seen Python syntax, skimming ahead a few pages should hopefully be all the confirmation that you need. Excellent documentation is available online, and the official Python tutorial is a good place to start if you’re looking for a solid introduction to Python as a programming language. This book’s Python source code has been overhauled for the third edition to be written in Python 3.6.
The Jupyter Notebook is great, but if you’re new to the Python programming world, advising you to just follow the instructions online to configure your development environment would be a bit counterproductive (and possibly even rude). To make your experience with this book as enjoyable as possible, a turnkey virtual machine is available that has the Jupyter Notebook and all of the other dependencies that you’ll need to follow along with the examples from this book preinstalled and ready to go. All that you have to do is follow a few simple steps, and in about 15 minutes, you’ll be off to the races. If you have a programming background, you’ll be able to configure your own development environment, but our hope is that we’ll convince you that the virtual machine experience is a better starting point.
Note
See Appendix A for more detailed information on the virtual machine experience for this book. Appendix C is also worth your attention: it presents some Jupyter Notebook tips and common Python programming idioms that are used throughout this book’s source code.
Whether you’re a Python novice or a guru, the book’s latest bug-fixed source code and accompanying scripts for building the virtual machine are available on GitHub, a social Git repository that will always reflect the most up-to-date example code available. The hope is that social coding will enhance collaboration between like-minded folks who want to work together to extend the examples and hack away at fascinating problems. Hopefully, you’ll fork, extend, and improve the source—and maybe even make some new friends or acquaintances along the way.
Note
The official GitHub repository containing the latest and greatest bug-fixed source code for this book is available at http://bit.ly/Mining-the-Social-Web-3E.
Improvements to the Third Edition
As mentioned earlier in this preface, the third edition of this book has brought on Mikhail Klassen as a coauthor.
Technology changes fast, and social media platforms along with it. When we began revising the second edition, it became clear that the book would benefit from an update to reflect all the changes that were taking place. The first and most obvious change was to update the code from Python 2.7 to a more recent version of Python 3.0+. While there are still diehard users of Python 2.7, moving to Python 3 has a lot of advantages, not the least of which is better support for Unicode. When dealing with social media data, which often includes emojis and text from other alphabets, having good support for Unicode is critical.
In a climate of increasing concerns over user privacy, social media platforms are changing their APIs to better safeguard user information by limiting the extent to which third-party applications can access their platforms—even applications that have been vetted and approved.
Some of the code examples in earlier editions of this book simply didn’t work anymore because data access restrictions had changed. In these cases, we created new examples within those constraints, but that nevertheless illustrated something interesting.
At other times, social media platforms changed their APIs in ways that broke the code examples in this book, but the same data was still accessible, just in a different way. By spending time reading the developer documentation of each platform, the code examples from the second edition were recreated using the new API calls.
Perhaps the largest change made to the third edition was the addition of the chapter on mining Instagram (Chapter 3). Instagram is a hugely popular platform that we felt couldn’t be left out of the text. This also gave us an opportunity to showcase some technologies useful in performing data mining on image data, specifically the application of deep learning. That subject can quickly get extremely technical, but we introduce the basics in an accessible way, and then apply a powerful computer vision API to do the heavy lifting for us. The end result is that in a few lines of Python, you have a system that can look at photos posted to Instagram and tell you about what’s in them.
Another substantial change was that Chapter 5 was heavily edited and reframed as a chapter on mining text files as opposed to being rooted in the context of Google+. The fundamentals for this chapter are unchanged, and the content is more explicitly generalizable to any API response that returns human language data.
A few other technology decisions were made along the way that some readers may disagree with. In the chapter on mining mailboxes (Chapter 7), the second edition presented the use of MongoDB, a type of database, for storing and querying email data. This type of system makes a lot of sense, but unless you are running the code for this book inside a Docker container, installing a database system creates some extra overhead. Also, we wanted to show more examples of how to use the pandas library, introduced in Chapter 2. This library has quickly become one of the most important in the data scientist’s toolbox because of how easy it makes the manipulation of tabular data. Leaving it out of a book on data mining seemed wrong. Nevertheless, we kept the MongoDB examples that are part of Chapter 9, and if you are using the Docker container for this book, it should be breeze anyway.
