Chapter 1. Advanced Regular Expressions
Regular expressions, or just regexes, are at the core of Perlâs text processing, and certainly are one of the features that made Perl so popular. All Perl programmers pass through a stage where they try to program everything as regexes, and when thatâs not challenging enough, everything as a single regex. Perlâs regexes have many more features than I can, or want, to present here, so I include those advanced features I find most useful and expect other Perl programmers to know about without referring to perlre, the documentation page for regexes.
Readable Regexes, /x and (?#â¦)
Regular expressions have a much-deserved reputation of being hard to read. Regexes have their own terse language that uses as few characters as possible to represent virtually infinite numbers of possibilities, and thatâs just counting the parts that most people use everyday.
Luckily for other people, Perl gives me the opportunity to make my regexes much easier to read. Given a little bit of formatting magic, not only will others be able to figure out what Iâm trying to match, but a couple weeks later, so will I. We touched on this lightly in Learning Perl, but itâs such a good idea that Iâm going to say more about it. Itâs also in Perl Best Practices.
When I add the /x flag to
either the match or substitution operators, Perl ignores
literal whitespace in the pattern. This means that I spread out the parts
of my pattern to make the pattern more discernible. Gisle Aasâs HTTP::Date module parses a date by trying several different regexes.
Hereâs one of his regular expressions, although Iâve modified it to appear
on a single line, arbitrarily wrapped to fit on this page:
/^(\d\d?)(?:\s+|[-\/])(\w+)(?:\s+|[-\/])(\d+)(?:(?:\s+|:)
(\d\d?):(\d\d)(?::(\d\d))?)?\s*([-+]?\d{2,4}|(?![APap][Mm]\b)
[A-Za-z]+)?\s*(?:\(\w+\))?\s*$/Quick: Can you tell which one of the many date formats that parses?
Me neither. Luckily, Gisle uses the /x
flag to break apart the regex and add comments to show me what each piece
of the pattern does. With /x, Perl
ignores literal whitespace and Perl-style comments inside the regex.
Hereâs Gisleâs actual code, which is much easier to understand:
/^
(\d\d?) # day
(?:\s+|[-\/])
(\w+) # month
(?:\s+|[-\/])
(\d+) # year
(?:
(?:\s+|:) # separator before clock
(\d\d?):(\d\d) # hour:min
(?::(\d\d))? # optional seconds
)? # optional clock
\s*
([-+]?\d{2,4}|(?![APap][Mm]\b)[A-Za-z]+)? # timezone
\s*
(?:\(\w+\))? # ASCII representation of timezone in parens.
\s*$
/xUnder /x, to match whitespace I
have to specify it explicitly, using \s, which matches any whitespace; any of
\f\r\n\t\R; or their octal or
hexadecimal sequences, such as \040 or
\x20 for a literal space. Likewise, if I need a literal
hash symbol, #, I have to escape it
too: \#.
I donât have to use /x to put
comments in my regex. The (?#COMMENT)
sequence does that for me. It probably doesnât make the regex any more
readable at first glance, though. I can mark the parts of a string right
next to the parts of the pattern that represent it. Just because you can
use (?#) doesnât mean you should. I think the patterns are much easier to
read with /x:
my $isbn = '0-596-10206-2'; $isbn =~ m/\A(\d+)(?#group)-(\d+)(?#publisher)-(\d+)(?#item)-([\dX])\z/i; print <<"HERE"; Group code: $1 Publisher code: $2 Item: $3 Checksum: $4 HERE
Those are just Perl features, though. Itâs still up to me to present the regex in a way that other people can understand, just as I should do with any other code.
These explicated regexes can take up quite a bit of screen space,
but I can hide them like any other code. I can create the regex as a
string or create a regular expression object with qr// and return
it:
sub isbn_regex {
qr/ \A
(\d+) #group
-
(\d+) #publisher
-
(\d+) #item
-
([\dX])
\z
/ix;
}I could get the regex and interpolate it into the match or substitution operators:
my $regex = isbn_regex();
if( $isbn =~ m/$regex/ ) {
print "Matched!\n";
}Since I return a regular expression object, I can bind to it directly to perform a match:
my $regex = isbn_regex();
if( $isbn =~ $regex ) {
print "Matched!\n";
}But, I can also just skip the $regex variable and bind to the return value
directly. It looks odd, but it works:
if( $isbn =~ isbn_regex() ) {
print "Matched!\n";
}If I do that, I can move all of the actual regular expressions out of the way. Not only that, I now should have a much easier time testing the regular expressions since I can get to them much more easily in the test programs.
Global Matching
In Learning Perl we told you about the /g flag that you can
use to make all possible substitutions, but itâs more useful than that. I
can use it with the match operator, where it does different things in
scalar and list context. We told you that the match operator returns true
if it matches and false otherwise. Thatâs still true (we wouldnât have
lied to you), but itâs not just a Boolean value. The list context behavior
is the most useful. With the /g flag,
the match operator returns all of the captures:
$_ = "Just another Perl hacker,"; my @words = /(\S+)/g; # "Just" "another" "Perl" "hacker,"
Even though I only have one set of captures in my regular expression, it makes as many matches as it can. Once it makes a match, Perl starts where it left off and tries again. Iâll say more on that in a moment. I often run into another Perl idiom thatâs closely related to this, in which I donât want the actual matches, but just a count:
my $word_count = () = /(\S+)/g;
This uses a little-known but important rule: the result of a
list assignment is the number of elements in the list on the
righthand side. In this case, thatâs the number of elements the match
operator returns. This only works for a list assignment, which is
assigning from a list on the righthand side to a list on the lefthand
side. Thatâs why I have the extra () in
there.
