The k-means clustering with countries
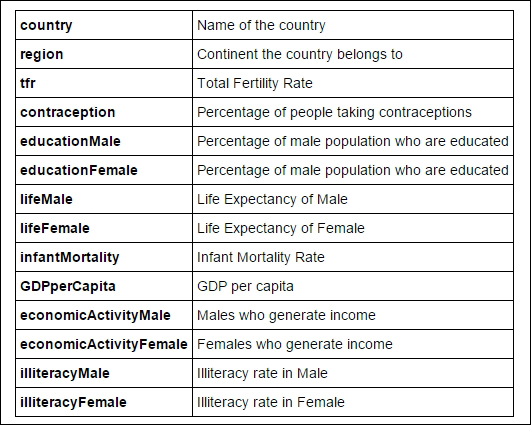
We have UN data on different countries of the world with regard to education of people to Gross Domestic Product. We'll use this data to bucket the countries based on their development. Here are the descriptions of the columns:
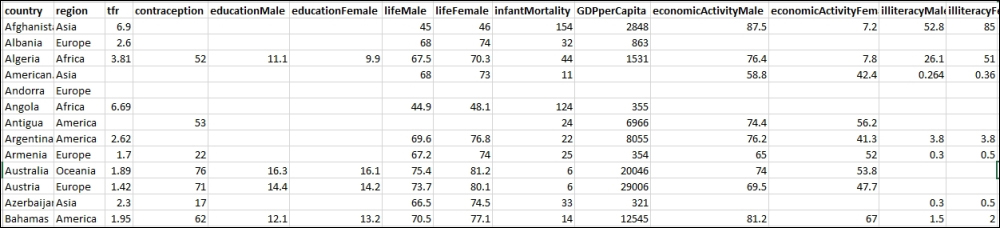
Here is a screenshot of the data:
Lets see the data type of each column:
>>> df = pd.read_csv('./Data/UN.csv') >>> # print the raw column information plus summary header >>> print('----') >>> # look at the types of each column explicitly >>> [(col, type(df[col][0])) for col in df.columns] ...
Get Mastering Python for Data Science now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