Finally, we removed what was previously Chapter 9 (Mining the Semantic Web). This chapter was originally drafted as part of the first edition in 2010, and the overall utility of it, given the direction that the social web has generally taken, seemed questionable nearly a decade later.
Note
Constructive feedback is always welcome, and we’d enjoy hearing from you by way of a book review, tweet to @SocialWebMining, or comment on Mining the Social Web’s Facebook wall. The book’s official website and the blog that extends the book with longer-form content are at http://MiningTheSocialWeb.com.
The Ethical Use of Data Mining
At the time of this writing, the provisions of the General Data Protection Regulation (GDPR) have just come into full effect in the European Union (EU). The regulation stipulates how companies must protect the privacy of the citizens and residents of the EU, giving users more control over their data. Because companies all around the world do business in Europe, virtually all of them have been forced to make changes to their terms of use and privacy policies, or else face penalties. The GDPR sets a new global baseline for privacy; one that will hopefully be a positive influence on companies everywhere, even if they conduct no business in Europe.
The third edition of Mining the Social Web comes amidst a climate of greater concern over the ethical use of data and user privacy. Around the world, data brokers are collecting, collating, and reselling data about internet users: their consumer behavior, preferences, political leanings, postal codes, income brackets, ages, etc. Sometimes, within certain jurisdictions, this activity is entirely legal. Given enough of this type of data, it becomes possible to manipulate behavior by exploiting human psychology through highly targeted messaging, interface design, or misleading information.
As the authors of a book about how to mine data from social media and the web, and have fun doing it, we are fully aware of the irony. We are also aware that what is legal is not, by necessity, therefore ethical. Data mining, by itself, is a collection of practices using particular technologies that are, by themselves, morally neutral. Data mining can be used in a lot of tremendously helpful ways. An example that I (Mikhail Klassen) often turn to is the work of the UN Global Pulse, an initiative by the United Nations to use big data for global good. For example, by using social media data, it is possible to measure sentiment toward development initiatives (such as a vaccination campaign) or toward a country’s political process. By analyzing Twitter data, it may be possible to respond faster to an emerging crisis, such as an epidemic or natural disaster.
The examples need not be humanitarian. Data mining is being used in exciting ways to develop personalized learning technologies for education and training, and some commercial efforts by startups. In other domains, data mining is used to predict pandemics, discover new drugs, or determine which genes may be responsible for particular diseases or when to perform preventative maintenance on an engine. By responsibly using data and respecting user privacy, it is possible to use data mining ethically, while still turning a profit and achieving amazing things.
A relatively small number of technology companies currently have an incredible amount of data about people’s lives. They are under increasing societal pressure and government regulation to use this data responsibly. To their credit, many are updating their policies as well as their APIs. By reading this book, you will gain a better understanding of just what kind of data a third-party developer (such as yourself) can obtain from these platforms, and you will learn about many tools used to turn data into knowledge. You will also, we hope, gain a greater appreciation for how technologies may be abused. Then, as an informed citizen, you can advocate for sensible laws to protect everyone’s privacy.
Conventions Used in This Book
This book is extensively hyperlinked, which makes it ideal to read in an electronic format such as a DRM-free PDF that can be purchased directly from O’Reilly as an ebook. Purchasing it as an ebook through O’Reilly also guarantees that you will get automatic updates for the book as they become available. The links have been shortened using the bit.ly service for the benefit of customers with the printed version of the book. All hyperlinks have been vetted.
The following typographical conventions are used in this book:
- Italic
-
Indicates new terms, URLs, email addresses, filenames, and file extensions.
Constant width-
Indicates program listings, and is used within paragraphs to refer to program elements such as variable or function names, databases, data types, environment variables, statements, and keywords.
Constant width bold-
Shows commands or other text that should be typed literally by the user. Also occasionally used for emphasis in code listings.
Constant width italic-
Shows text that should be replaced with user-supplied values or values determined by context.
Note
This icon signifies a general note.
Tip
This icon signifies a tip or suggestion.
Caution
This icon indicates a warning or caution.