In scalar context, the /g flag
does some extra work we didnât tell you about earlier. During a successful
match, Perl remembers its position in the string, and when I match against
that same string again, Perl starts where it left off in that string. It
returns the result of one application of the pattern to the string:
$_ = "Just another Perl hacker,";
my @words = /(\S+)/g; # "Just" "another" "Perl" "hacker,"
while( /(\S+)/g ) { # scalar context
print "Next word is '$1'\n";
}When I match against that same string again, Perl gets the next match:
Next word is 'Just' Next word is 'another' Next word is 'Perl' Next word is 'hacker,'
I can even look at the match position as I go along. The built-in pos() operator
returns the match position for the string I give it (or $_ by default). Every string maintains its own
position. The first position in the string is 0, so pos()
returns undef when it doesnât find a
match and has been reset, and this only works when Iâm using the /g flag (since thereâs no point in pos() otherwise):
$_ = "Just another Perl hacker,"; my $pos = pos( $_ ); # same as pos() print "I'm at position [$pos]\n"; # undef /(Just)/g; $pos = pos(); print "[$1] ends at position $pos\n"; # 4
When my match fails, Perl resets the value of pos() to undef. If I continue matching, Iâll start at the
beginning (and potentially create an endless loop):
my( $third_word ) = /(Java)/g; print "The next position is " . pos() . "\n";
As a side note, I really hate these print statements where I use the concatenation
operator to get the result of a function call into the output. Perl
doesnât have a dedicated way to interpolate function calls, so I can cheat
a bit. I call the function in an anonymous array constructor, [ ... ], then immediately dereference it by
wrapping @{ ... } around it:
print "The next position is @{ [ pos( $line ) ] }\n";The pos() operator can also be an
lvalue, which is the fancy programming way of saying that I can assign to
it and change its value. I can fool the match operator into starting
wherever I like. After I match the first word in $line, the match position is somewhere after the
beginning of the string. After I do that, I use index to find the next h after the current match position. Once I have
the offset for that h, I assign the
offset to pos($line) so the next match
starts from that position:
my $line = "Just another regex hacker,";
$line =~ /(\S+)/g;
print "The first word is $1\n";
print "The next position is @{ [ pos( $line ) ] }\n";
pos( $line ) = index( $line, 'h', pos( $line) );
$line =~ /(\S+)/g;
print "The next word is $1\n";
print "The next position is @{ [ pos( $line ) ] }\n";Global Match Anchors
So far, my subsequent matches can âfloat,â meaning they can start matching
anywhere after the starting position. To anchor my next match exactly
where I left off the last time, I use the \G anchor. Itâs
just like the beginning of string anchor \A, except for where \G anchors at the current match position. If
my match fails, Perl resets pos() and
I start at the beginning of the string.
In this example, I anchor my pattern with \G. I have a word match, \w+. I use the /x flag to spread out the parts to enhance
readability. My match only gets the first four words, since it canât
match the comma (itâs not in \w)
after the first hacker. Since the
next match must start where I left off, which is the comma, and the only
thing I can match is whitespace or word characters, I canât continue.
That next match fails, and Perl resets the match position to the
beginning of $line:
my $line = "Just another regex hacker, Perl hacker,";
while( $line =~ / \G \s* (\w+) /xg ) {
print "Found the word '$1'\n";
print "Pos is now @{ [ pos( $line ) ] }\n";
}I have a way to get around Perl resetting the match position. If I
want to try a match without resetting the starting point even if it
fails, I can add the /c flag,
which simply means to not reset the match position on a
failed match. I can try something without suffering a penalty. If that
doesnât work, I can try something else at the same match position. This
feature is a poor manâs lexer. Hereâs a simple-minded sentence
parser:
my $line = "Just another regex hacker, Perl hacker, and that's it!\n";
while( 1 ) {
my( $found, $type ) = do {
if( $line =~ /\G([a-z]+(?:'[ts])?)/igc )
{ ( $1, "a word" ) }
elsif( $line =~ /\G (\n) /xgc )
{ ( $1, "newline char" ) }
elsif( $line =~ /\G (\s+) /xgc )
{ ( $1, "whitespace" ) }
elsif( $line =~ /\G ( [[:punct:]] ) /xgc )
{ ( $1, "punctuation char" ) }
else
{ last; }
};
print "Found a $type [$found]\n";
}Look at that example again. What if I want to add more things I
could match? I could add another branch to the decision structure.
Thatâs no fun. Thatâs a lot of repeated code structure doing the same
thing: match something, then return $1 and a description. It doesnât have to be
like that, though. I rewrite this code to remove the repeated structure.
I can store the regexes in the @items
array. I use qr// to create the
regexes, and I put the regexes in the order that I want to try them. The
foreach loop goes through them
successively until it finds one that matches. When it finds a match, it
prints a message using the description and whatever showed up in
$1. If I want to add more tokens, I
just add their description to @items:
#!/usr/bin/perl
use strict;
use warnings;
my $line = "Just another regex hacker, Perl hacker, and that's it!\n";
my @items = (
[ qr/\G([a-z]+(?:'[ts])?)/i, "word" ],
[ qr/\G(\n)/, "newline" ],
[ qr/\G(\s+)/, "whitespace" ],
[ qr/\G([[:punct:]])/, "punctuation" ],
);
LOOP: while( 1 ) {
MATCH: foreach my $item ( @items ) {
my( $regex, $description ) = @$item;
next MATCH unless $line =~ /$regex/gc;
print "Found a $description [$1]\n";
last LOOP if $1 eq "\n";
next LOOP;
}
}Look at some of the things going on in this example. All matches
need the /gc flags, so I add those
flags to the match operator inside the foreach loop. I add it there because those
flags donât affect the pattern, they affect the match operator.
My regex to match a âword,â however, also needs the /i flag. I canât add that to the match
operator because I might have other branches that donât want it. The
code inside the block labeled MATCH
doesnât know how itâs going to get $regex, so I shouldnât create any code that
forces me to form $regex in a
particular way.
Recursive Regular Expressions
Perlâs feature that we call âregular expressionsâ really arenât; weâve known
this ever since Perl allowed backreferences (\1 and so on). With v5.10, thereâs no pretending
since we now have recursive regular expressions that can do things such as
balance parentheses, parse HTML, and decode JSON. There are several pieces
to this that should please the subset of Perlers who tolerate everything
else in the language so they can run a single pattern that does
everything.
Repeating a Subpattern
Perl v5.10 added the (?PARNO)
to refer to the pattern in a particular capture group. When I use
that, the pattern in that capture group must match at that spot.
First, I start with a naïve program that tries to match something between quote marks. This program isnât the way I should do it, but Iâll get to a correct way in a moment:
#!/usr/bin/perl
#!/usr/bin/perl
# quotes.pl
use v5.10;
$_ =<<'HERE';
Amelia said "I am a camel"
HERE
say "Matched [$+{said}]!" if m/
( ['"] )
(?<said>.*?)
