Introducing the web scraper
Let's review a simple web scraper architecture:
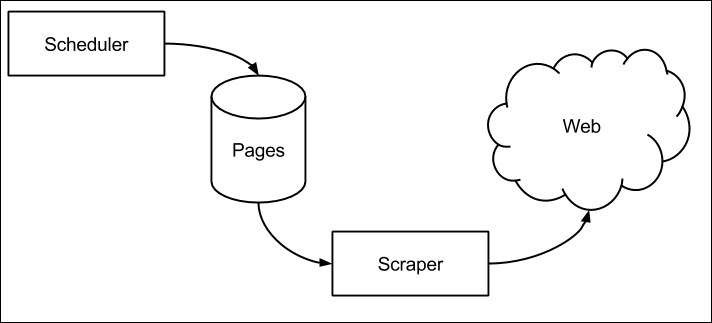
Scheduler
The web changes often. It is a huge and dynamic beast. The scheduler is responsible to make sure that the scraper will always represent data that is fresh and not stale. It is free to do so by deciding at what rate to scrape it for each website or the page that is being scraped; in other words, when is the next scraping going to happen.
In reality, you would want the scheduler to feed from a persistent data store that holds all sources and their upcoming scraping time.
For example, you could hold a record that specifies that the website acme.org will have to be scraped ...
Get Mastering RabbitMQ now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