Using Code Examples
The latest sample code for this book is maintained on GitHub at http://bit.ly/Mining-the-Social-Web-3E, the official code repository for the book. You are encouraged to monitor this repository for the latest bug-fixed code as well as extended examples by the author and the rest of the social coding community. If you are reading a paper copy of this book, there is a possibility that the code examples in print may not be up to date, but so long as you are working from the book’s GitHub repository, you will always have the latest bug-fixed example code. If you are taking advantage of this book’s virtual machine experience, you’ll already have the latest source code, but if you are opting to work in your own development environment, be sure to take advantage of the ability to download a source code archive directly from the GitHub repository.
Note
Please log issues involving example code to the GitHub repository’s issue tracker as opposed to the O’Reilly catalog’s errata tracker. As issues are resolved in the source code on GitHub, updates are published back to the book’s manuscript, which is then periodically provided to readers as an ebook update.
In general, you may use the code in this book in your programs and documentation. You do not need to contact us for permission unless you’re reproducing a significant portion of the code. For example, writing a program that uses several chunks of code from this book does not require permission. Selling or distributing a CD-ROM of examples from O’Reilly books does require permission. Answering a question by citing this book and quoting example code does not require permission. Incorporating a significant amount of example code from this book into your product’s documentation does require permission.
We require attribution according to the OSS license under which the code is released. An attribution usually includes the title, author, publisher, and ISBN. For example: “Mining the Social Web, 3rd Edition, by Matthew A. Russell and Mikhail Klassen. Copyright 2018 Matthew A. Russell and Mikhail Klassen, 978-1-491-98504-5.”
If you feel your use of code examples falls outside fair use or the permission given above, feel free to contact us at permissions@oreilly.com.
O’Reilly Online Learning
Note
For more than 40 years, O’Reilly Media has provided technology and business training, knowledge, and insight to help companies succeed.
Our unique network of experts and innovators share their knowledge and expertise through books, articles, and our online learning platform. O’Reilly’s online learning platform gives you on-demand access to live training courses, in-depth learning paths, interactive coding environments, and a vast collection of text and video from O’Reilly and 200+ other publishers. For more information, visit http://oreilly.com.
How to Contact Us
Please address comments and questions concerning this book to the publisher:
- O’Reilly Media, Inc.
- 1005 Gravenstein Highway North
- Sebastopol, CA 95472
- 800-998-9938 (in the United States or Canada)
- 707-829-0515 (international or local)
- 707-829-0104 (fax)
We have a web page for this book, where we list non-code-related errata and additional information. You can access this page at http://bit.ly/mining-social-web-3e.
Any errata related to the sample code should be submitted as a ticket through GitHub’s issue tracker at http://github.com/ptwobrussell/Mining-the-Social-Web/issues.
To comment or ask technical questions about this book, send email to bookquestions@oreilly.com.
For news and more information about our books and courses, see our website at http://www.oreilly.com.
Find us on Facebook: http://facebook.com/oreilly
Follow us on Twitter: http://twitter.com/oreillymedia
Watch us on YouTube: http://www.youtube.com/oreillymedia
Acknowledgments for the Third Edition
I (Mikhail Klassen) would not have been involved in this book if not for a chance meeting with Susan Conant from O’Reilly Media. She saw the potential for the collaboration with Matthew Russell on the third edition of this book, and it has been great to work on this project. The editorial team at O’Reilly has been great to work with, and I’d like to thank Tim McGovern, Ally MacDonald, and Alicia Young. Connected with this book project is a series of video lectures produced by O’Reilly, and I’d also like to thank the team that worked with me on these: David Cates, Peter Ong, Adam Ritz, and Amanda Porter.
Being only able to work on the project evenings and weekends means time taken away from family, so thank you to my wife, Sheila, for understanding.
Acknowledgments for the Second Edition
I (Matthew Russell) will reiterate from my acknowledgments for the first edition that writing a book is a tremendous sacrifice. The time that you spend away from friends and family (which happens mostly during an extended period on nights and weekends) is quite costly and can’t be recovered, and you really do need a certain amount of moral support to make it through to the other side with relationships intact. Thanks again to my very patient friends and family, who really shouldn’t have tolerated me writing another book and probably think that I have some kind of chronic disorder that involves a strange addiction to working nights and weekends. If you can find a rehab clinic for people who are addicted to writing books, I promise I’ll go and check myself in.