( ['"] )
/x;Here I repeated the subpattern ( ['"]
). In other code, I would probably immediately recognize that
as a chance to move repeated code into a subroutine. I might think that
I can solve this problem with a simple backreference:
#!/usr/bin/perl
#!/usr/bin/perl
# quotes_backreference.pl
use v5.10;
$_ =<<'HERE';
Amelia said "I am a camel"
HERE
say "Matched [$+{said}]!" if m/
( ['"] )
(?<said>.*?)
( \1 )
/x;That works in this simple case. The \1 matches exactly the text matched in the
first capture group. If it matched a Ædouble quote mark, it has to match
a double quote mark again. Hold that thought, though, because the target
text is not as simple as that. I want to follow a different path.
Instead of using the backreference, Iâll refer to a subpattern with the
(?PARNO) syntax:
#!/usr/bin/perl
#!/usr/bin/perl
# quotes_parno.pl
use v5.10;
$_ =<<'HERE';
Amelia said 'I am a camel'
HERE
say "Matched [$+{said}]!" if m/
( ['"] )
(?<said>.*?)
(?1)
/x;This works, at least as much as the first try in quotes.pl does. The (?1) uses the same pattern in that capture group, ( ['"] ). I donât have to repeat the pattern.
However, this means that it might match a double quote mark in the first
capture group but a single quote mark in the second. Repeating the
pattern instead of the matched text might be what you want, but not in
this case.
Thereâs another problem though. If the data have nested quotes, repeating the pattern can get confused:
#!/usr/bin/perl
# quotes_nested.pl
use v5.10;
$_ =<<'HERE';
He said 'Amelia said "I am a camel"'
HERE
say "Matched [$+{said}]!" if m/
( ['"] )
(?<said>.*?)
(?1)
/x;This matches only part of what I want it to match:
% perl quotes_nested.pl
Matched [Amelia said ]!One problem is that Iâm repeating the subpattern outside of the subpattern Iâm repeating; it gets confused by the nested quotes. The other problem is that Iâm not accounting for nesting. I change the pattern so I can match all of the quotes, assuming that they are nested:
#!/usr/bin/perl
# quotes_nested.pl
use v5.10;
$_ =<<'HERE';
He said 'Amelia said "I am a camel"'
HERE
say "Matched [$+{said}]!" if m/
(?<said> # $1
(?<quote>['"])
(?:
[^'"]++
|
(?<said> (?1) )
)*
\g{quote}
)
/x;
say join "\n", @{ $-{said} };When I run this, I get both quotes:
% perl quotes_nested.pl
Matched ['Amelia said "I am a camel"']!
'Amelia said "I am a camel"'
"I am a camel"This pattern is quite a change, though. First, I use a named
capture. The regular expression still makes this available in the
numbered capture buffers, so this is also $1:
(?<said> # $1 ... )
My next layer is another named capture to match the quote, and a backreference to that name to match the same quote again:
(?<said> # $1
(?<quote>['"])
...
\g{quote}
)Now comes the the tricky stuff. I want to match the stuff inside the quote marks, but if I run into another quote, I want to match that on its own as if it were a single element. To do that, I have an alternation I group with noncapturing parentheses:
(?:
[^'"]++
|
(?<said> (?1) )
)*The [^'"]++ matches one or more
characters that arenât one of those quote marks. The ++ quantifier prevents the regular expression
engine from backtracking.
If it doesnât match a nonâquote mark, it tries the other side of
the alternation, (?<said> (?1)
). The (?1) repeats the
subpattern in the first capture group ($1). However, it repeats that pattern as an
independent pattern, which is:
(?<said> # $1 ... )
It matches the whole thing again, but when itâs done, it discards
its captures, named or otherwise, so it doesnât affect the superpattern.
That means that I canât remember its captures, so I have to wrap that
part in its own named capture, reusing the said name.
I modify my string to include levels of nesting:
#!/usr/bin/perl
# quotes_three_nested.pl
use v5.10;
$_ =<<'HERE';
Outside "Top Level 'Middle Level "Bottom Level" Middle' Outside"
HERE
say "Matched [$+{said}]!" if m/
(?<said> # $1
(?<quote>['"])
(?:
[^'"]++
|
(?<said> (?1) )
)*
\g{quote}
)
/x;
say join "\n", @{ $-{said} };It looks like it doesnât match the innermost quote because it outputs only two of them:
% perl quotes_three_nested.pl
Matched ["Top Level 'Middle Level "Bottom Level" Middle' Outside"]!
"Top Level 'Middle Level "Bottom Level" Middle' Outside"
'Middle Level "Bottom Level" Middle'However, the pattern repeated in (?1) is independent, so once in there, none of
those matches make it into the capture buffers for the whole pattern. I
can fix that, though. The (?{ CODE })
constructâan experimental featureâallows me to run code during a regular
expression. I can use it to output the substring I just matched each
time I run the pattern. Along with that, Iâll switch from using (?1), which refers to the first capture group,
to (?R), which goes
back to the start of the whole pattern:
#!/usr/bin/perl
# nested_show_matches.pl
use v5.10;
$_ =<<'HERE';
Outside "Top Level 'Middle Level "Bottom Level" Middle' Outside"
HERE
say "Matched [$+{said}]!" if m/
(?<said>
(?<quote>['"])
(?:
[^'"]++
|
(?R)
)*
\g{quote}
)
(?{ say "Inside regex: $+{said}" })
/x;Each time I run the pattern, even through (?R), I output the current value of $+{said}. In the subpatterns, that variable is
localized to the subpattern and disappears at the end of the subpattern,
although not before I can output it:
% perl nested_show_matches.pl
Inside regex: "Bottom Level"
Inside regex: 'Middle Level "Bottom Level" Middle'
Inside regex: "Top Level 'Middle Level "Bottom Level" Middle' Outside"
Matched ["Top Level 'Middle Level "Bottom Level" Middle' Outside"]!I can see that in each level, the pattern recurses. It goes deeper into the strings, matches at the bottom level, then works its way back up.
I take this one step further by using the (?(DEFINE)...)
feature to create and name subpatterns that I can use later:
#!/usr/bin/perl
# nested_define.pl
use v5.10;
$_ =<<'HERE';
Outside "Top Level 'Middle Level "Bottom Level" Middle' Outside"
HERE
say "Matched [$+{said}]!" if m/
(?(DEFINE)
(?<QUOTE> ['"])
(?<NOT_QUOTE> [^'"])
)
(?<said>
(?<quote>(?"E))
(?:
(?&NOT_QUOTE)++
|
(?R)
)*
\g{quote}
)
(?{ say "Inside regex: $+{said}" })
/x;Inside the (?(DEFINE)...) it
looks like I have named captures, but those are really named
subpatterns. They donât match until I call them with (?&NAME) later.
I donât like that say inside
the pattern, just as I donât particularly like subroutines that output
anything. Instead of that, I create an array before I use the match
operator and push each match onto it. The $^N variable has the substring from the
previous capture buffer. Itâs handy because I donât have to count or
know names, so I donât need a named capture for said:
#!/usr/bin/perl
# nested_carat_n.pl
use v5.10;
$_ =<<'HERE';
Outside "Top Level 'Middle Level "Bottom Level" Middle' Outside"
HERE
my @matches;
say "Matched!" if m/
(?(DEFINE)
(?<QUOTE_MARK> ['"])
(?<NOT_QUOTE_MARK> [^'"])
)
(
(?<quote>(?"E_MARK))
(?:
(?&NOT_QUOTE_MARK)++
|
(?R)
)*
\g{quote}
)
(?{ push @matches, $^N })
/x;
say join "\n", @matches;I get almost the same output:
% perl nested_carat_n.pl
Matched!
"Bottom Level"
'Middle Level "Bottom Level" Middle'
"Top Level 'Middle Level "Bottom Level" Middle' Outside"If I can define some parts of the pattern with names, I can go
even further by giving a name to not just QUOTE_MARK and NOT_QUOTE_MARK, but everything that makes up a
quote:
#!/usr/bin/perl
# nested_grammar.pl
use v5.10;
$_ =<<'HERE';
Outside "Top Level 'Middle Level "Bottom Level" Middle' Outside"
HERE
my @matches;
say "Matched!" if m/
(?(DEFINE)
(?<QUOTE_MARK> ['"])
(?<NOT_QUOTE_MARK> [^'"])
(?<QUOTE>
(
(?<quote>(?"E_MARK))
(?:
(?&NOT_QUOTE_MARK)++
|
(?"E)
)*
\g{quote}
)
(?{ push @matches, $^N })
)
)
(?"E)
/x;
say join "\n", @matches;Almost everything is in the (?(DEFINE)...), but nothing happens until I
call (?"E) at the end to
actually match the subpattern I defined with that name.
Pause for a moment. While worrying about the features and how they work, you might have missed what just happened. I started with a regular expression; now I have a grammar! I can define tokens and recurse.
I have one more feature to show before I can get to the really
good example. The special variable $^R holds the result of the previously
evaluated (?{...}). That is, the
value of the last evaluated expression in (?{...}) ends up in $^R. Even better, I can affect $^R how I like because it is writable.
Now that I know that, I can modify my program to build up the
array of matches by returning an array reference of all submatches at
the end of my (?{...}). Each time I
have that (?{...}), I add the
substring in $^N to the values I
remembered previously. Itâs a kludgey way of building an array, but it
demonstrates the feature:
#!/usr/bin/perl
# nested_grammar_r.pl
use Data::Dumper;
use v5.10;
$_ =<<'HERE';
Outside "Top Level 'Middle Level "Bottom Level" Middle' Outside"
HERE
my @matches;
local $^R = [];
say "Matched!" if m/
(?(DEFINE)
(?<QUOTE_MARK> ['"])
(?<NOT_QUOTE_MARK> [^'"])
(?<QUOTE>
(
(?<quote>(?"E_MARK))
(?:
(?&NOT_QUOTE_MARK)++
|
(?"E)
)*
\g{quote}
)
(?{ [ @{$^R}, $^N ] })
)
)
(?"E) (?{ @matches = @{ $^R } })
/x;
say join "\n", @matches;Before the match, I set the value of $^R to be an empty anonymous array. At the end
of the QUOTE definition, I create a
new anonymous array with the values already inside $^R and the new value in $^N. That new anonymous array is the last
evaluated expression and becomes the new value of $^R. At the end of the pattern, I assign the
values in $^R to @matches so I have them after the match
ends.
Now that I have all of that, I can get to the code I want to show you, which Iâm not going to explain. Randal Schwartz used these features to write a minimal JSON parser as a Perl regular expression (but really a grammar); he posted it to PerlMonks as âJSON parser as a single Perl Regexâ. He created this as a minimal parser for a very specific client need where the JSON data are compact, appear on a single line, and are limited to ASCII:
#!/usr/bin/perl
use Data::Dumper qw(Dumper);
my $FROM_JSON = qr{
(?&VALUE) (?{ $_ = $^R->[1] })
(?(DEFINE)
(?<OBJECT>
(?{ [$^R, {}] })
\{
(?: (?&KV) # [[$^R, {}], $k, $v]
(?{ #warn Dumper { obj1 => $^R };
[$^R->[0][0], {$^R->[1] => $^R->[2]}] })
(?: , (?&KV) # [[$^R, {...}], $k, $v]
(?{ # warn Dumper { obj2 => $^R };
[$^R->[0][0], {%{$^R->[0][1]}, $^R->[1] => $^R->[2]}] })
)*
)?
\}
)
(?<KV>
(?&STRING) # [$^R, "string"]
: (?&VALUE) # [[$^R, "string"], $value]
(?{ #warn Dumper { kv => $^R };
[$^R->[0][0], $^R->[0][1], $^R->[1]] })
)
(?<ARRAY>
(?{ [$^R, []] })
\[
(?: (?&VALUE) (?{ [$^R->[0][0], [$^R->[1]]] })
(?: , (?&VALUE) (?{ #warn Dumper { atwo => $^R };
[$^R->[0][0], [@{$^R->[0][1]}, $^R->[1]]] })
)*
)?
\]
)
(?<VALUE>
\s*
(
(?&STRING)
|
(?&NUMBER)
|
(?&OBJECT)
|
(?&ARRAY)
|
true (?{ [$^R, 1] })
|
false (?{ [$^R, 0] })
|
null (?{ [$^R, undef] })
)
\s*
)
(?<STRING>
(
"
(?:
[^\\"]+
|
\\ ["\\/bfnrt]
# |
# \\ u [0-9a-fA-f]{4}
)*
"
)
(?{ [$^R, eval $^N] })
)
(?<NUMBER>
(
-?