Every project needs a great project manager, and my incredible editor Mary Treseler and her amazing production staff were a pleasure to work with on this book (as always). Writing a technical book is a long and stressful endeavor, to say the least, and it’s a remarkable experience to work with professionals who are able to help you make it through that exhausting journey and deliver a beautifully polished product that you can be proud to share with the world. Kristen Brown, Rachel Monaghan, and Rachel Head truly made all the difference in taking my best efforts to an entirely new level of professionalism.
The detailed feedback that I received from my very capable editorial staff and technical reviewers was also nothing short of amazing. Ranging from very technically oriented recommendations to software-engineering-oriented best practices with Python to perspectives on how to best reach the target audience as a mock reader, the feedback was beyond anything I could have ever expected. The book you are about to read would not be anywhere near the quality that it is without the thoughtful peer review feedback that I received. Thanks especially to Abe Music, Nicholas Mayne, Robert P.J. Day, Ram Narasimhan, Jason Yee, and Kevin Makice for your very detailed reviews of the manuscript. It made a tremendous difference in the quality of this book, and my only regret is that we did not have the opportunity to work together more closely during this process. Thanks also to Tate Eskew for introducing me to Vagrant, a tool that has made all the difference in establishing an easy-to-use and easy-to-maintain virtual machine experience for this book.
I also would like to thank my many wonderful colleagues at Digital Reasoning for the enlightening conversations that we’ve had over the years about data mining and topics in computer science, and other constructive dialogues that have helped shape my professional thinking. It’s a blessing to be part of a team that’s so talented and capable. Thanks especially to Tim Estes and Rob Metcalf, who have been supportive of my work on time-consuming projects (outside of my professional responsibilities to Digital Reasoning) like writing books.
Finally, thanks to every single reader or adopter of this book’s source code who provided constructive feedback over the lifetime of the first edition. Although there are far too many of you to name, your feedback has shaped this second edition in immeasurable ways. I hope that this second edition meets your expectations and finds itself among your list of useful books that you’d recommend to a friend or colleague.
Acknowledgments from the First Edition
To say the least, writing a technical book takes a ridiculous amount of sacrifice. On the home front, I gave up more time with my wife, Baseeret, and daughter, Lindsay Belle, than I’m proud to admit. Thanks most of all to both of you for loving me in spite of my ambitions to somehow take over the world one day. (It’s just a phase, and I’m really trying to grow out of it—honest.)
I sincerely believe that the sum of your decisions gets you to where you are in life (especially professional life), but nobody could ever complete the journey alone, and it’s an honor to give credit where credit is due. I am truly blessed to have been in the company of some of the brightest people in the world while working on this book, including a technical editor as smart as Mike Loukides, a production staff as talented as the folks at O’Reilly, and an overwhelming battery of eager reviewers as amazing as everyone who helped me to complete this book. I especially want to thank Abe Music, Pete Warden, Tantek Celik, J. Chris Anderson, Salvatore Sanfilippo, Robert Newson, DJ Patil, Chimezie Ogbuji, Tim Golden, Brian Curtin, Raffi Krikorian, Jeff Hammerbacher, Nick Ducoff, and Cameron Marlowe for reviewing material or making particularly helpful comments that absolutely shaped its outcome for the best. I’d also like to thank Tim O’Reilly for graciously allowing me to put some of his Twitter and Google+ data under the microscope; it definitely made those chapters much more interesting to read than they otherwise would have been. It would be impossible to recount all of the other folks who have directly or indirectly shaped my life or the outcome of this book.
Finally, thanks to you for giving this book a chance. If you’re reading this, you’re at least thinking about picking up a copy. If you do, you’re probably going to find something wrong with it despite my best efforts; however, I really do believe that, in spite of the few inevitable glitches, you’ll find it an enjoyable way to spend a few evenings/weekends and you’ll manage to learn a few things somewhere along the line.
Get Mining the Social Web, 3rd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