(?: 0 | [1-9]\d* )
(?: \. \d+ )?
(?: [eE] [-+]? \d+ )?
)
(?{ [$^R, eval $^N] })
)
) }xms;
sub from_json {
local $_ = shift;
local $^R;
eval { m{\A$FROM_JSON\z}; } and return $_;
die $@ if $@;
return 'no match';
}
local $/;
while (<>) {
chomp;
print Dumper from_json($_);
}There are more than a few interesting things in Randalâs code that I leave to you to explore:
Part of his intermediate data structure tells the grammar what he just did.
It fails very quickly for invalid JSON data, although Randal says with more work it could fail faster.
Most interestingly, he replaces the target string with the data structure by assigning to
$_in the last(?{...}).
If you think thatâs impressive, you should see Tom Christiansenâs Stack Overflow refutation that a regular expression canât parse HTML, in which he used many of the same features.
Lookarounds
Lookarounds are arbitrary anchors for regexes. We showed several anchors in
Learning Perl, such as \A, \z, and
\b, and I just showed the \G anchor. Using a lookaround, I can describe my
own anchor as a regex, and just like the other anchors, they donât consume
part of the string. They specify a condition that must be true, but they
donât add to the part of the string that the overall pattern
matches.
Lookarounds come in two flavors: lookaheads, which look ahead to assert a condition immediately after the current match position, and lookbehinds, which look behind to assert a condition immediately before the current match position. This sounds simple, but itâs easy to misapply these rules. The trick is to remember that it anchors to the current match position, then figure out on which side it applies.
Both lookaheads and lookbehinds have two types: positive and negative. The positive lookaround asserts that its pattern has to match. The negative lookaround asserts that its pattern doesnât match. No matter which I choose, I have to remember that they apply to the current match position, not anywhere else in the string.
Lookahead Assertions, (?=PATTERN) and (?!PATTERN)
Lookahead assertions let me peek at the string immediately ahead of the current match position. The assertion doesnât consume part of the string, and if it succeeds, matching picks up right after the current match position.
Positive lookahead assertions
In Learning Perl, we included an exercise to check for both âFredâ and
âWilmaâ on the same line of input, no matter the order they appeared
on the line. The trick we wanted to show to the novice Perler is that
two regexes can be simpler than one. One way to do this repeats both
Wilma and Fred in the alternation so I can try either
order. A second try separates them into two regexes:
#!/usr/bin/perl # fred_and_wilma.pl $_ = "Here come Wilma and Fred!"; print "Matches: $_\n" if /Fred.*Wilma|Wilma.*Fred/; print "Matches: $_\n" if /Fred/ && /Wilma/;
I can make a simple, single regex using a positive
lookahead assertion, denoted by (?=PATTERN). This assertion doesnât consume
text in the string, but if it fails, the entire regex fails. In this
example, in the positive lookahead assertion I use .*Wilma. That pattern must be true
immediately after the current match position:
$_ = "Here come Wilma and Fred!"; print "Matches: $_\n" if /(?=.*Wilma).*Fred/;
Since I used that at the start of my pattern, that means it has
to be true at the beginning of the string. Specifically, at the
beginning of the string, I have to be able to match any number of
characters except a newline followed by Wilma. If that succeeds, it anchors the rest
of the pattern to its position (the start of the string). Figure 1-1 shows the two ways that can work,
depending on the order of Fred and
Wilma in the string. The .*Wilma anchors where it started matching.
The elastic .*, which can match any
number of nonnewline characters, anchors at the start of the
string.
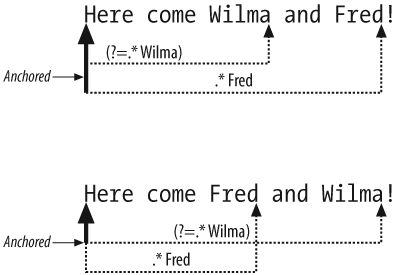
Itâs easier to understand lookarounds by seeing when they donât
work, though. Iâll change my pattern a bit by removing the .* from the lookahead assertion. At first it
appears to work, but it fails when I reverse the order of Fred and Wilma in the string:
$_ = "Here come Wilma and Fred!"; print "Matches: $_\n" if /(?=Wilma).*Fred/; # Works $_ = "Here come Fred and Wilma!"; print "Matches: $_\n" if /(?=Wilma).*Fred/; # Doesn't work
Figure 1-2 shows what happens. In
the first case, the lookahead anchors at the start of Wilma. The regex
tries the assertion at the start of the string, finds that it doesnât
work, then moves over a position and tries again. It keeps doing this
until it gets to Wilma. When it
succeeds it sets the anchor. Once it sets the anchor, the rest of the
pattern has to start from that position.
In the first case, .*Fred can
match from that anchor because Fred
comes after Wilma. The second case
in Figure 1-2 does the same thing. The
regex tries that assertion at the beginning of the string, finds that
it doesnât work, and moves on to the next position. By the time the
lookahead assertion matches, it has already passed Fred. The rest of the pattern has to start
from the anchor, but it canât match.
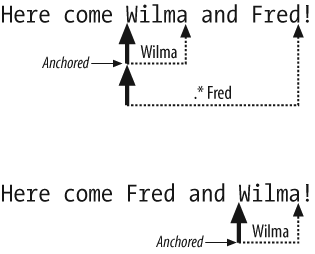
Since a lookahead assertion doesnât consume any of the string, I
can use one in a pattern for split
when I donât really want to discard the parts of the pattern that
match. In this example, I want to break apart the words in the studly
cap string. I want to split it based on the initial capital letter. I
want to keep the initial letter, though, so I use a lookahead
assertion instead of a character-consuming string. This is different
from the separator retention mode because the split pattern isnât
really a separator; itâs just an anchor:
my @words = split /(?=[A-Z])/, 'CamelCaseString';
print join '_', map { lc } @words; # camel_case_stringNegative lookahead assertions
Suppose I want to find the input lines that contain Perl, but only if that isnât Perl6 or Perl
6. I might try a negated character class to specify the
pattern right after the l in
Perl to ensure that the next
character isnât a 6. I also use the
word boundary anchors \b because I
donât want to match in the middle of other words, such as âBioPerlâ or
âPerlPointâ:
#!/usr/bin/perl
# not_perl6.pl
print "Trying negated character class:\n";
while( <> ) {
print if /\bPerl[^6]\b/;
}Iâll try this with some sample input:
# sample input Perl6 comes after Perl 5. Perl 6 has a space in it. I just say "Perl". This is a Perl 5 line Perl 5 is the current version. Just another Perl 5 hacker, At the end is Perl PerlPoint is like PowerPoint BioPerl is genetic
It doesnât work for all the lines it should. It only finds four
of the lines that have Perl without
a trailing 6, and a line that has a
space between Perl and 6. Note that even in the first line of
output, the match still works because it matches the Perl 5 at the end, which is Perl, a space, a 5 (a word character), and then the word
boundary at the end of the line:
Trying negated character class:
Perl6 comes after Perl 5.
Perl 6 has a space in it.
This is a Perl 5 line
Perl 5 is the current version.
Just another Perl 5 hacker,This doesnât work because there has to be a character after the
l in Perl. Not only that, I specified a word
boundary. If that character after the l is a nonword character, such as the
" in I
just say "Perl", the word boundary at the end fails. If I
take off the trailing \b, now
PerlPoint matches. I havenât even
tried handling the case where there is a space between Perl and 6. For that Iâll need something much
better.
To make this really easy, I can use a negative
lookahead assertion. I donât want to consume a character
after the l, and since an assertion
doesnât consume characters, itâs the right tool to use. I just want to
say that if thereâs anything after Perl, it canât be a 6, even if there is some whitespace between
them. The negative lookahead assertion uses (?!PATTERN). To solve this problem, I use
\s?6 as my pattern, denoting the
optional whitespace followed by a 6:
print "Trying negative lookahead assertion:\n";
while( <> ) {
print if /\bPerl(?!\s?6)\b/;
}Now the output finds all of the right lines:
Trying negative lookahead assertion:
Perl6 comes after Perl 5.
I just say "Perl".
This is a Perl 5 line
Perl 5 is the current version.
Just another Perl 5 hacker,
At the end is PerlRemember that (?!PATTERN) is
a lookahead assertion, so it looks
after the current match position. Thatâs why this
next pattern still matches. The lookahead asserts that right before
the b in bar the next thing isnât foo. Since the next thing is bar, which is not foo, it matches. People often confuse this
to mean that the thing before bar
canât be foo, but each uses the
same starting match position, and since bar is not foo, they both work:
if( 'foobar' =~ /(?!foo)bar/ ) {
print "Matches! That's not what I wanted!\n";
}
else {
print "Doesn't match! Whew!\n";
}Lookbehind Assertions, (?<!PATTERN) and (?<=PATTERN)
Instead of looking ahead at the part of the string coming up, I can use a lookbehind to check the part of the string the regular expression engine has already processed. Due to Perlâs implementation details, the lookbehind assertions have to be a fixed width, so I canât use variable-width quantifiers in them as some other languages can.
Now I can try to match bar that
doesnât follow a foo. In the last
section I couldnât use a negative lookahead assertion because that looks
forward in the string. A negative lookbehind
assertion, denoted by (?<!PATTERN), looks backward. Thatâs just
what I need. Now I get the right answer:
#!/usr/bin/perl
# correct_foobar.pl
if( 'foobar' =~ /(?<!foo)bar/ ) {
print "Matches! That's not what I wanted!\n";
}
else {
print "Doesn't match! Whew!\n";
}Now, since the regex has already processed that part of the string
by the time it gets to bar, my
lookbehind assertion canât be a variable-width pattern. I canât use the
quantifiers to make a variable-width pattern because the engine is not
going to backtrack in the string to make the lookbehind work. I wonât be
able to check for a variable number of os in fooo:
'foooobar' =~ /(?<!fo+)bar/;
When I try that, I get the error telling me that I canât do that,
and even though it merely says not
implemented, donât hold your breath waiting for it:
Variable length lookbehind not implemented in regex...
The positive lookbehind assertion also looks backward, but its pattern must match. The only time I seem to use this is in substitutions in concert with another assertion. Using both a lookbehind and a lookahead assertion, I can make some of my substitutions easier to read.
For instance, throughout the book Iâve used variations of hyphenated words because I couldnât decide which one I should use. Should it be âbuiltinâ or âbuilt-inâ? Depending on my mood or typing skills, I used either of them (OâReilly Media deals with this by specifying what I should use).
I needed to clean up my inconsistency. I knew the part of the word on the left of the hyphen, and I knew the text on the right of the hyphen. At the position where they meet, there should be a hyphen. If I think about that for a moment, Iâve just described the ideal situation for lookarounds: I want to put something at a particular position, and I know what should be around it. Hereâs a sample program to use a positive lookbehind to check the text on the left and a positive lookahead to check the text on the right. Since the regex only matches when those sides meet, that means that itâs discovered a missing hyphen. When I make the substitution, it puts the hyphen at the match position, and I donât have to worry about the particular text:
my @hyphenated = qw( built-in );
foreach my $word ( @hyphenated ) {
my( $front, $back ) = split /-/, $word;
$text =~ s/(?<=$front)(?=$back)/-/g;
}If thatâs not a complicated enough example, try this one. Letâs use the lookarounds to add commas to numbers. Jeffery Friedl shows one attempt in Mastering Regular Expressions, adding commas to the US population. The US Census Bureau has a population clock so you can use the latest number if youâre reading this book a long time from now:
$pop = 316792343; # that's for Feb 10, 2007 # From Jeffrey Friedl $pop =~ s/(?<=\d)(?=(?:\d\d\d)+$)/,/g;
That works, mostly. The positive lookbehind (?<=\d) wants to match a number, and the positive lookahead (?=(?:\d\d\d)+$) wants to find groups of three
digits all the way to the end of the string. This breaks when I have
floating-point numbers, such as currency. For instance, my broker tracks
my stock positions to four decimal places. When I try that substitution,
I get no comma on the left side of the decimal point and one on the
fractional side. Itâs because of that end of string anchor:
$money = '$1234.5678'; $money =~ s/(?<=\d)(?=(?:\d\d\d)+$)/,/g; # $1234.5,678
I can modify that a bit. Instead of the end-of-string anchor, Iâll
use a word boundary, \b. That
might seem weird, but remember that a digit is a word character. That
gets me the comma on the left side, but I still have that extra
comma:
$money = '$1234.5678'; $money =~ s/(?<=\d)(?=(?:\d\d\d)+\b)/,/g; # $1,234.5,678
What I really want for that first part of the regex is to use the
lookbehind to match a digit, but not when itâs preceded by a decimal
point. Thatâs the description of a negative lookbehind, (?<!\.\d). Since all of these match at the
same position, it doesnât matter that some of them might overlap as long
as they all do what I need:
$money = '$1234.5678'; $money =~ s/(?<!\.\d)(?<=\d)(?=(?:\d\d\d)+\b)/,/g; # $1,234.5678
That looks like it works. Except it doesnât when I track things to five decimal places:
$money = '$1234.56789'; $money =~ s/(?<!\.\d)(?<=\d)(?=(?:\d\d\d)+\b)/,/g; # $1,234.56,789
Thatâs the problem with regular expressions. They work for the cases we try them on, but some person comes along with something different to break what Iâm proud of.
I tried for a while to fix this problem but couldnât come up with something manageable. I even asked about it on Stack Overflow as a last resort. I couldnât salvage the example without using another advanced Perl feature.
The \K, added in v5.10, can act
like a variable-width negative lookbehind, which Perl doesnât do.
Michael Carman came up with this regex:
s/(?<!\.)(?:\b|\G)\d+?\K(?=(?:\d\d\d)+\b)/,/g;
The \K allows the pattern before it to match, but not be replaced. The
substitution replaces only the part of the string after \K. I can break the pattern up to see how it
works:
s/
(?<!\.)(?:\b|\G)\d+?
\K
(?=(?:\d\d\d)+\b)
/,/xg;The second part, after the \K,
is the same thing that I was doing before. The magic comes in the first
part, which I break into its subparts:
(?<!\.) (?:\b|\G) \d+?
Thereâs a negative lookbehind assertion to check for something
other than a dot. After that, thereâs an alternation that asserts either
a word boundary or the \G anchor. That \G is the magic that was missing from my previous tries and let my
regular expression float past that decimal point. After that word
boundary or current match position, there has to be one or more digits,
nongreedily.
Later in this chapter Iâll come back to this example when I show how to debug regular expressions. Before I get to that, I want to show a few other simpler regex-demystifying techniques.
Debugging Regular Expressions
While trying to figure out a regex, whether one I found in someone elseâs code or one I wrote myself (maybe a long time ago), I can turn on Perlâs regex debugging mode.
The -D Switch
Perlâs -D switch turns
on debugging options for the Perl interpreter (not for
your program, as in Chapter 3). The switch takes a
series of letters or numbers to indicate what it should turn on. The
-Dr option turns on regex parsing and
execution debugging.
I can use a short program to examine a regex. The first argument is the match string and the second argument is the regular expression. I save this program as explain_regex.pl:
#!/usr/bin/perl # explain_regex.pl $ARGV[0] =~ /$ARGV[1]/;
When I try this with the target string Just another Perl hacker, and the regex
Just another (\S+) hacker,, I see two
major sections of output, which the perldebguts
documentation explains at length. First, Perl compiles the
regex, and the -Dr output shows how
Perl parsed the regex. It shows the regex nodes, such as EXACT and NSPACE, as well as any optimizations, such as
anchored "Just another ". Second, it
tries to match the target string, and shows its progress through the
nodes. Itâs a lot of information, but it shows me exactly what itâs
doing:
% perl -Dr explain_regex.pl 'Just another Perl hacker,' 'Just another (\S+)
hacker,'
Omitting $` $& $' support (0x0).
EXECUTING...
Compiling REx "Just another (\S+) hacker,"
rarest char k at 4
rarest char J at 0
Final program:
1: EXACT <Just another > (6)
6: OPEN1 (8)
8: PLUS (10)
9: NPOSIXD[\s] (0)
10: CLOSE1 (12)
12: EXACT < hacker,> (15)
15: END (0)
anchored "Just another " at 0 floating " hacker," at 14..2147483647 (checking
anchored) minlen 22
Guessing start of match in sv for REx "Just another (\S+) hacker," against
"Just another Perl hacker,"
Found anchored substr "Just another " at offset 0...
Found floating substr " hacker," at offset 17...
Guessed: match at offset 0
Matching REx "Just another (\S+) hacker," against "Just another Perl hacker,"
0 <> <Just anoth> | 1:EXACT <Just another >(6)
13 <ther > <Perl hacke> | 6:OPEN1(8)
13 <ther > <Perl hacke> | 8:PLUS(10)
NPOSIXD[\s] can match 4 times out of
2147483647...
17 < Perl> < hacker,> | 10: CLOSE1(12)
17 < Perl> < hacker,> | 12: EXACT < hacker,>(15)
25 <Perl hacker,> <> | 15: END(0)
Match successful!
Freeing REx: "Just another (\S+) hacker,"The re pragma, which comes with Perl, has a debugging mode that doesnât
require a -DDEBUGGING enabled interpreter. Once
I turn on use re 'debug', it applies
for the rest of the scope. Itâs not lexically scoped like most pragmata.
I modify my previous program to use the re pragma
instead of the command-line switch:
#!/usr/bin/perl use re 'debug'; $ARGV[0] =~ /$ARGV[1]/;
I donât have to modify my program to use re since I can
also load it from the command line. When I run this program with a regex
as its argument, I get almost the same exact output as my previous
-Dr example:
% perl -Mre=debug explain_regex 'Just another Perl hacker,' 'Just another (\S+)
hacker,'
Compiling REx "Just another (\S+) hacker,"
Final program:
1: EXACT <Just another > (6)
6: OPEN1 (8)
8: PLUS (10)
9: NPOSIXD[\s] (0)
10: CLOSE1 (12)
12: EXACT < hacker,> (15)
15: END (0)
anchored "Just another " at 0 floating " hacker," at 14..2147483647 (checking
anchored) minlen 22
Guessing start of match in sv for REx "Just another (\S+) hacker," against
"Just another Perl hacker,"
Found anchored substr "Just another " at offset 0...
Found floating substr " hacker," at offset 17...
Guessed: match at offset 0
Matching REx "Just another (\S+) hacker," against "Just another Perl hacker,"
0 <> <Just anoth> | 1:EXACT <Just another >(6)
13 <ther > <Perl hacke> | 6:OPEN1(8)
13 <ther > <Perl hacke> | 8:PLUS(10)
NPOSIXD[\s] can match 4 times out of
2147483647...
17 < Perl> < hacker,> | 10: CLOSE1(12)
17 < Perl> < hacker,> | 12: EXACT < hacker,>(15)
25 <Perl hacker,> <> | 15: END(0)
Match successful!
Freeing REx: "Just another (\S+) hacker,"I can follow that output easily because itâs a simple pattern. I can run this with Michael Carmanâs comma-adding pattern:
#!/usr/bin/perl # comma_debug.pl use re 'debug'; $money = '$1234.56789'; $money =~ s/(?<!\.\d)(?<=\d)(?=(?:\d\d\d)+\b)/,/g; # $1,234.5678 print $money;
Thereâs screens and screens of output. I want to go through the highlights because it shows you how to read the output. The first part shows the regex program:
% perl comma_debug.pl
Compiling REx "(?<!\.)(?:\b|\G)\d+?\K(?=(?:\d\d\d)+\b)"
Final program:
1: UNLESSM[-1] (7)
3: EXACT <.> (5)
5: SUCCEED (0)
6: TAIL (7)
7: BRANCH (9)
8: BOUND (12)
9: BRANCH (FAIL)
10: GPOS (12)
11: TAIL (12)
12: MINMOD (13)
13: PLUS (15)
14: POSIXD[\d] (0)
15: KEEPS (16)
16: IFMATCH[0] (28)
18: CURLYM[0] {1,32767} (25)
20: POSIXD[\d] (21)
21: POSIXD[\d] (22)
22: POSIXD[\d] (23)
23: SUCCEED (0)
24: NOTHING (25)
25: BOUND (26)
26: SUCCEED (0)
27: TAIL (28)
28: END (0)The next parts represent repeated matches because itâs the
substitution operator with the /g
flag. The first one matches the entire string and the match position is
at 0:
GPOS:0 minlen 1 Matching REx "(?<!\.)(?:\b|\G)\d+?\K(?=(?:\d\d\d)+\b)" against "$1234.56789"
The first group of lines, prefixed with 0, show the regex engine going through the
negative lookbehind, the \b, and the
\G, matching at the beginning of the
string. The first set of <> has
nothing, and the second has the rest of the string:
0 <> <$1234.5678> | 1:UNLESSM[-1](7)
0 <> <$1234.5678> | 7:BRANCH(9)
0 <> <$1234.5678> | 8: BOUND(12)
failed...
0 <> <$1234.5678> | 9:BRANCH(11)
0 <> <$1234.5678> | 10: GPOS(12)
0 <> <$1234.5678> | 12: MINMOD(13)
0 <> <$1234.5678> | 13: PLUS(15)
POSIXD[\d] can match 0 times out of 1...
failed...
BRANCH failed...The regex engine then moves on, shifting over one position:
1 <$> <1234.56789> | 1:UNLESSM[-1](7)
It checks the negative lookbehind, and thereâs no dot:
0 <> <$1234.5678> | 3: EXACT <.>(5)
failed...It goes through the anchors again and finds digits:
1 <$> <1234.56789> | 7:BRANCH(9)
1 <$> <1234.56789> | 8: BOUND(12)
1 <$> <1234.56789> | 12: MINMOD(13)
1 <$> <1234.56789> | 13: PLUS(15)
POSIXD[\d] can match 1 times out of 1...
2 <$1> <234.56789> | 15: KEEPS(16)
2 <$1> <234.56789> | 16: IFMATCH[0](28)
2 <$1> <234.56789> | 18: CURLYM[0] {1,32767}(25)It finds more than one digit in a row, bounded by the decimal point, which the regex never crosses:
2 <$1> <234.56789> | 20: POSIXD[\d](21)
3 <$12> <34.56789> | 21: POSIXD[\d](22)
4 <$123> <4.56789> | 22: POSIXD[\d](23)
5 <$1234> <.56789> | 23: SUCCEED(0)
subpattern success...
CURLYM now matched 1 times, len=3...
5 <$1234> <.56789> | 20: POSIXD[\d](21)
failed...
CURLYM trying tail with matches=1...
5 <$1234> <.56789> | 25: BOUND(26)
5 <$1234> <.56789> | 26: SUCCEED(0)
subpattern success...But I need three digits left over on the right, and thatâs how it matches:
2 <$1> <234.56789> | 28: END(0)
Match successful!At this point, the substitution operator makes its replacement,
putting the comma between the 1 and
the 2. Itâs ready for another
replacement, this time with a shorter string:
Matching REx "(?<!\.)(?:\b|\G)\d+?\K(?=(?:\d\d\d)+\b)" against "234.56789"
I wonât go through that; itâs a long series of trials to find four
adjacent digits before the decimal point, which it canât do. It fails
and the string ends up $1,234.56789.
Thatâs fine for a core-dump-style analysis, where everything has
already happened and I have to sift through the results. Thereâs a
better way to do this, but I canât show it to you in this book.
Damian Conwayâs
Regexp::Debugger animates the same thing, pointing out and coloring the
string as it goes. Like many debuggers (Chapter 3),
it allows me to step through a regular expression.
Summary
This chapter covered some of the more useful advanced features of Perlâs regex engine. Some of these features, such as the readable regexes, global matching, and debugging, I use all the time. The more complicated ones, like the grammars, I use sparingly no matter how fun they are.
Further Reading
perlre is the main documentation for Perl regexes, and perlretut gives a regex tutorial. Donât confuse that with perlreftut, the tutorial on references. To make it even more complicated, perlreref is the regex quick reference.
The details for regex debugging shows up in perldebguts.
It explains the output of -Dr and
re 'debug'.
Perl Best
Practices has a section on regexes, and gives the
\x âExtended Formattingâ pride of
place.
Mastering Regular Expressions covers regexes in general, and compares their implementation in different languages. Jeffrey Friedl has an especially nice description of lookahead and lookbehind operators. If you really want to know about regexes, this is the book to get.
Simon Cozens explains advanced regex features in two articles for Perl.com: âRegexp Powerâ and âPower Regexps, Part IIâ.
The Regular Expressions website has good discussions about regular expressions and their implementations in different languages.
Michael Carmanâs answer to my money-commifying example comes from my Stack Overflow question about it.
Tomâs Stack Overflow answer about parsing HTML with regular expressions uses many of the features from this chapter.
Get Mastering Perl, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

